@Vanarchain • #Vanar • $VANRY
No mês passado, fiz algo estúpido. Eu me inscrevi em uma ferramenta de IA 'gratuita' para limpar uma nota de voz. Dois toques. Fácil. Então, pediu acesso aos meus arquivos 'para melhorar os resultados'. Eu cliquei em sim... porque estava com pressa. Mais tarde naquela semana, um anúncio apareceu usando palavras daquela nota privada. Não a linha completa. Apenas o suficiente para fazer meu estômago cair. E eu me lembro de pensar, bem... esse é o comércio que continuo fazendo. Continuo alugando minha própria vida para sistemas que não controlo.
A IA não é apenas chatbots e filtros bonitinhos. O verdadeiro trabalho de IA é dado. Registros de saúde. Arquivos de folha de pagamento. Clipes de call center. Planos de produtos. Documentos da cadeia de suprimentos. E a maior parte desses dados não é destinada ao público. Então, quando as pessoas dizem 'blockchain pronto para IA', minha primeira pergunta é simples: onde os dados vivem, quem pode vê-los e o que impede um vazamento quando mil aplicativos começam a acessá-los?
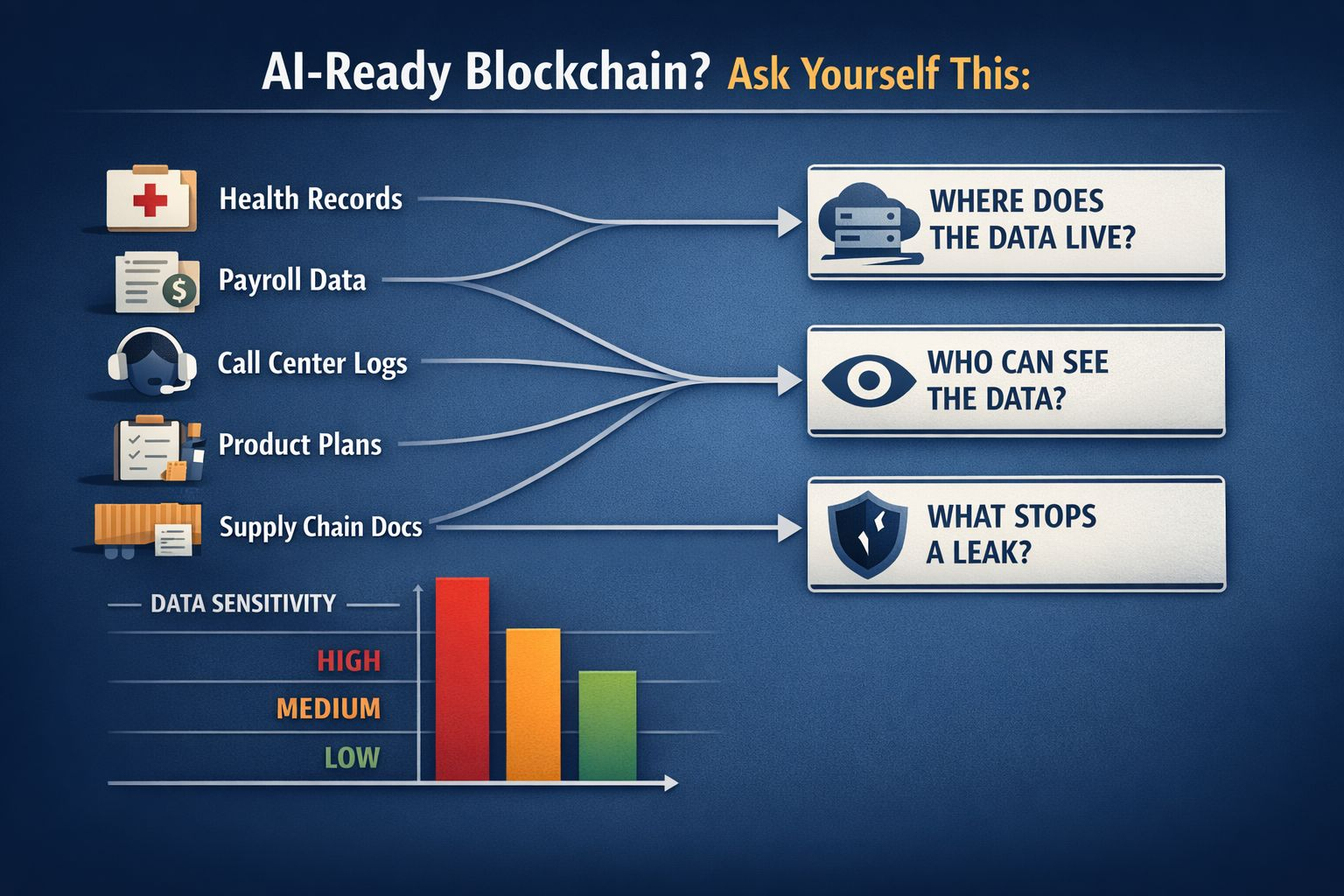
Muitas cadeias foram construídas para estado aberto. Todos veem tudo. Isso é bom para movimentos de tokens. É terrível para entradas de IA. Se sua cadeia não pode lidar com a privacidade de uma maneira normal, não é “pronta para IA”. É “curiosa sobre IA”. Grande diferença.
A Vanar Chain (VANRY), pelo menos na forma como o ecossistema fala sobre isso, está promovendo a ideia de que a privacidade não é um complemento. É parte do acordo base se você quiser aplicativos sérios. Quando você traz IA para o Web3, você não está apenas executando código. Você está movendo dados humanos brutos. Se você tratar isso como fofoca pública de mempool, receberá o que merece. Confiança quebrada. Nenhuma empresa real. Nenhum usuário real.
