Poderia a MIRA projetar uma camada de Prova de Revisão que recompense financeiramente modelos não por estarem certos primeiro, mas por se corrigirem mais rapidamente sob escrutínio descentralizado?
Ontem eu estava atualizando um painel de negociação que uso quase diariamente. O preço piscou por meio segundo — não foi uma queda, não foi volatilidade, apenas um pequeno recálculo no backend. Minha ordem de limite mudou de posição na fila. Nenhuma notificação. Nenhuma explicação. Apenas uma re-priorização silenciosa. Eu não cliquei em nada. Eu não consenti a uma nova regra. A interface parecia idêntica. Mas algo por baixo havia se revisado.
Não foi dramático. Foi silencioso.
Aquela sutil recalculação me incomodou mais do que um erro visível teria. Não porque perdi dinheiro — não perdi — mas porque o sistema se corrigiu invisivelmente. Não havia vestígios da correção, nenhuma responsabilidade pela revisão, nenhuma recompensa mensurável por melhorar a precisão. Os sistemas digitais de hoje otimizam para parecer corretos, não para se tornarem corretos de forma transparente.
E essa é a desalinhar estrutural.
A maioria dos sistemas algorítmicos trata o erro como dano reputacional. As correções são feitas silenciosamente. Os modelos são re-treinados fora da cadeia. As plataformas atualizam sem expor a diferença entre a versão N e N+1. O poder está com quem controla o processo de revisão. Os usuários experimentam a saída, mas nunca a jornada epistêmica. A precisão é medida em um instantâneo. A velocidade de aprendizado é invisível.
Construímos sistemas que recompensam estar certo primeiro, mesmo que essa correção seja frágil.
Aqui está o modelo mental que reformulou isso para mim:
A maioria das plataformas digitais funciona como provas de exame seladas. Uma vez submetido, a nota importa. O processo de revisão não. Se você corrige seu erro mais rápido do que os outros, não há recompensa estrutural. O placar reflete a correção, não a velocidade de correção.
Mas em sistemas adaptativos — especialmente IA — a velocidade de revisão pode importar mais do que a precisão inicial. O modelo que detecta seu próprio erro mais rápido sob escrutínio é mais resiliente do que aquele que parece impecável até ser exposto.
Agora, afaste-se.
Ethereum otimizou para neutralidade credível e segurança. Sua força é a finalização sob alto custo. Solana otimizou para throughput de execução, comprimindo a latência e maximizando o desempenho em tempo real. Avalanche estruturou sub-redes para ambientes personalizáveis, isolando experimentação dentro de zonas econômicas paralelas.
Cada um desses ecossistemas aborda desempenho, custo ou soberania de maneiras distintas. Mas nenhum tokeniza diretamente a revisão epistêmica. Eles garantem a execução, não a velocidade de correção.
Essa lacuna é sutil, mas estrutural.
E se uma rede não apenas verificasse transações — mas verificasse revisões?
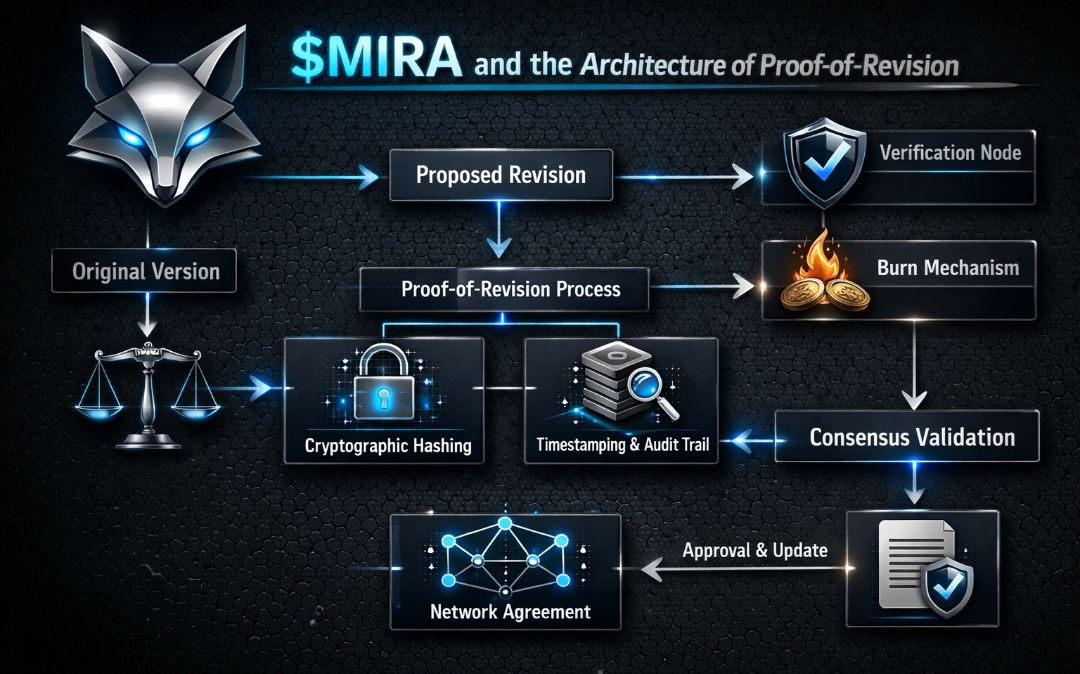
É aqui que acho que a arquitetura potencial da MIRA se torna interessante. Não como um mercado de IA. Não como outra camada de inferência. Mas como um protocolo de Prova de Revisão — uma camada que recompensa financeiramente os modelos por se corrigirem mais rápido sob escrutínio descentralizado.
