Punkt wyjścia do napisania tego artykułu jest bardzo prosty: postarać się jasno i w sposób możliwy do ponownego wykorzystania przedstawić, jak rozumiem metodologię Pyth Network; jednocześnie umieścić to w szerszym kontekście branży danych rynkowych i aplikacji na poziomie instytucjonalnym. W ciągu ostatnich kilku lat długoterminowo śledziłem ewolucję oracle i ścieżkę komercjalizacji danych, stopniowo wykształcając prosty, ale użyteczny wniosek: prawdziwie ważne w łańcuchu dostaw danych nie jest dekoracyjne „decentralizacja”, ale wiarygodna produkcja i weryfikowalna dostawa. Gdy podaż i popyt mogą nawiązać bezpośredni kontakt w łańcuchu, w sposób audytowalny, wartość staje się łatwiejsza do stabilnego uchwycenia.
Dla mnie Pyth nie jest „kolejnym komponentem wyceny”, ale linią produkcyjną danych cenowych, która od źródła produkuje i dystrybuuje na wielu łańcuchach. Tradycyjny model przypomina bardziej „drugiego pośrednika” informacji, gdzie agregatorzy, zbieracze i węzły pośredniczą w wielu etapach; opóźnienia, niepewność i brak możliwości śledzenia często stają się glebą dla ryzyka systemowego. Pyth przyjmuje model danych pierwszej strony, pozwalając giełdom, animatorom rynku i profesjonalnym sprzedawcom danych bezpośrednio podpisywać i publikować na łańcuchu; następnie poprzez Pythnet agreguje, weryfikuje, oblicza przedziały ufności i rozprowadza na podstawie subskrypcji na żądanie do aplikacji takich jak pożyczki, opcje, aktywa syntetyczne, indeksy itd. Tę trasę podsumowuję jako: nie być tubą, ale budować „zweryfikowaną linię produkcyjną cen”.
Jedno, sufit toru i rzeczywiste potrzeby.
Wartość branży danych rynkowych pochodzi z dwóch końców: z jednej strony jakość i terminowość źródła, z drugiej strony użyteczność i wrażliwość kosztowa konsumentów. W tradycyjnym finansowaniu dystrybucja danych i bieżące stawki są długoterminowymi stabilnymi kategoriami płatności; przechodząc do świata kryptowalut, popyt się nie zmienił, tylko wymagania dotyczące „weryfikowalności” i „programowalności” stały się wyższe. Strategie pożyczek i rozliczeń wymagają niskiego opóźnienia i stabilnych aktualizacji; wycena opcji opiera się na rozsądnych oszacowaniach zmienności; aktywa syntetyczne wymagają spójności wyceny w warunkach dużej zmienności. Te podstawowe potrzeby generują ciągły popyt na wysokiej jakości wyceny, co jest moją główną motywacją do inwestowania w badania i tworzenie. Wizja Pyth, zaczynając od DeFi, zmierza w kierunku szerszej usługi danych rynkowych; uważam, że to jest „trudna, ale właściwa droga”.
Dwa, operacyjna analiza produktów i architektury.
Zwykle dzielę każdy produkt danych na pięć segmentów: produkcja pierwotna, wiarygodne publikacje, agregacja weryfikacyjna, dystrybucja rozliczeniowa, optymalizacja feedbacku. W Pyth produkcja pierwotna pochodzi z giełd pierwszej linii, animatorów rynku i profesjonalnych dostawców danych; pełnią one rolę „wydawcy” na łańcuchu, każda wiadomość zawiera podpis źródłowy, co stanowi warunek możliwości śledzenia. Wiarygodne publikacje opierają się na Pythnet, gdzie następuje deduplikacja, czyszczenie, synchronizacja znaczników czasowych i obliczenia przedziałów ufności na podstawie danych z wielu źródeł. Po agregacji i weryfikacji, za pośrednictwem kanałów międzyłańcuchowych, aktualizacje cen są dystrybuowane do aplikacji na różnych łańcuchach; mechanizm „subskrypcji i żądań” pozwala użytkownikom decydować o częstotliwości wyzwalania na podstawie preferencji kosztowych i czasowych, co zmniejsza niepotrzebne transakcje i hałas na łańcuchu. Ten projekt łączy „szybkość” i „stabilność”, dwa pozornie przeciwstawne wskaźniki, w ramach jednego celu inżynieryjnego. Z mojego doświadczenia operacyjnego wynika, że deweloperzy, jeśli zrozumieją strukturę pól obiektów cenowych, precyzję czasową i przedziały ufności, mogą łatwo zakończyć integrację.
