

O alerta disparou às 2:23 da manhã.
Não é o barulhento. É o quieto. Aquele que significa que algo estrutural mudou, não algo que quebrou.
Eu estava observando a distribuição de participação por seis dias. A zona da América do Norte estava em 94% do limite. Não abaixo. Não acima. Apenas respirando na borda do mínimo que o protocolo exige antes que ative uma zona.
Eu fui dormir pensando que 94% estava bem.
Não estava bem.
Limite de época atingido às 2:19 da manhã. O protocolo executou o filtro de participação. A zona da América do Norte caiu para 91% em algum momento nas quatro horas em que eu não estava assistindo. Três validadores redelegaram. Não para atacar. Não para manipular. Apenas movimento normal de participação, o tipo que acontece todos os dias em todas as cadeias, o tipo que ninguém documenta porque nunca importou antes.
No FOGO isso importa.
A zona caiu abaixo do limite. O protocolo a filtrou. A rotação que deveria ir para a Ásia-Pacífico, depois Europa, depois América do Norte agora vai para a Ásia-Pacífico, depois Europa, depois Ásia-Pacífico novamente.
Minha aplicação foi codificada para três zonas.
Está agora rodando contra dois.
Eu encontrei o bug às 2:31 da manhã. Não nos logs. No comportamento. O motor de liquidação estava disparando no cronograma, mas as confirmações de execução estavam chegando 40% mais lentas do que a linha de base. Não estava quebrado. Apenas... esticado. Como se a aplicação estivesse alcançando algo que costumava estar lá.
Estava alcançando validadores da América do Norte que não estavam mais na rotação.
A aplicação sabia o cronograma. Não sabia que o cronograma poderia mudar.
Eu li o litepaper. Página seis. Parâmetro de limite de participação mínima que filtra zonas com participação total delegada insuficiente. Eu li e pensei: escolha de design interessante. Eu não pensei: isso vai disparar às 2:19 da manhã em uma terça-feira e todo o seu modelo de tempo estará errado quando você acordar.
O litepaper não te diz como se sente quando uma zona desaparece.

Aqui está como se sente.
Tudo continua funcionando. Essa é a primeira coisa. O FOGO não pausa. Blocos continuam chegando a cada 40 milissegundos. As zonas ativas continuam produzindo. O Firedancer mantém a execução uniforme. A cadeia está completamente saudável.
Sua aplicação é a única coisa que sabe que algo mudou.
E sua aplicação só sabe porque foi construída com suposições que o protocolo nunca prometeu manter.
Três zonas. Uma hora cada. Rotação limpa. Eu havia construído um modelo de tempo de liquidação em torno dessa cadência. Pré-posicionar 55 minutos em cada epoch. Executar em 58 minutos. Sair antes do pico de latência da troca de zona. Limpo. Repetível. Lucrativo.
O modelo assumiu que a América do Norte sempre ativaria. O protocolo não assumiu nada desse tipo.
Eu puxei os dados do validador às 3:02 da manhã. Rastreando as redelegações. Três validadores de médio porte tinham movido participação para a zona da Ásia-Pacífico nas 96 horas anteriores. Não coordenado. Apenas deriva. O tipo de movimento de participação orgânica que parece aleatório porque é aleatório.
Mas o movimento de participação aleatório no FOGO tem consequências determinísticas nas fronteiras de epoch.
O protocolo não se importa por que a participação se moveu. Ele executa o filtro. A zona atende ao limite ou a zona não ativa. A América do Norte não ativou. A rotação mudou. Minha aplicação herdou a mudança sem aviso porque a mudança não exigia aviso. Estava operando exatamente como documentado.
Eu estava operando com suposições que nunca documentei nem para mim mesmo.
A perda não foi catastrófica. Execução mais lenta, não execução falhada. Talvez $31.000 em janelas de liquidação perdidas ao longo de quatro horas antes de eu perceber e corrigir o modelo de tempo. Talvez mais. O tipo de perda que não aparece como uma perda, aparece como subdesempenho, o que é mais difícil de ver e, portanto, mais difícil de corrigir.
Eu corrigi isso às 3:44 da manhã. Adicionei uma consulta de configuração da zona na fronteira do epoch. Puxar o conjunto de zonas ativas da cadeia antes de assumir o padrão de rotação. Custou-me 8 milissegundos por epoch. Salvou-me de construir mais quatro horas de lógica em cima de uma fundação que já havia mudado.