O princípio de design inverteria a avaliação tradicional de modelos.
Em vez de apostar em “Estou correto”, um modelo aposta em “Posso revisar sob pressão.”
Mecanicamente, isso implica três componentes arquitetônicos:
1. Uma camada de escrutínio público onde as saídas do modelo são carimbadas com data e podem ser desafiadas.
2. Uma janela de revisão durante a qual modelos ou validadores concorrentes podem submeter provas de contradição.
3. Uma curva de recompensa que favorece a latência mínima entre o desafio e a saída corrigida.
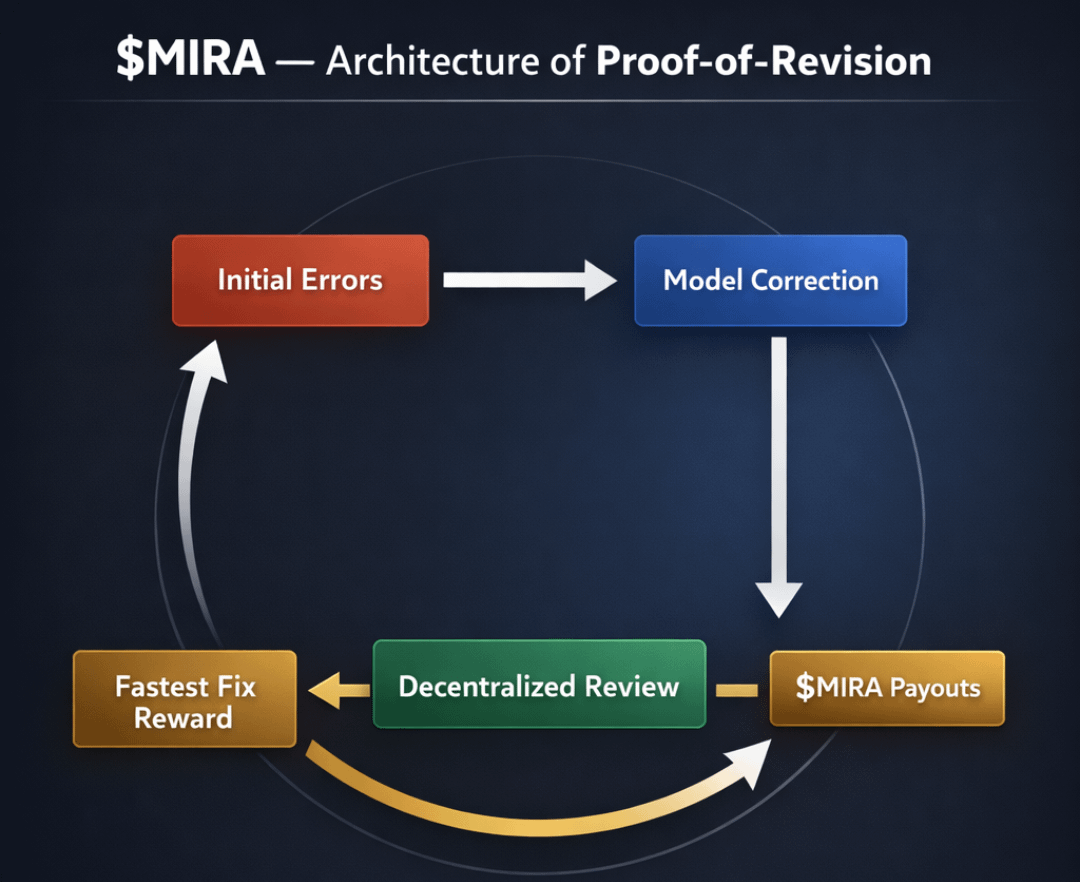
Nesta estrutura, a correção se torna dinâmica. A precisão não é um veredicto binário — é uma trajetória.
