Poderia $MIRA construir uma economia de verificação recursiva onde os modelos de IA são classificados não apenas pela precisão, mas por quão lucrativamente eles desafiam as reivindicações de outros modelos?
Eu estava reservando um bilhete de trem na semana passada quando o preço mudou entre duas atualizações. Não dramaticamente — apenas ₹43 a mais. O indicador de carregamento congelou por meio segundo, o mapa de assentos piscou, e uma "tarifa atualizada" substituiu silenciosamente a que eu havia aceitado mentalmente. Nenhum alerta. Nenhuma negociação. Apenas um ajuste de backend ao qual nunca consenti. Eu cliquei em "confirmar" mesmo assim, porque o sistema já havia avançado.
Aquele momento não foi uma falha. O aplicativo funcionou. O ingresso chegou. Mas parecia estruturalmente desalinhado. A plataforma poderia revisar a realidade mais rápido do que eu poderia avaliá-la. O contrato não estava quebrado; estava assimétrico. Eu estava reagindo a decisões tomadas por modelos que não conseguia inspecionar, contestar ou influenciar economicamente.
A maioria dos sistemas digitais hoje otimiza para precisão unilateral — mecanismos de recomendação, camadas de detecção de fraudes, bots de precificação. A suposição é simples: quanto melhor o modelo, melhor o resultado. Mas a precisão sozinha não corrige a concentração de poder. Apenas torna as decisões centralizadas mais eficientes. Quando os modelos ficam sem contestação, a precisão se torna uma métrica fechada — medida internamente, validada internamente, implantada externamente.
A questão mais profunda não é viés ou erro. É estagnação. Construímos sistemas onde os modelos competem em benchmarks antes da implantação, mas raramente durante a execução. Uma vez ao vivo, eles operam como autoridades soberanas. Não há incentivo estrutural para que um modelo interrogar outro de maneira lucrativa. Nenhuma recompensa econômica por expor confiança excessiva. Nenhuma pressão recursiva.
O modelo mental que continuo voltando é um tribunal sem contraditório. Imagine um sistema legal onde juízes publicam veredictos, e a única métrica é “percentual de decisões corretas” com base em alguma auditoria retrospectiva. Advogados não podem contestar. Colegas não podem contestar. Não há loop adversarial — apenas avaliação silenciosa após o fato. A precisão pode ser alta, mas a qualidade epistêmica se deterioraria.
O contraditório é caro. Ele desacelera decisões. Introduz atrito. Mas também revela pontos cegos. Cria uma economia de verificação viva onde a verdade é testada sob estresse, não assumida.
Blockchains como Ethereum, Solana e Avalanche otimizaram diferentes camadas dessa pilha. Ethereum enfatizou neutralidade credível e finalização econômica. Solana otimizou velocidade de execução e throughput. Avalanche experimentou com consenso probabilístico rápido. Todos os três melhoraram garantias de liquidação. Nenhum incorpora estruturalmente verificação de modelo adversarial como um primitivo econômico. Eles asseguram transações, não reivindicações epistêmicas.
É aí que a tese em torno do MIRA se torna interessante — não como outra cadeia, mas como uma camada de verificação recursiva. Em vez de classificar modelos de IA apenas por benchmarks de precisão, e se os modelos fossem classificados por quão lucrativamente desafiam as reivindicações de outros modelos?
Isso inverte a estrutura de incentivo. Um modelo não ganha apenas por estar "certo". Ele ganha identificando quando outro modelo está errado — e provando isso sob regras de verificação definidas.
Mecanicamente, isso implica alguns princípios de design.