Pense nos dados como água em uma cidade. A cadeia é o sistema de tubulações. A maioria das tubulações em cripto é de plástico transparente. Qualquer um pode olhar e ver o que está fluindo. Isso é “transparente”. Também é assustador. Para casos de uso de IA, você precisa de tubulações que possam transportar água sem que a rua inteira esteja assistindo. A privacidade não é sobre esconder crimes. É sobre não transformar a vida cotidiana em um feed público.
Vamos falar sobre o que a privacidade dos dados realmente significa aqui, sem a neblina. Em uma cadeia, a privacidade geralmente significa uma das poucas coisas.
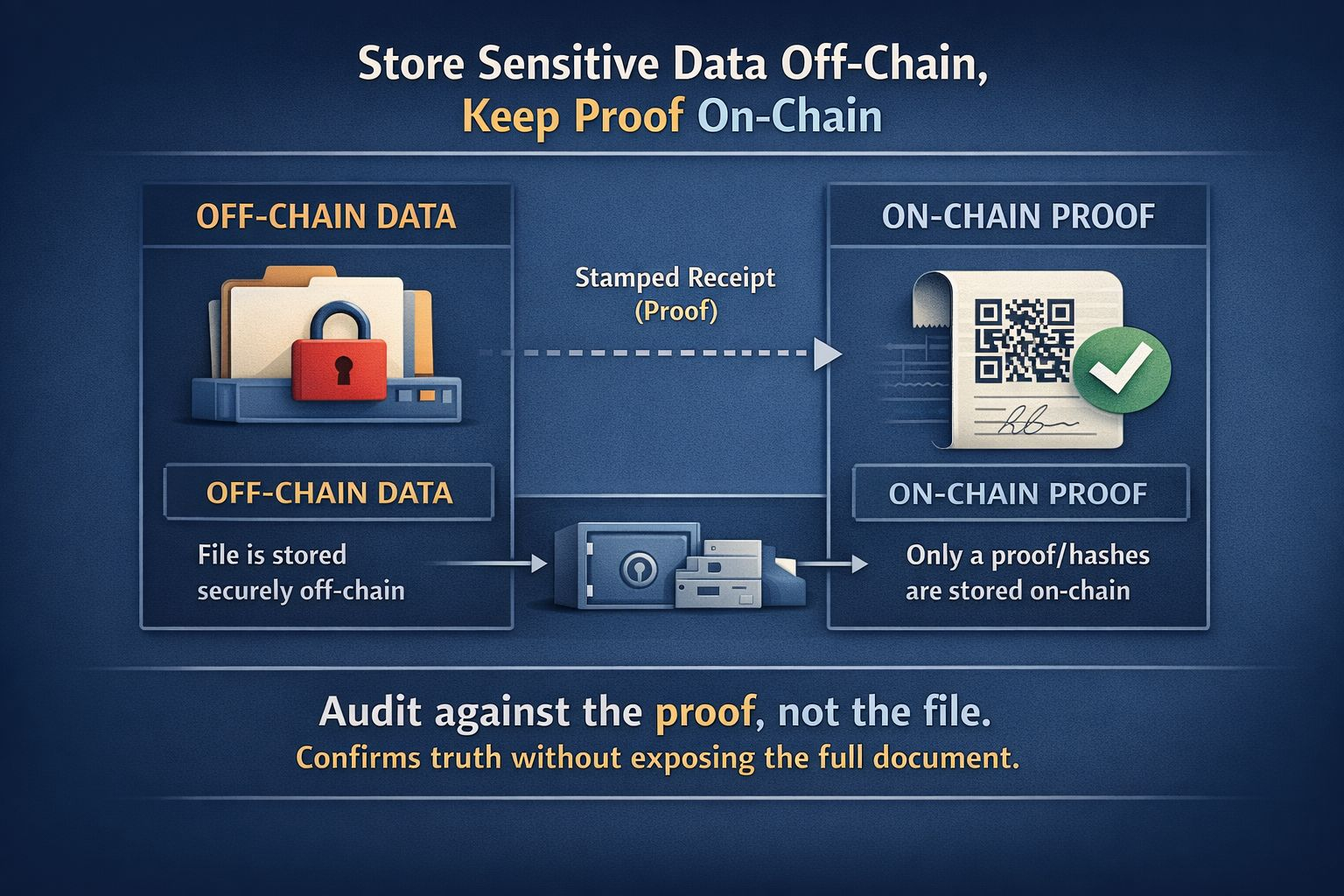
Um: você não armazena dados sensíveis na cadeia de forma alguma. Você os armazena fora da cadeia e apenas armazena prova ou referência na cadeia. Uma “prova” é como um recibo carimbado. Diz: “Isso é verdade”, sem mostrar o documento completo. Isso importa para a IA porque muitas vezes você não precisa do arquivo completo na cadeia. Você precisa saber que o arquivo não foi alterado. Você precisa de auditoria, não de exposição.