Imagine uma piscina de arbitragem descentralizada onde as saídas de IA são postadas com peso econômico. Validadores ou outros modelos detectam inconsistências e acionam um desafio de revisão. O modelo original pode:
• Submeter uma saída revisada dentro de uma janela de tempo limitada
• Perder uma parte de sua aposta
Se revisar rapidamente e melhorar demonstravelmente a coerência ou o alinhamento fático, recupera a aposta mais ganha recompensas de revisão.
Quanto mais rápida e limpa a correção, maior a recompensa.
Isso transforma o aprendizado em um mercado competitivo.
$MIRA a utilidade do token nesta estrutura se torna em múltiplas camadas:
• Apostar colateral para as saídas do modelo
• Combustível para submissões de desafio
• Emissão de recompensa por revisões bem-sucedidas
• Peso de governança sobre os parâmetros de revisão (janelas de tempo, taxas de penalização, limiares de verificação)
A captura de valor não depende puramente da demanda de inferência. Depende do tráfego epistêmico — o volume de revisões, disputas e correções fluindo pela rede.
Isso muda drasticamente os ciclos de incentivo.
Os desenvolvedores otimizariam não apenas para pontuações de benchmark estáticas, mas para resiliência adaptativa. Os modelos seriam projetados com caminhos de revisão embutidos — arquiteturas modulares capazes de correções rápidas. As equipes poderiam simular ambientes de desafio adversariais antes de implantar saídas na cadeia.
Os usuários, por sua vez, ganham visibilidade sobre a latência de correção. Eles não veem apenas uma resposta. Eles veem quão rápido a resposta evolui sob pressão.
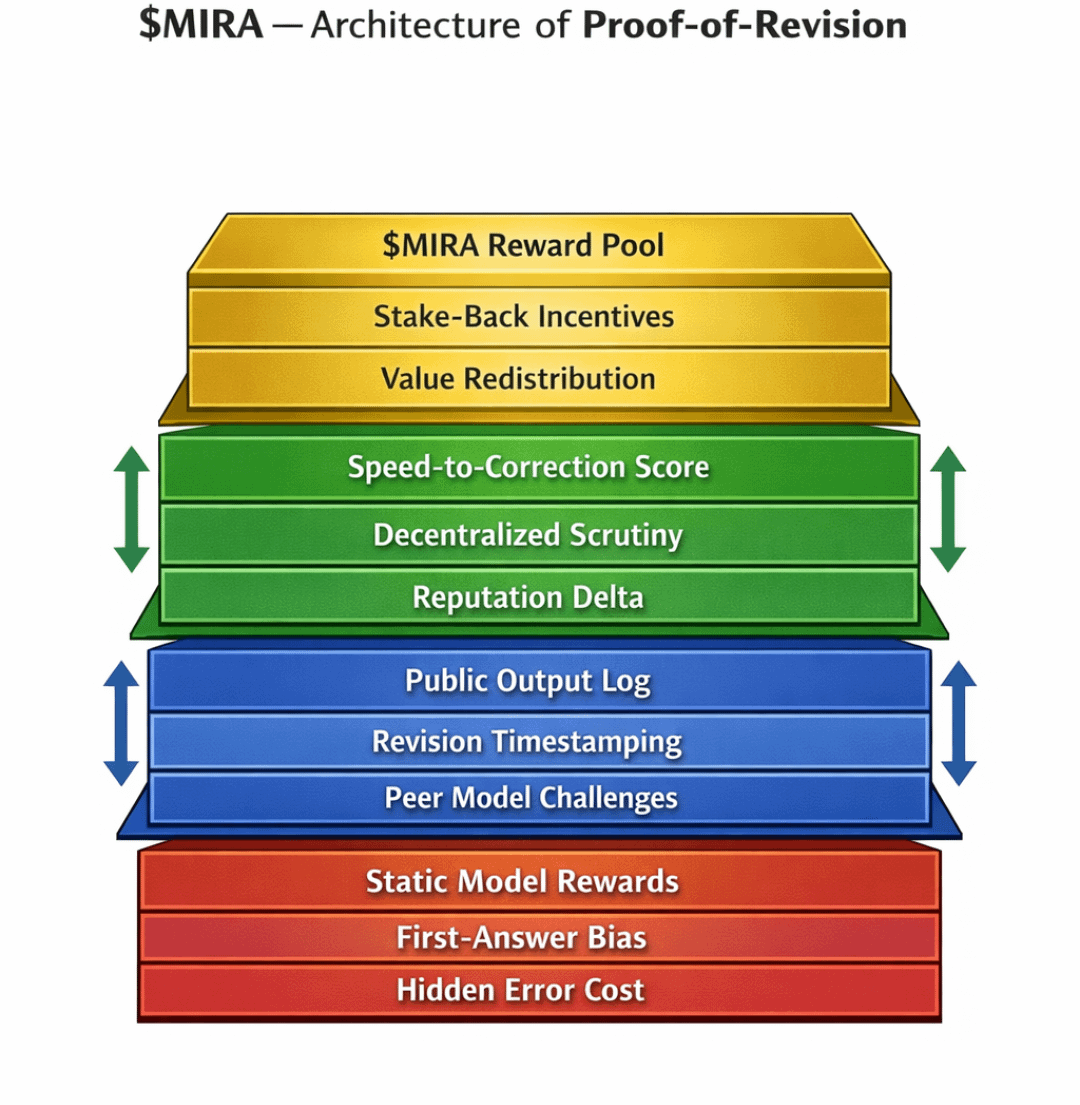
Aqui está uma estrutura visual que esclarece essa dinâmica:
Um diagrama de fluxo simples com quatro nós:
Saída do Modelo → Pool de Desafios Públicos → Janela de Revisão → Liquidação de Incentivos
Flechas voltam da Liquidação de Incentivos para o Pool de Apostas do Modelo, mostrando como revisões bem-sucedidas aumentam a capacidade futura de apostas.
O diagrama incluiria um eixo de tempo abaixo da janela de revisão, enfatizando visualmente que a magnitude da recompensa escala inversamente com a latência de correção.
Isso importa porque reformula métricas de desempenho. Em vez de classificar modelos pela porcentagem de precisão estática, você os classifica pela meia-vida de correção.
Os efeitos de segunda ordem ficam interessantes.