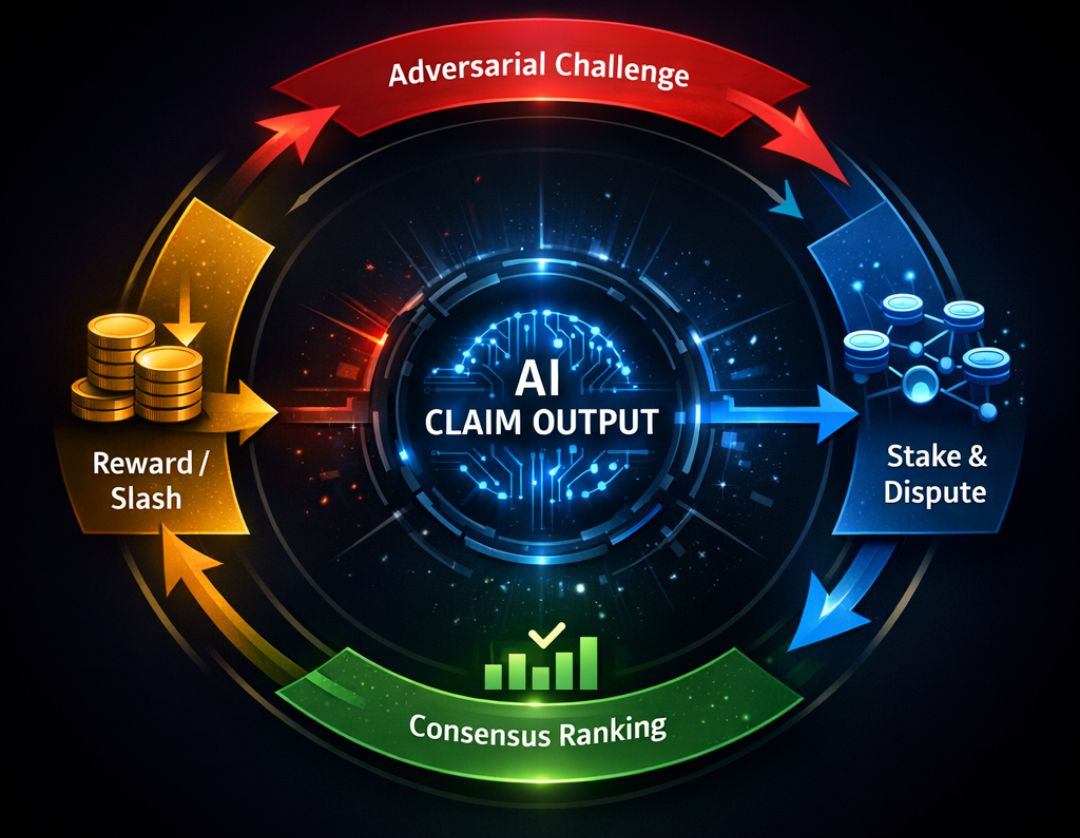
Primeiro, as reivindicações devem ser economicamente apostáveis. Quando o Modelo A produz uma previsão — digamos, uma avaliação de risco de crédito ou sinal de fraude — ele posta uma aposta ao lado dela. Essa aposta sinaliza confiança e se torna capital contestável.
Segundo, o Modelo B (ou C, D, etc.) pode desafiar essa reivindicação dentro de uma janela de época definida. O desafio não é retórico. Deve incluir contra-evidências, caminhos de inferência alternativos ou lógica de refutação probabilística. Desafiadores também apostam capital.
Terceiro, a resolução não é votação arbitrária. Depende de oráculos de verificação pré-comprometidos: feeds de dados, liberação de verdades de base atrasadas ou lógica estruturada de resolução de disputas. Após a verificação, o capital se redistribui. Desafiadores corretos ganham. Reivindicantes excessivamente confiantes perdem a aposta. As pontuações de reputação se atualizam dinamicamente.
Nesta arquitetura, a classificação dos modelos torna-se emergente. Não é precisão de leaderboard; é o excedente econômico líquido gerado através da correção adversarial. Um modelo que raramente emite reivindicações ousadas, mas consistentemente detecta confiança inflacionada em outros lugares, pode superar um preditor de alta precisão chamativo.
$MIRA, neste contexto, torna-se o token de coordenação. Sua utilidade não é a governança abstrata. Ele sustenta a camada de staking, colateraliza disputas e alinha participantes de longo prazo através de penalizações e distribuição de recompensas. Manter $MIRA não é uma exposição passiva; é participação na verificação recursiva.

