Właśnie natknąłem się na dyskusję o bezpieczeństwie AI, która naprawdę sprawiła, że zatrzymałem się i przeglądałem ją kilka razy. To nie jest ten stary problem, kiedy model po prostu się załamuje, ale coś bardziej podstępnego - wszystko wygląda dobrze, demo działa płynnie, online jest stabilnie, a potem pewnego dnia, po cichu, model lekko się odchyla, a ty w ogóle nie zauważasz, od którego dnia zaczął być zanieczyszczony. To właśnie sprawia, że Data Poisoning jest naprawdę przerażające.
Ostatnio Inference Labs ciągle podkreśla drift, wcześniej ignorowałem to słowo, dopóki nie natknąłem się na ich treści w TruthTensor, które całkowicie mnie obudziły. Ta sama wskazówka, te same dane, na krótką metę wszystko wygląda normalnie, ale gdy wydłużysz czas, zachowanie modelu zaczyna się powoli deformować. To nie jest tak, że parametry są złe, ale świat sam się zmienia, a model zmienia się razem z nim. Oceniasz wczorajszy model, a po uruchomieniu stajesz przed dzisiejszym światem, podczas gdy ryzyko czai się w jutrze.
Chciałbym porozmawiać o zanieczyszczeniu danych, ale nie chcę zaczynać od metod ataku. Chcę poruszyć bardziej realistyczny problem: skoro rzeczywisty świat z natury dryfuje, to dlaczego bezpieczeństwo wciąż jest jednorazowe? Przeprowadzenie jednego cyklu czerwonej drużyny, wydanie raportu i archiwizacja, a następnie ogłoszenie bezpieczeństwa? Szczerze mówiąc, coraz mniej wierzę w ten proces.
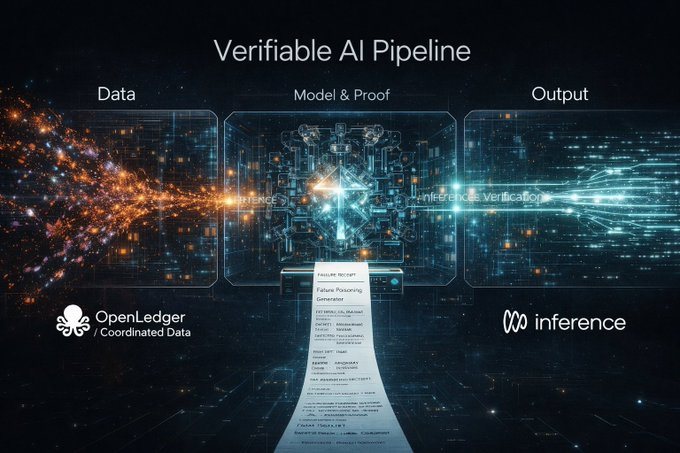
Ta sprawa idealnie zbiegła się z dzisiejszą trasą @inference_labs. Współpracują z nowym partnerem @OpenledgerHQ, aby koordynować dane treningowe i zapewnić ich wiarygodne pozyskiwanie na samym początku, podczas gdy Inference Labs odpowiada za warstwę weryfikacji modeli i wniosków. Od danych, przez modele, aż po wyniki wniosków, po raz pierwszy wyraźnie podzielono to na audytowalny proces. Ten krok jest naprawdę ważniejszy niż tylko wzmocnienie parametrów modelu.
To właśnie dzięki dodatkowej warstwie danych, znaczenie czerwonej drużyny staje się naprawdę pełne. Wiele osób, gdy rozmawia o zanieczyszczeniu danych, domyślnie atakuje tylko model, ale w rzeczywistym świecie to dane są często pierwszymi, które zostają zanieczyszczone. Jeśli dane źródłowe są śledzone, a wnioskowanie pośrednie jest weryfikowalne, cel ataku czerwonej drużyny zmienia się w całkowity proces, a granice bezpieczeństwa są naprawdę zamknięte.