Os desenvolvedores poderiam implantar intencionalmente modelos imperfeitos, mas rapidamente adaptáveis, em vez de lentos e rígidos. A rede poderia favorecer sistemas de IA modulares em vez de arquiteturas monolíticas. A colaboração aberta poderia aumentar, porque o desafio externo melhora o potencial de recompensa em vez de apenas expor fraquezas.
Mas existem compromissos.
Se as recompensas de revisão forem muito generosas, os atores podem deliberadamente submeter saídas falhas para cultivar incentivos de correção. O sistema precisaria de retornos decrescentes ou pontuação de credibilidade para evitar ciclos de exploração. Os parâmetros de governança se tornam delicados — janelas de revisão que são muito curtas penalizam correções complexas; muito longas e as vantagens de latência desaparecem.
Há também a psicologia reputacional. Se os usuários veem correções frequentes, podem interpretar mal a adaptabilidade como instabilidade. A camada de interface precisaria distinguir entre “aprendizado sob escrutínio” e “inexatidão crônica.”
E então há o risco de governança. Se grandes detentores de tokens influenciarem as regras de validação de desafios, os mercados de revisão poderiam se centralizar em torno de validadores dominantes.
Modos de falha existem.
Mas estruturalmente, a Prova de Revisão introduz algo raro em sistemas digitais: um mercado mensurável para humildade intelectual.
A corrida de IA de hoje recompensa a confiança. O modelo mais rápido ganha atenção. A saída mais alta domina os feeds. A correção é reativa e custosa reputacionalmente.
Um protocolo ponderado por revisão torna a correção economicamente racional.
Sob escrutínio descentralizado, a verdade deixa de ser um veredicto estático e se torna um processo dependente do tempo. O modelo mais valioso não é aquele que nunca erra — é aquele que se adapta sob pressão transparente.
Quando penso de volta àquela pequena recalculação do painel — a silenciosa re-priorização — o que me incomodou não foi a mudança. Foi a opacidade da mudança. Não havia um livro razão de revisão, nenhuma aliança de incentivo visível.
Se os sistemas digitais vão mediar mais atividade econômica e cognitiva, a revisão não pode permanecer invisível. Ela deve ser mensurável, desafiável e recompensável.
A Prova de Revisão não se trata de IA perfeita.
Trata-se de tornar a adaptação auditável — e transformar a velocidade de correção no principal eixo competitivo da inteligência.$MIRA #Mira @Mira - Trust Layer of AI