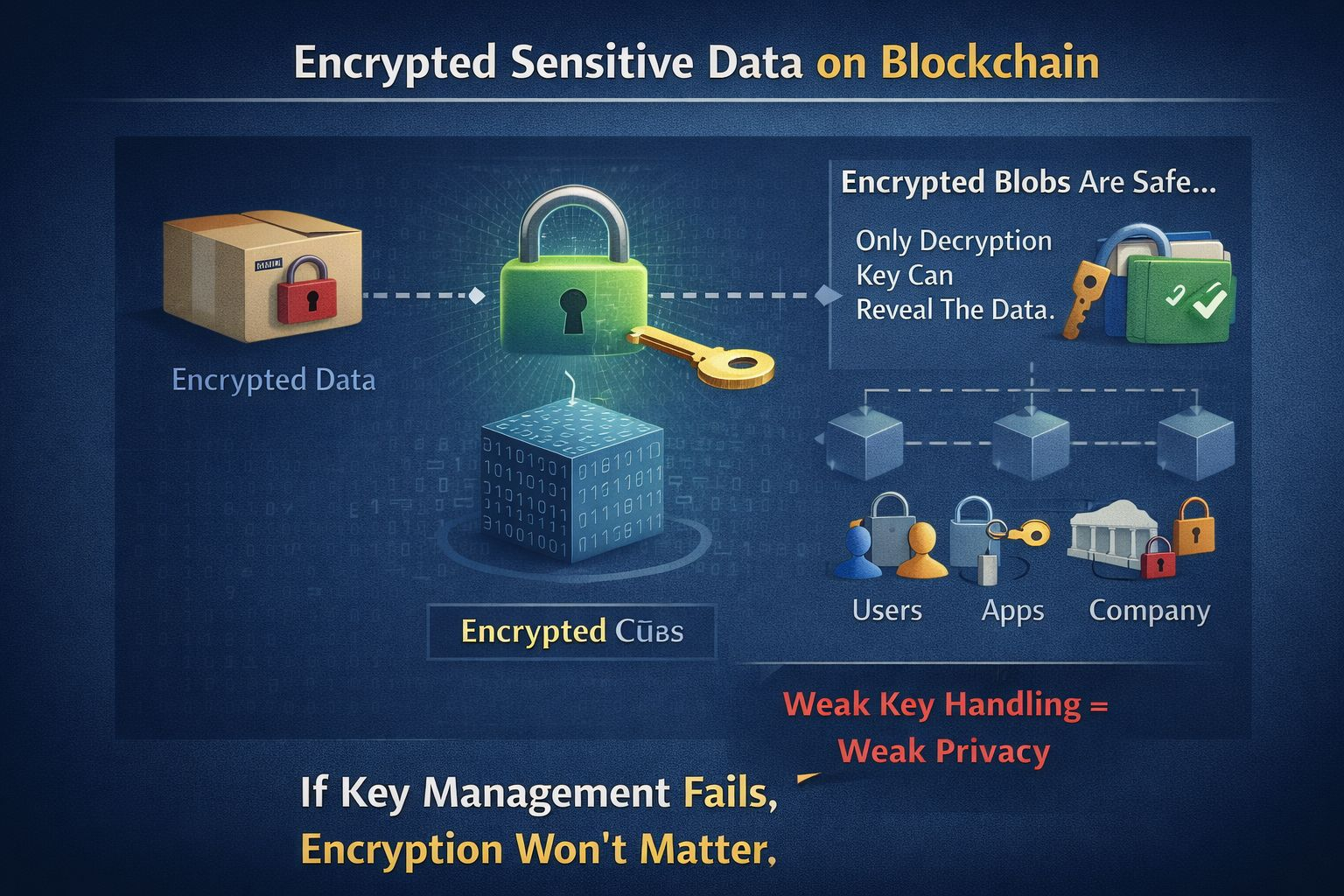
Dois: você usa criptografia. Isso é apenas embaralhar dados para que apenas a chave certa possa lê-los. A cadeia pode conter blobs criptografados, mas o público não pode lê-los. Parece fácil, mas fica bagunçado rapidamente. Quem detém as chaves? Usuários? Aplicativos? Uma empresa? Se as chaves forem descuidadas, a privacidade colapsa. É por isso que “pronto para IA” também é “pronto para operações”. Matemática sofisticada não salvará um manejo fraco de chaves.
