
Когда я впервые начала разбираться в том, как именно тренируются большие языковые модели, меня поразила одна цифра: для обучения GPT-3 понадобилось около 45 терабайт текстовых данных. Представьте себе масштаб - это миллиарды документов, книг, статей, разговоров. А теперь подумайте, где все это хранится и кто контролирует доступ к этим данным. Именно здесь я увидела настоящую проблему, которую решает @Walrus 🦭/acc , и это намного глубже, чем просто "еще одно криптохранилище".
Сучасна AI-індустрія стикається з парадоксом: для навчання моделей потрібні величезні, різноманітні датасети, але більшість цінних даних зосереджені в руках кількох технологічних гігантів. Google, Meta, Amazon контролюють не лише обчислювальні потужності, а й самі дані. Невеликі лабораторії, стартапи, дослідники з університетів фізично не можуть конкурувати, бо навіть якщо у них є алгоритми, їм ніде взяти якісні навчальні дані в потрібному обсязі. Зберігання петабайтів інформації в AWS коштує десятки тисяч доларів щомісяця, не кажучи вже про смугу пропускання для доступу до цих даних під час тренування.
Протокол Walrus побудований на блокчейні Sui і використовує технологію стирального кодування, яка працює принципово інакше, ніж традиційне зберігання. Замість того щоб зберігати ваш файл на одному сервері чи навіть робити його копії на кількох серверах, #Walrus розбиває дані на фрагменти, кодує їх спеціальним алгоритмом і розподіляє по тисячах незалежних вузлів по всьому світу. Найцікавіше те, що для відновлення файлу вам не потрібні всі фрагменти - досить лише їхньої частини, наприклад п'яти з десяти. Це означає, що навіть якщо половина вузлів відключиться, ваші дані залишаються доступними, чого неможливо досягти в централізованих системах без величезних витрат на надлишкове резервування.
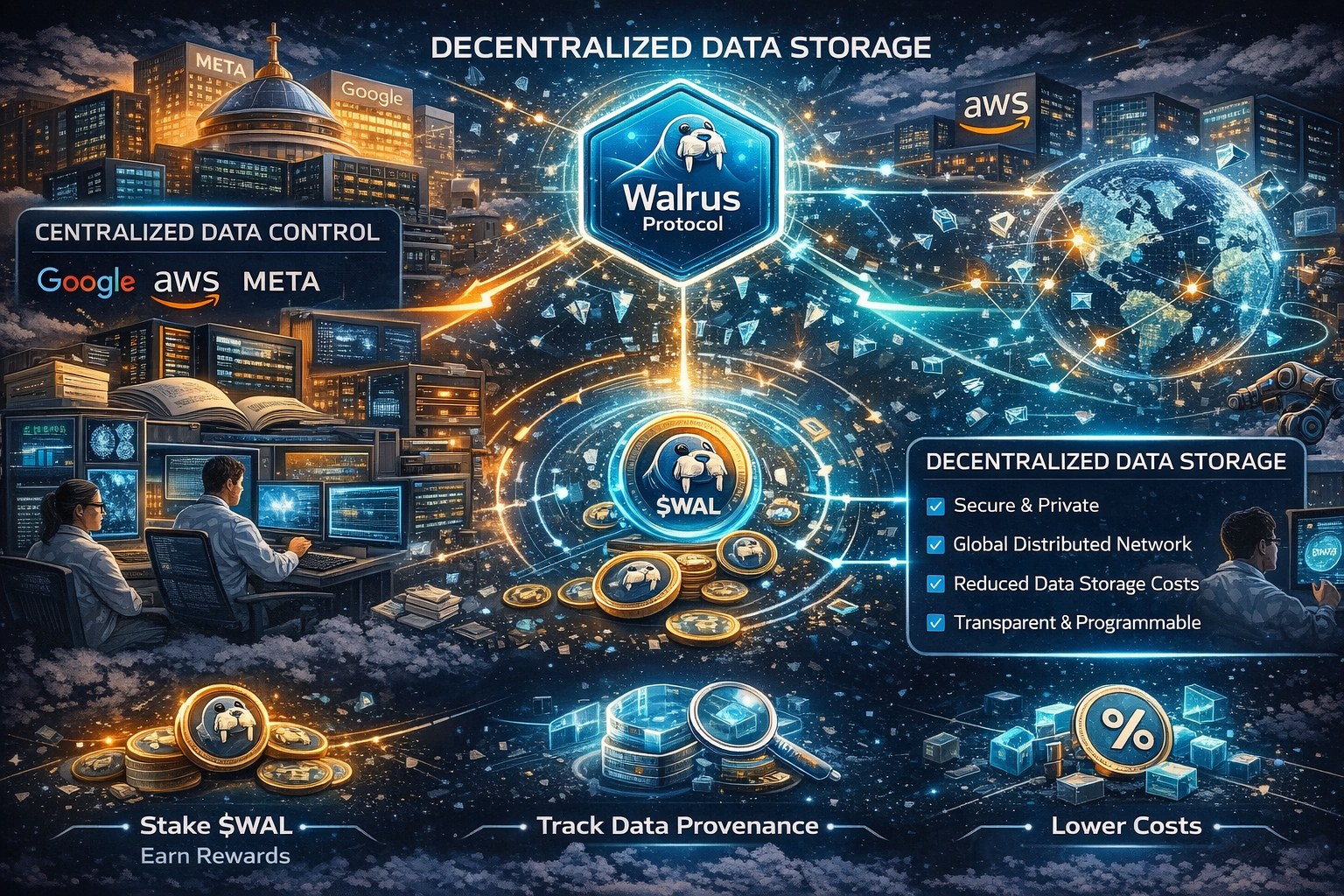
Для AI-дослідників це відкриває неймовірні можливості. Уявіть датасет з медичними знімками для діагностики раку - 500 терабайт анонімізованих МРТ та КТ сканів від лікарень по всьому світу. В централізованому світі такий датасет або взагалі не існував би через юридичні та логістичні бар'єри, або був би власністю однієї корпорації. На Walrus цей датасет може зберігатися децентралізовано, фрагментовано через erasure coding, де жодний окремий вузол не має повного доступу до чутливої інформації, але весь датасет доступний для навчання моделей будь-якому дослідникові в світі. Оператори вузлів заробляють токени $WAL за надійне зберігання цих фрагментів, а користувачі платять за доступ до даних значно менше, ніж коштувало б традиційне хмарне сховище - різниця може сягати 70-80 відсотків економії.