O patch parecia óbvio às 3:44 da manhã. Não parecia necessário em nenhum momento nos seis dias anteriores.
Essa é a questão sobre o mecanismo de limite de participação do FOGO que ninguém fala porque todos assumem que lidarão com isso corretamente e ninguém assume corretamente até depois que não o fizeram.
A rotação da zona não é um cronograma fixo. Parece um cronograma fixo. Comporta-se como um cronograma fixo por dias ou semanas a fio, o suficiente para que você comece a tratá-lo como infraestrutura em vez de como uma propriedade emergente da distribuição de participação.
Então, três validadores moveram participação em uma noite de terça-feira e o cronograma em torno do qual você construiu sua aplicação parou de ser o cronograma.
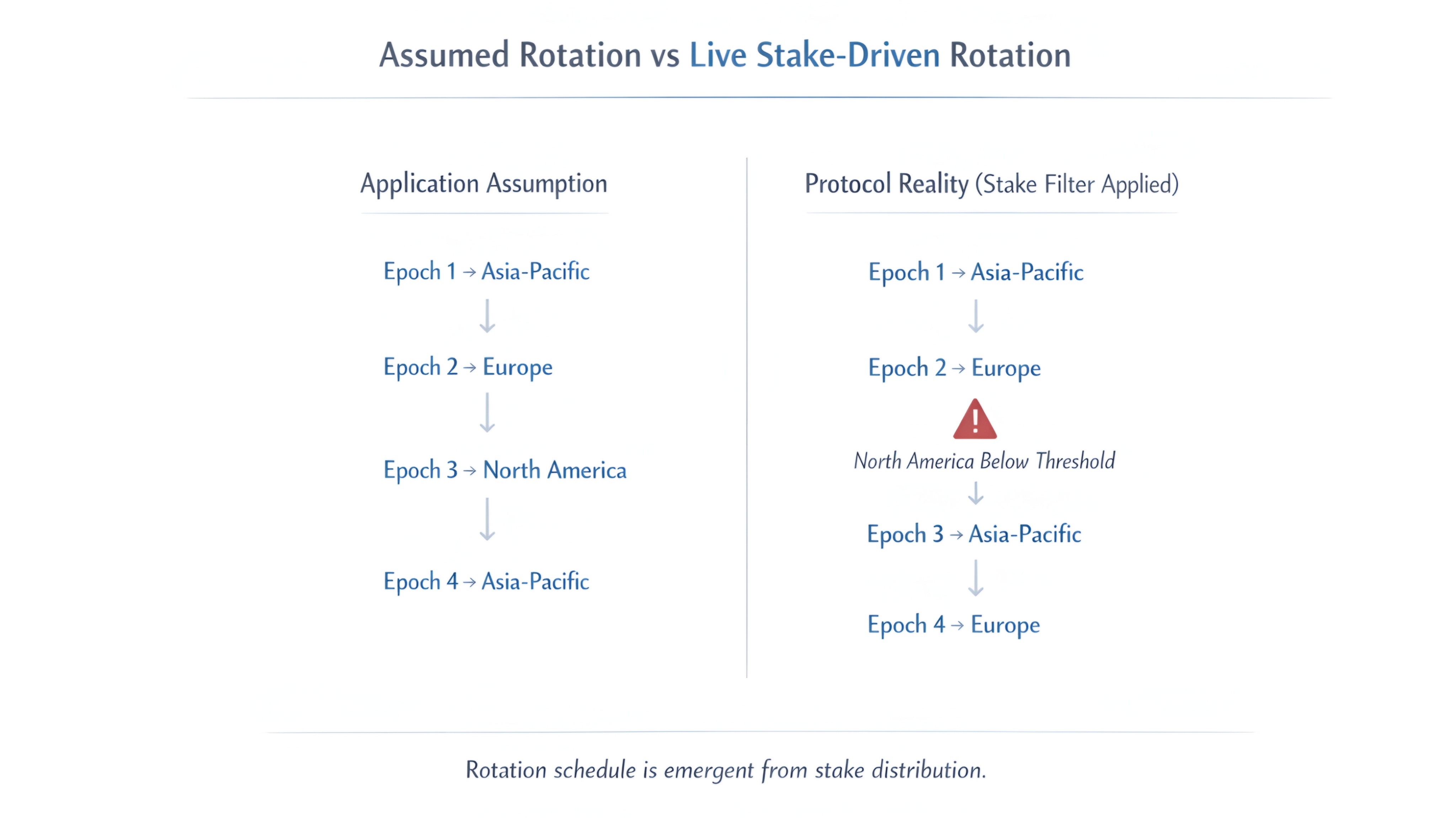
O protocolo não está errado. O protocolo filtrou uma zona que não atendia ao limite. É isso que se supõe que ele faça. O parâmetro de segurança existe porque uma zona com participação insuficiente é uma zona que pode ser atacada. O protocolo protegeu a rede.