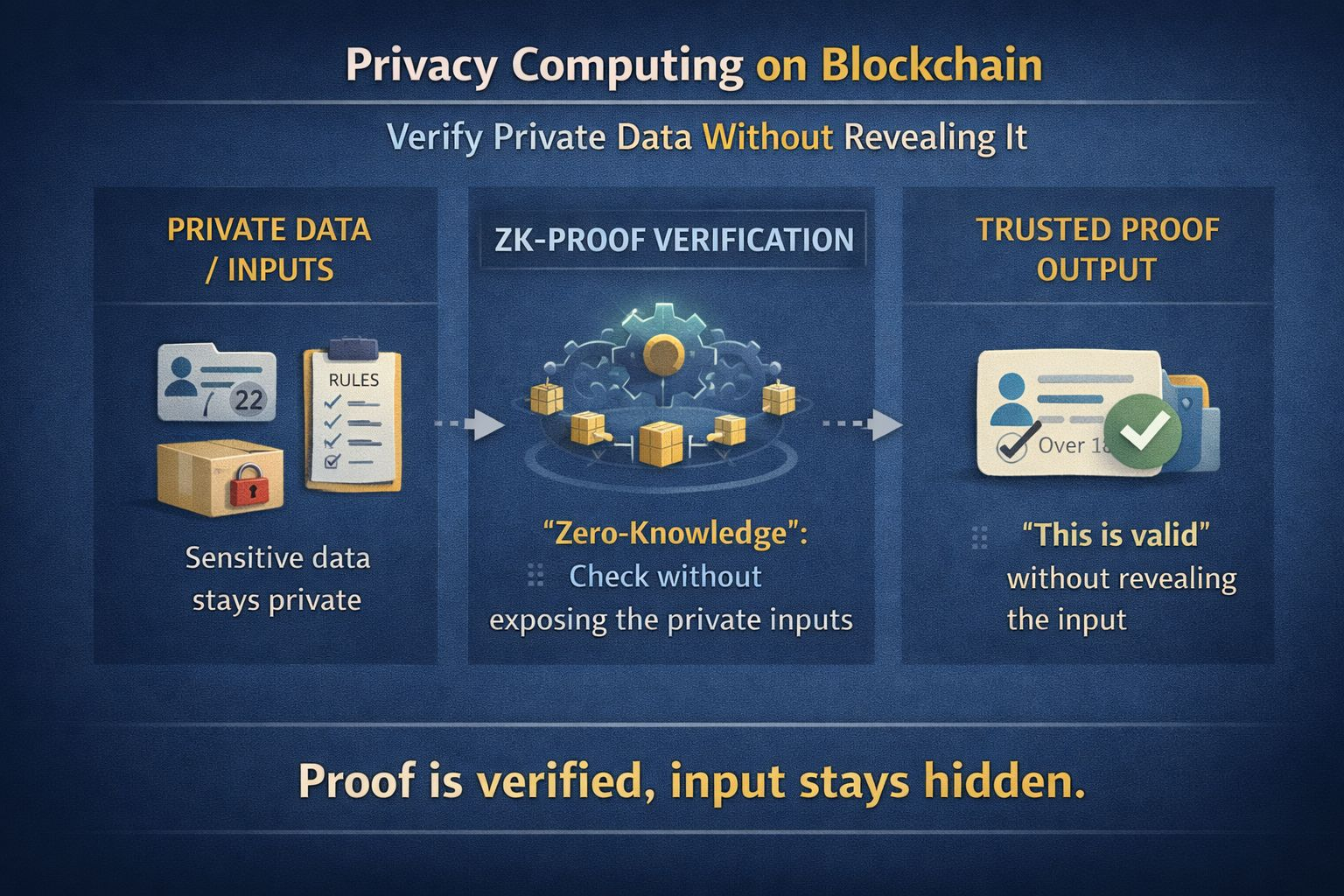
Três: você usa computação de privacidade. Isso pode significar coisas como “provas de conhecimento zero”. Versão simples: você pode provar que seguiu as regras sem mostrar as entradas privadas. Como provar que você tem mais de 18 anos sem mostrar seu cartão de identificação completo. Para IA, isso pode se estender a provar que um modelo usou dados permitidos, ou que a saída veio de uma versão específica do modelo, sem despejar os dados em si. Difícil de construir. Mas é a direção que sistemas sérios estão seguindo.
Agora, por que a Vanar se importa? Porque aplicativos de IA são bagunçados. Eles não agem como trocas simples. Eles querem arquivos grandes, acesso repetido e controle de direitos. E trazem novos riscos: vazamentos de modelo, vazamentos de solicitação, reutilização de dados e treinamento silencioso sobre conteúdo do usuário. Se uma cadeia quiser ser um lar para fluxos de trabalho de IA, ela precisa tornar a privacidade chata. Não mágica. Apenas normal. Drama mínimo. Consistente em vez de teórico.