Але є й інший аспект, який мене особливо зачепив. Walrus дає можливість створювати перманентні, незмінні датасети з прозорою історією походження даних. Кожна операція записується в блокчейн Sui, тому ви завжди можете простежити, звідки взялися дані, хто їх завантажив, які версії існують. Зараз ми не знаємо точно, на чому навчені ChatGPT чи Claude - це комерційна таємниця. А що якби кожен AI-датасет мав такий прозорий on-chain запис? Це змінило б правила гри в дослідженнях штучного інтелекту, зробивши науку відтворюваною, а моделі справді аудитованими на предмет біасів, якості та етичності навчальних даних. Ви могли б точно знати, що модель не тренувалася на піратському контенті чи особистих даних без згоди.
Протокол Walrus також вирішує проблему доступності даних під час самого процесу навчання. Коли ви тренуєте нейронну мережу, GPU-кластер постійно запитує нові батчі даних - сотні гігабайт щогодини. В традиційній архітектурі це означає величезні витрати на egress traffic від хмарного провайдера. Walrus дозволяє розгорнути вузли доступу географічно близько до ваших обчислювальних потужностей, що радикально знижує латентність та вартість передачі даних. По суті, ви отримуєте глобальну CDN для AI-датасетів, де кешування та доставка відбуваються автоматично через економічні стимули протоколу.
Чесно кажучи, я бачу тут не просто технічне рішення, а зміну парадигми. Walrus може стати фундаментом для демократизації AI, коли доступ до даних визначається не розміром вашого AWS-рахунку, а якістю вашої ідеї та алгоритму. Токен $WAL в цьому контексті це не спекулятивний інструмент, а економічний механізм, що робить можливим існування публічних AI-датасетів без централізованого спонсора. Оператори вузлів стейкають токени як гарантію чесності, отримують винагороди за зберігання даних, а користувачі платять за доступ - проста, але елегантна економіка, яка працює без довіреної третьої сторони. Звісно, є виклики - інтеграція з PyTorch та TensorFlow ще не ідеальна, швидкість доступу до холодних даних може бути повільнішою за S3, правові питання відповідальності за контент потребують вирішення. Але напрямок мені здається абсолютно правильним, особливо зараз, коли ми бачимо, як AI стає монополією кількох компаній, а решта світу залежить від їхньої інфраструктури та умов доступу.

