That night I opened the raw logs and saw a dense stream of in and out events. At first glance it looked like demand was exploding, but on a closer look the rhythm was too consistent to be human. I mapped that moment onto Fogo and decided to focus on one thing only, how it processes noisy data before any number is allowed to become a decision.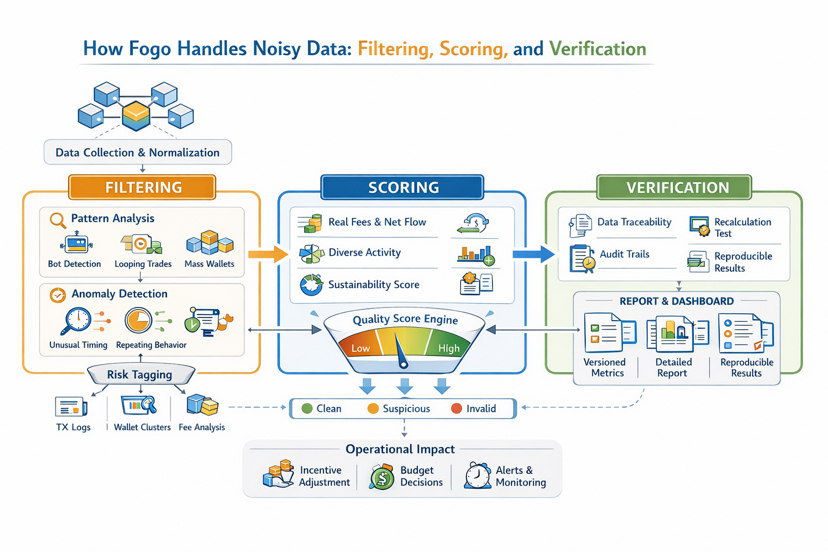
What I need from Fogo is not a “data driven” slogan, but a data system that can be explained end to end. Incoming data must be captured as clearly structured events, for example swaps, bridges, mints, contract calls, and state changes, each with time, address, fees, and success or failure status. Raw data then needs normalization, de duplication, and session level grouping before it ever reaches analytics. If the collection layer is messy, everything downstream becomes self reassurance.
Fogo filtering layer should behave like a quality gate, not a broom that sweeps the surface clean. I want to see clustering based filtering, not just wallet by wallet rules. A cluster can be identified through machine like transaction timing, repeated action sequences, looping trades designed to manufacture volume, batches of newly created wallets doing the same behavior in the same time window, or groups of wallets interacting with only one action type to farm rewards. Good filtering also means risk tagging by levels, so data is not deleted outright but separated into tiers. Clean for health metrics, suspicious for monitoring, and invalid for exclusion from core indicators.
Compared with many projects I have seen, they tend to count everything equally and call that growth, which means whoever can pump the most gets rewarded the most. The approach I expect from Fogo is to treat growth as a signal that must pass validation. Raw data is only input material, while operational metrics should be a finished product that has been cleaned, quality scored, and can be re checked. It looks slower, but it is harder to manipulate.
Filtering only catches the rough noise. The dangerous part is noise that impersonates real users. That is why Fogo scoring must go directly after quality and real economic cost. A serious scoring engine does not reward “having transactions.” It rewards “having value.” I want to see signals such as time based persistence, diversity of actions, real fees paid, breadth of counterparties, ability to generate real revenue for the ecosystem, or contribution to real liquidity rather than simply moving back and forth. The more a signal requires real cost to produce, the more trustworthy the score becomes, and the less attractive metric pumping is.
Scoring never stands still, and that is the part that exhausts builders the most. For Fogo, I expect versioned scoring, change logs, and validation after each update. Every weight adjustment should be paired with drift monitoring, for example which behavior groups spike abnormally and which drop incorrectly, then iterated again. Most importantly, scoring must connect to incentives with discipline. Rewards, perks, or privileges should be based only on the filtered and scored signal set, not on raw activity.
When it comes to verification, I want Fogo to treat scrutiny as the default state. Verification is not “saying it was checked.” It is making re checking possible. Each key metric should have traceable sources, reproducible transformations, and results that can be recalculated to the same number within an acceptable margin. External observers should be able to see where data comes from, which filtering rules were applied, which scoring version was used, what was excluded, and why. An audit trail with metadata for every step turns a report from a dashboard screenshot into a chain of evidence.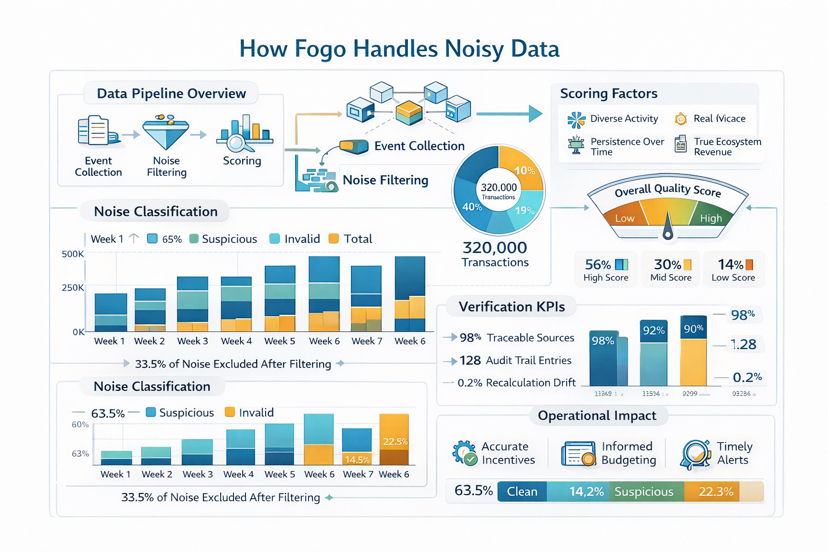
Once those three layers are connected to operations, the real difference appears. Fogo needs an operational dashboard that shows not only metrics, but also metric quality. For example the share of noise excluded over time, newly emerging behavior clusters, concentration of activity within a cluster, and anomaly alerts when metric pumping begins. From there the system can confidently adjust incentives, change reward criteria, cut off reward flow in exploited zones, and shift budgets toward more durable value. That is when data becomes a risk management tool, not just a scoreboard.
In terms of product features, I see Fogo as a machine with several clear blocks. Event ingestion and normalization, cluster based filtering, signal scoring, verification and audit, then decision and incentive distribution. What earns my trust is not storytelling, but the way these blocks force transparency. If the scoring version changes, the report must record it. If filtering rules change, metrics must update accordingly. If something abnormal is forming, the system should detect it before the community invents its own narrative. Ultimately, what matters most is a data system that is hard to pump, hard to mislead, and strict enough to protect itself from noise.