Aqui está um padrão de exemplo real. Uma empresa quer executar IA em documentos internos. Eles não podem colocar esses documentos em uma cadeia pública. Mas podem querer um trilho de auditoria público que mostre: quem solicitou acesso, quando, sob quais regras e se o documento foi alterado. É aí que uma cadeia “pronta para IA” pode ajudar. A cadeia se torna o livro de regras e a impressora de recibos. Os dados permanecem protegidos. As ações permanecem responsabilizadas.
Esse é o cerne: privacidade mais auditoria. Se você só tiver privacidade, não pode provar nada. Se você só tiver auditoria, expõe tudo. Sistemas de IA precisam de ambos. E a mensagem da Vanar se inclina para essa combinação. Privacidade como uma barreira. Auditoria como uma espinha dorsal.
Há também uma razão simples na estrutura de mercado. Aplicativos de IA morrem se os usuários não confiarem neles. Não “eu gosto da interface” confiança. Confiança real. Aquele tipo onde você fará o upload de um rascunho de contrato ou de um relatório médico. A maioria das pessoas não fará isso se pensar que a cadeia é uma casa de vidro. Portanto, a privacidade não é um “recurso”. É o ingresso de entrada.
Mas não vamos fingir que é de graça.
A privacidade na cadeia muitas vezes luta contra o desempenho. Criptografar, provar e controlar o acesso adiciona custo e atraso. Fluxos de trabalho de IA já custam computação. Portanto, o design precisa ser prático. Você não quer um sistema que seja seguro em teoria, mas inutilizável na prática. É aqui que muitos projetos falam muito e entregam pouco. O verdadeiro teste é coisa chata: como as chaves são gerenciadas, como as permissões são revogadas, como os logs são armazenados, como os dados se movem entre aplicativos sem vazar.
Outro problema é que a privacidade pode esconder comportamentos ruins. Essa é uma preocupação real. Se tudo é privado, monitorar fraudes se torna mais difícil. A resposta não é “tornar tudo público”. A resposta são boas camadas de política. Acesso fino. Divulgação seletiva. Trilhas de auditoria que mostram ações sem despejar conteúdo privado. Esse equilíbrio é o jogo todo.
A condição de vitória não é “privacidade máxima”. É “privacidade certa”. O suficiente para proteger usuários e empresas. O suficiente para tornar os fluxos de trabalho de IA viáveis. Enquanto ainda dá ao ecossistema uma maneira de verificar se as regras foram seguidas. Se a Vanar Chain (VANRY) puder fazer isso parecer padrão como cintos de segurança em um carro, então será significativo. Se permanecer como um slogan, não importará.
Opinião pessoal, eu acho que a privacidade dos dados é a diferença entre a IA ser um brinquedo e a IA ser infraestrutura. Cadeias que ignoram isso ficarão presas hospedando aplicativos públicos de baixo risco. Memes, jogos simples, talvez postagens sociais básicas. Isso não é um insulto. É apenas o limite do estado aberto.
Se a Vanar Chain (VANRY) quer ser levada a sério na conversa sobre estar pronta para IA, precisa continuar fazendo o trabalho pouco atraente: primitivas de privacidade que os desenvolvedores realmente podem usar, ferramentas claras, regras claras e caminhos de integração limpos para armazenamento e computação fora da cadeia. E precisa ser honesta sobre as compensações. Latência. Custo. Complexidade. Sem fingir que isso desaparece.
