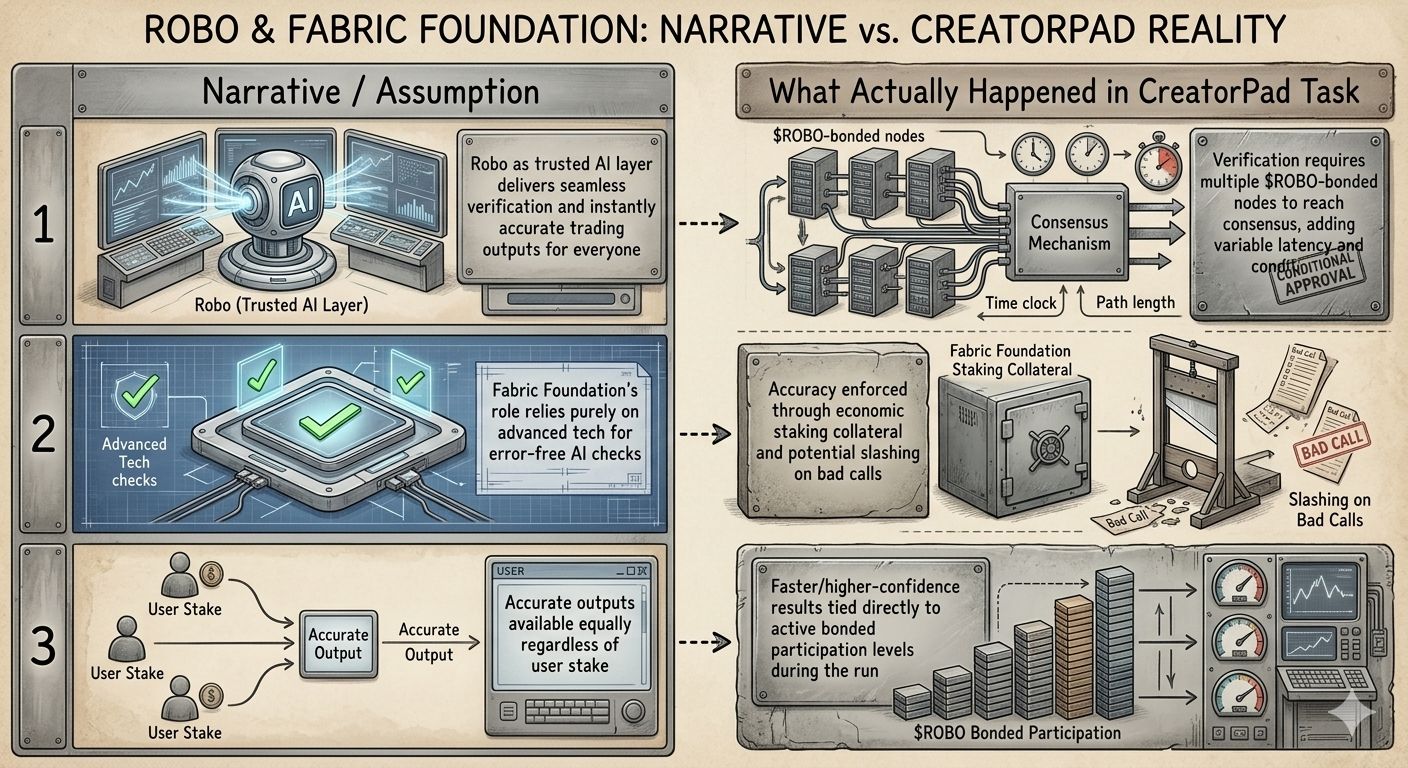
I was deep into a CreatorPad task, running parallel simulations of AI-driven trading strategies on volatile pairs, when the integration with Robo on Fabric Foundation forced a hard stop on one of my cleaner-looking signals. The output had all the hallmarks of a solid edge—precise entry, tight stop, projected 3:1 reward—but the verification layer flagged it anyway, citing a low-confidence cross-check from one of the bonded nodes. That single rejection, buried in the logs without any dramatic alert, made me lean back and stare at the screen longer than I expected. It wasn’t the rejection itself; it was how unceremoniously the system treated what looked flawless on paper. Here was Fabric Foundation quietly doing its job as the backbone of AI verification, with $ROBO, #ROBO , and @Fabric Foundation operating in the background like the unseen referee no one talks about in the hype.
What stood out wasn’t some revolutionary algorithm revealing hidden market truths. In practice, during that task, Robo as the trusted AI layer behaved more like a high-stakes jury than a magic oracle. Every signal had to survive a round of verification where participating nodes staked $ROBO to vouch for the output’s integrity. I observed one instance where a seemingly accurate prediction on a momentum shift got approved swiftly because three high-stake verifiers aligned quickly; contrast that with another run where the same model output lingered in pending status until additional collateral came online. The Fabric Foundation’s role wasn’t just to check math—it enforced economic skin in the game, slashing stakes for false positives in test scenarios. This wasn’t mentioned in the glossy overviews; it emerged organically as I tweaked parameters and watched the latency and approval rates shift in real time.
One concrete behavior that lingered with me was how the system quietly prioritized verifiers with larger $ROBO positions. In the task logs, outputs cleared faster and with higher confidence scores when the consensus pool skewed toward heavier stakeholders. It wasn’t overt discrimination, but the data showed a clear correlation: low-stake sessions produced more cautious or even downgraded signals, even when the underlying AI model performed identically. This design choice ensures accurate outputs by making verifiers pay attention—literally risking capital on every approval—but it also meant that during my controlled tests, the “trusted” layer felt less democratic than the narrative suggests. Fabric Foundation had engineered accountability into the protocol, turning what could have been cheap compute into something that demands real commitment.
Reflecting afterward, it struck me how this practical reality reframes the entire promise of verified AI trading. We hear a lot about AI layers transforming markets, but watching Robo in action reminded me that the real innovation sits in the incentive layer Fabric Foundation built underneath. It’s not about eliminating every error; it’s about making sure the ones that slip through cost someone something tangible. That quiet reflection left me appreciating the subtlety—$ROBO isn’t just fuel; it’s the reason the verification holds up under pressure, even in a simulated environment like CreatorPad.
And yet, as the task wrapped, one implication kept circling: if verification strength scales directly with distributed staking power, what does that mean for the ecosystem when participation ebbs and flows with market cycles? The trusted outputs might stay accurate for those who can afford to stay bonded, but the broader accessibility I’d assumed at the start now feels conditional. It’s the kind of detail that doesn’t resolve neatly, just sits there as a reminder of how practice often diverges from the initial blueprint.