
I’ve been trying to explain to myself why building on Vanar feels different. The cleanest answer is that it assumes AI will be a first-class user of the system. My old mental model for blockchain projects was simple: the chain records transactions and state, and anything “smart” happens off to the side in a service you can’t really inspect. Vanar’s own description points the other way, calling itself an AI-focused Layer 1 stack where the infrastructure is built for “intelligent” applications.
That framing matters now because AI has shifted from “generate text” to “take actions without falling apart.” Teams are wiring models into workflows where they have to call tools, return predictable data, and keep enough context to behave consistently across sessions. Tool calling and structured outputs are becoming basic plumbing for reliability, because free-form text is too slippery when something real has to happen.
When I look at Vanar through that lens, I notice it keeps pulling context down into the base layers instead of treating it as an app problem. The stack it describes includes a semantic memory layer (Neutron) and a reasoning layer (Kayon), and it calls out built-in vector storage and similarity search as native capabilities.
Instead of starting with “Where do I keep everything off-chain and hope the agent retrieves it,” you’re nudged to think about what should be stored as memory and evidence. Neutron is the clearest statement of that posture. Rather than treating documents as inert blobs referenced by pointers, it’s presented as a way to compress and restructure files into small, queryable objects called Seeds, stored on-chain with proofs. The site even gives a concrete compression example—25MB down to 50KB—which I read less as a promise and more as intent: build around meaning and verifiable summaries, not bulky files and fragile links.
Kayon then sits above as a layer meant to reason over that stored context, including natural-language querying and automation around rule checks. I’m careful with the word “reasoning,” because it can cover a lot, but the direction is clear: make more interpretation visible and verifiable instead of hiding it in private pipelines.
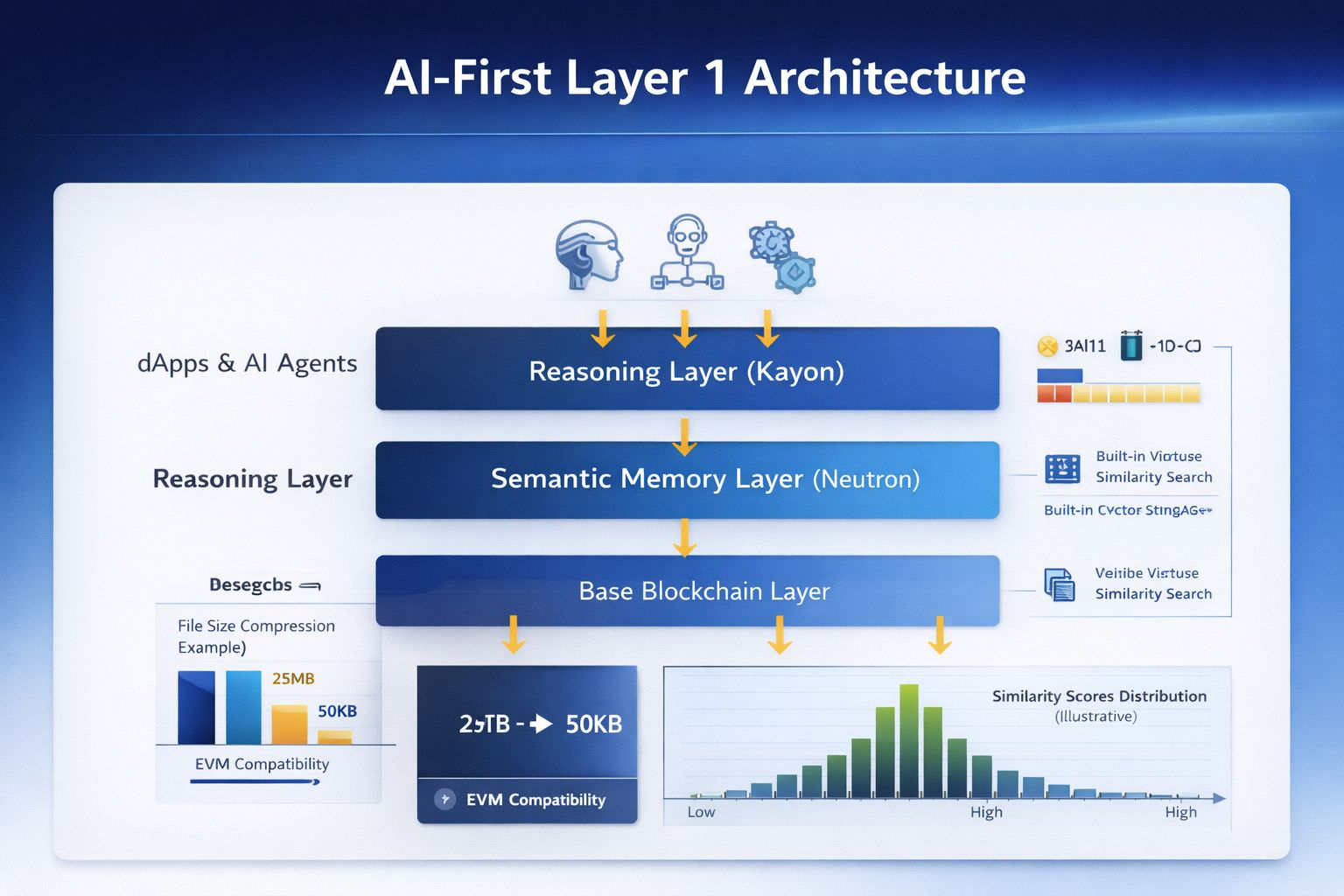
What makes this feel usable, not just ambitious, is that Vanar tries to keep the developer path familiar. It leans on EVM compatibility—“what works on Ethereum, works on Vanar”—and points to a Geth fork in its public codebase.
That matters because agent building already has enough moving parts, and it’s easy to burn time fighting the basics instead of wrestling with memory, permissions, and behavior. None of this guarantees an easy ride. That’s the bet, at least. You still have to make the hard calls: what belongs on-chain, what you’re willing to treat as truth, and how far you let an automated system act without a human in the loop. But once you treat memory and machine use as part of the protocol itself, the work feels different. It stops being “write an app and use the chain like a database,” and starts being “design a system where the chain carries enough context to shape behavior,” not just enough data to log what happened.
@Vanarchain #vanar #Vanar $VANRY