Simplesmente não protegeu minhas suposições de tempo.
Eu venho construindo em cadeias de alto desempenho há três anos. Os modos de falha que conheço são congestionamento, transações descartadas, timeouts de RPC, finalização falhada. Essas são falhas barulhentas. Elas se anunciam. O monitoramento as captura. Alertas acionam o alerta barulhento, não o silencioso.
O FOGO tem um modo de falha que eu não havia encontrado antes, que é a suposição que era verdadeira ontem se tornar falsa em uma fronteira de epoch porque a distribuição de participação mudou e o protocolo respondeu corretamente e sua aplicação não estava observando a distribuição de participação porque você não sabia que precisava observar a distribuição de participação.
É uma falha silenciosa. A cadeia está saudável. Sua aplicação está errada. A diferença entre esses dois estados é invisível até que você meça a coisa certa.
Eu estava medindo a produção de blocos e a confirmação de transações e a latência da zona. Eu não estava medindo a proximidade do limite de participação por zona. Eu não sabia que isso era algo a medir até que o alerta silencioso disparou às 2:23 da manhã.
Os desenvolvedores que constroem no FOGO e nunca atingem isso não o farão porque são melhores. Eles não o atingirão porque sua distribuição de participação permaneceu acima do limite, ou porque sua aplicação não depende da cadência de rotação, ou porque tiveram sorte com o tempo de suas redelegações.
Aqueles que o atingirão o farão da mesma maneira que eu atingi. Não por falha de documentação. O litepaper é claro. Limite de participação mínima, página seis, linguagem simples.
Eles o atingirão a partir da acumulação de suposições. A cada dia que a zona rota corretamente, a suposição de que sempre rotacionará corretamente se torna um pouco mais forte. A suposição nunca é testada até o epoch em que é quebrada, e então já são 2:19 da manhã e o filtro já rodou e a zona já se foi.
Adicionei três coisas ao meu monitoramento depois daquela noite.
Proximidade do limite de participação por zona, atualizado a cada 30 minutos. O conjunto de zonas ativas é puxado em cada fronteira de epoch antes de executar qualquer lógica de tempo. O limite de alerta é definido em 97% do mínimo, não 94%, porque 94% parecia seguro e não era seguro.
A terceira coisa que adicionei foi mais simples. Um comentário no código acima da lógica de rotação.
Diz: o cronograma de rotação é emergente. Consulte-o. Não assuma.
Oito palavras. Custou-me $31.000 escrevê-las.
A arquitetura do FOGO é honesta sobre isso. O filtro de limite de participação não é um mecanismo oculto. Está documentado, explicado, justificado. O protocolo não promete que uma zona ativará. Promete que se uma zona atender ao limite, ela ativará. A distinção é precisa e o litepaper a declara precisamente.
Eu li isso como uma garantia. Era uma condição.
Aquele espaço entre garantia e condição é onde meu modelo de tempo viveu por seis dias, confortável e errado, até que o epoch mudou e a zona não estava lá e o alerta silencioso disparou e eu aprendi a diferença às 2:23 da manhã.
O FOGO não deve uma programação de rotação estável. Deve uma correta.
Essas não são a mesma coisa.
Os desenvolvedores que entendem isso cedo construirão monitoramento que observa a distribuição de participação em vez de assumir. Eles consultarão a configuração da zona nas fronteiras de epoch em vez de armazená-la em cache na inicialização. Eles tratarão o padrão de rotação como dados ao vivo, em vez de infraestrutura estática.
Os desenvolvedores que aprendem isso da maneira que eu aprendi vão aprender às 2 da manhã, nos logs, perseguindo um alerta silencioso que disparou porque algo estrutural mudou e nada quebrou e a cadeia continuou rodando e a única coisa errada era o modelo dentro de sua própria aplicação.
Eu ainda assisto a participação da zona da América do Norte a cada 30 minutos.
Está em 96% agora.
Vou verificar novamente em 30 minutos.