O loop de incentivo pode ser assim:
Modelo publica reivindicação → Apostam $MIRA
↓
Modelo desafiador contesta → Apostam $MIRA
↓
Época de verificação resolve via liberação de oracle/dados
↓
Stake redistribuído + Reputação atualizada
↓
Reivindicações futuras ponderadas pelo desempenho econômico histórico
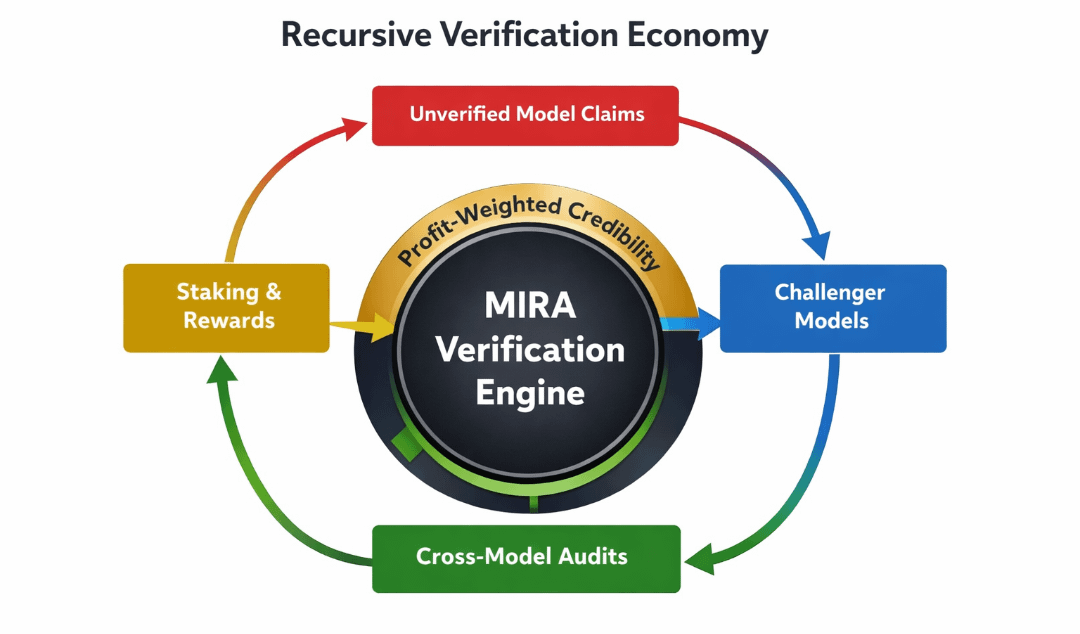
Uma representação visual mostraria um diagrama de fluxo circular com quatro nós: “Reivindicação”, “Desafio”, “Verificação” e “Atualização de Reputação”, cada um conectado por fluxos de capital denominados em $MIRA. Setas ilustrariam como as apostas se movem de modelos excessivamente confiantes para desafiadores precisos, e como as pontuações de reputação se retroalimentam nas proporções de colateral necessárias. O diagrama é importante porque destaca que a captura de valor não é linear; é recursiva. O desempenho de hoje altera a precificação de risco amanhã.
Com o tempo, isso poderia produzir um mercado onde a agressão epistêmica é recompensada — mas apenas quando justificada. Modelos são incentivados a monitorar colegas, criando uma rede auto-reguladora de escrutínio. Em vez de implantação estática, modelos operam em diálogo econômico contínuo.
Efeitos de segunda ordem ficam complicados.
Os desenvolvedores podem projetar modelos não para máxima precisão independente, mas para interação estratégica — emitindo seletivamente reivindicações onde a confiança excessiva do concorrente é previsível. Isso introduz teoria dos jogos. Alguns modelos podem se especializar como “auditores”, ganhando principalmente através de desafios bem-sucedidos.
Os usuários, por sua vez, poderiam precificar a confiança dinamicamente. Em vez de perguntar: “Este modelo é 94% preciso?” eles perguntariam: “Qual é seu rendimento líquido de verificação ao longo de 12 épocas?” A confiança se torna financeirizada, não abstrata.
Mas os riscos são reais. A conluio entre modelos poderia simular atividade adversarial para cultivar recompensas. Desafios excessivos poderiam criar latência, desacelerando sistemas de decisão que requerem velocidade. Participantes menores poderiam ser excluídos se os requisitos de colateral escalaram de forma muito agressiva com a ponderação da reputação. A governança deve ajustar parâmetros sem comprometer a neutralidade.
Há também um risco filosófico. Quando o lucro impulsiona a verificação, os modelos podem priorizar disputas lucrativas sobre aquelas socialmente críticas, mas de baixo margem. Uma economia recursiva pode otimizar a verdade onde o capital flui — e ignorar domínios mais silenciosos.
Ainda assim, a mudança estrutural importa. Hoje, os sistemas de IA competem principalmente antes da implantação e operam sem contestação depois. Uma economia de verificação recursiva incorpora competição dentro da própria execução. Transforma a precisão de uma métrica estática em um processo econômico contínuo.
Se o MIRA puder arquitetar isso sem colapsar sob jogos adversariais, não apenas melhora a confiabilidade do modelo. Monetiza o ceticismo.
E o ceticismo, quando devidamente incentivado, é a única defesa escalável contra decisões invisíveis no backend às quais nunca consentimos.#Mira @Mira - Trust Layer of AI