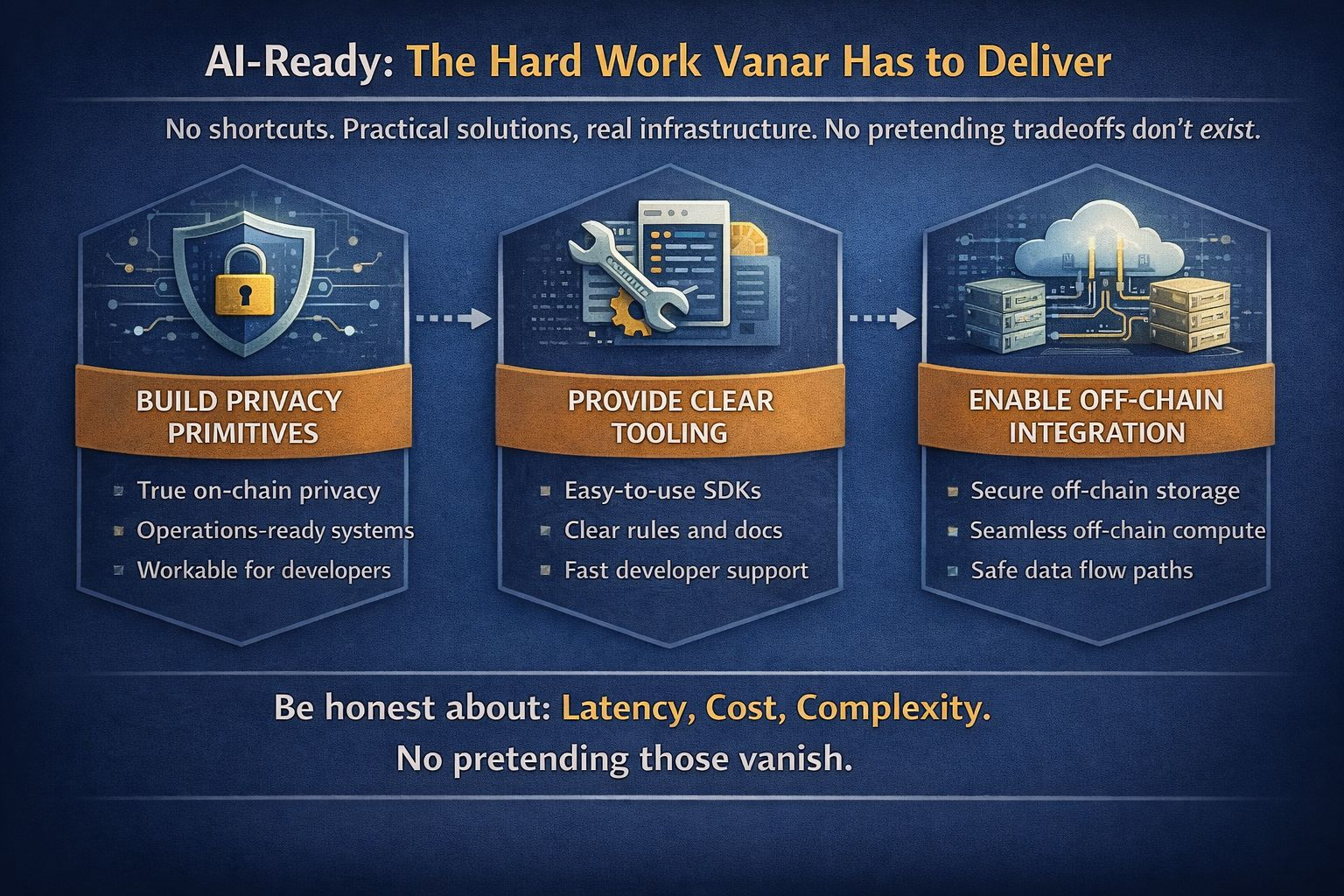
Porque o futuro não é “IA na cadeia” em alguma forma pura. O futuro é híbrido. Dados privados fora da cadeia, ações verificadas na cadeia e modelos de IA que podem provar o que fizeram sem revelar as entradas. Essa é a arquitetura que escala a confiança. Isso é o que “pronto para IA” deve significar. Se a Vanar continuar mirando nisso, a privacidade deixa de ser marketing. Torna-se a razão pela qual usuários reais aparecem.