Dodając DSperse, ten zestaw rzeczy naprawdę może się urzeczywistnić. Nie konfrontuje się z całym dużym modelem, ale dzieli weryfikację na segmenty, jakby rozkładał części samochodowe, a nie uderzał od razu całym pojazdem w ścianę. Dla czerwonej drużyny to jest kluczowe, ponieważ zanieczyszczenie danych często nie polega na całkowitym przebiciu modelu, lecz na cichym skręceniu kierownicy w pewnym miejscu.
Zawsze wydawało mi się to szczególnie dziwne, że obecne raporty czerwonej drużyny głównie opowiadają historie. PDF, kilka opisów, kilka zrzutów ekranu, w końcu chodzi o to, by uwierzyć. Ale Inference Labs przekształciło proces weryfikacji w wiarygodny dowód, a dane źródłowe również zmierzają w kierunku weryfikowalności, więc dlaczego dowody ataku wciąż pozostają na etapie ustnym? To jest naprawdę rozdzielone.
Dlatego nadałem temu pomysłowi bardzo prostą, ale użyteczną nazwę: Dowód Porażki. Brak dowodu bezpieczeństwa przypomina bardziej plotki niż odkrycie naukowe.
Moim zdaniem, odpowiedni dowód porażki jest całkiem prosty: wystarczy, aby ktoś mógł powtórzyć twoją porażkę, wskazując odcisk palca zobowiązania modelu, hash zobowiązania danych wejściowych, stan świata dryfu w momencie wyzwolenia, konkretną kategorię porażki, a na końcu podać polecenie, które można uruchomić. Porażka, której nie można powtórzyć, naprawdę trudno mi uznać za lukę.
Jeśli Inference Labs naprawdę chce uczynić z konkursu czerwonej drużyny mechanizm łańcuchowy, to najchętniej zobaczyłbym proces, który jest bardzo prosty: najpierw przesłać hash dowodu porażki, przy okazji wpłacić trochę pieniędzy, a po zakończeniu okresu okna ujawniać próbki i skrypty powtórzeń. Weryfikatorzy sieci używają DSperse do uruchomienia w segmentach, płatność następuje tylko po udanym wyniku, a w przypadku porażki kaucja jest spalana. Brzmi to nieco surowo, ale jest to najskuteczniejsze przeciwko oszustom.
Oczywiście, na pewno będą pułapki, śmieciowe luki będą się mnożyć, a kradzież próbek do zdobycia zasług będzie miała miejsce, a zbyt wczesne ujawnienie pozwoli atakującym uczyć się szybciej. Dlatego mechanizmy commit-reveal i opóźnionego ujawniania są niezbędne: najpierw udowodnić istnienie powtarzalnej ścieżki, a szczegóły ujawniać później, dając czas na naprawę.
Bardzo chciałbym, aby w funkcji nagrody dodano wskaźnik, który pokaże, czy porażka ma związek z dryfem. W statycznym środowisku jest wiele luk, które można łatwo powtórzyć, ale te, które można długo i stabilnie wyzwalać w świecie dryfu, są naprawdę rzadkie. Dynamiczna ocena TruthTensor, połączona z całą wiarygodną linią, już sugeruje, że przyszłe bezpieczeństwo AI nie polega na obronie w jednym punkcie, lecz na ciągłym procesie przeciwdziałania.
@inference_labs jeśli naprawdę chcecie przesunąć konkurs czerwonej drużyny w kierunku mechanizmu, w obecnym systemie OpenLedger, w którym zarządzacie danymi, a wy zarządzacie modelami i weryfikacją, co najpierw byście ustandaryzowali?
A. Format dowodu porażki
B. Krzywa nagród
C. Mechanizm ujawniania i opóźnionego ujawniania
D. Środowisko powtórki dryfu (dryfowa uprząż)
Osobiście jestem najbardziej za D. Nie ma jednego świata, który można by powtórzyć przez wszystkich, a nawet najładniejszy dowód może jedynie powtórzyć emocje.
Jeśli uważasz, że pomysł dowodu porażki jest użyteczny, po prostu odpowiedz jednym literą, chcę zobaczyć, co myślą wszyscy o tym, która część tego zweryfikowanego procesu AI jest najbardziej potrzebna.