Poniższy diagram strukturalny przedstawia kluczowe węzły i punkty weryfikowalne danych od źródła do aplikacji, co ułatwia komunikację zespołową na temat szczegółów realizacji i granic.
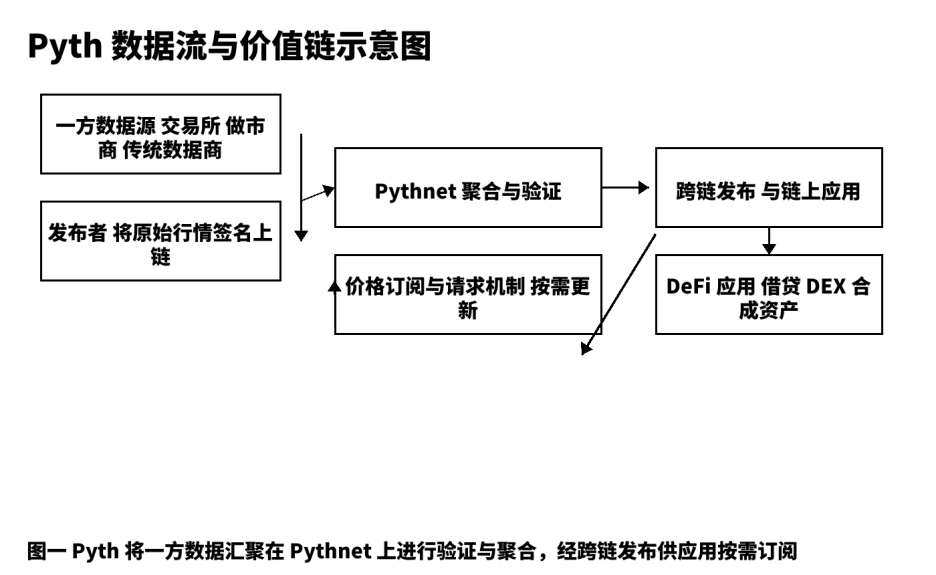
Trzy, pięciowymiarowe porównanie i wybór strategii.
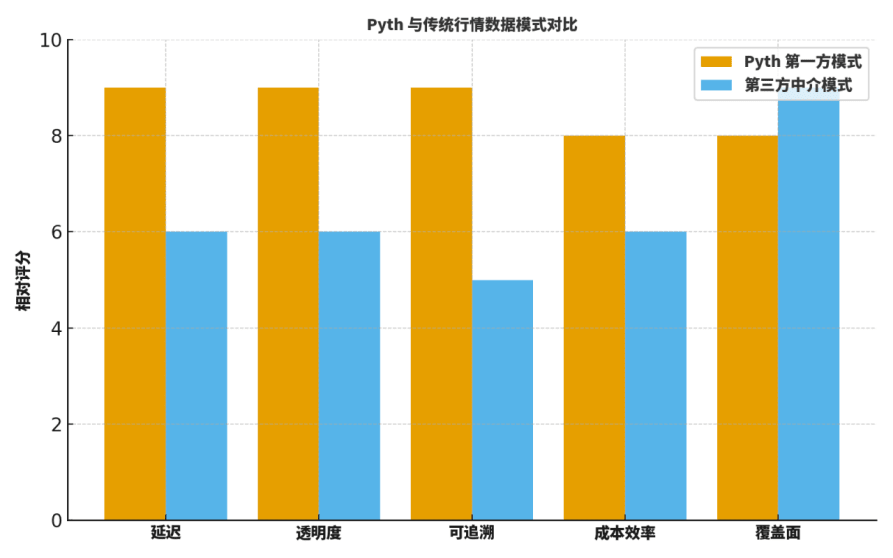
Wielu kolegów pyta: czym Pyth różni się od tradycyjnych „pośredniczących prognoz” lub uznawanych dostawców danych? Zwykle porównuję to z pięciu wymiarów: opóźnienie, przejrzystość, możliwość śledzenia, efektywność kosztowa, zasięg.
Po pierwsze, w aspekcie opóźnienia, prosto z pierwszej strony znacząco zmniejsza etapy pośrednie, co objawia się szybszymi aktualizacjami;
Po drugie, w aspektach przejrzystości i możliwości śledzenia, podpisy źródłowe i procesy agregacji do weryfikacji zapewniają szczegółową widoczność;
Po trzecie, w aspekcie efektywności kosztowej, eliminują ogromne koszty związane z zewnętrznym pozyskiwaniem i wielopoziomowym przekazywaniem;
Po czwarte, w aspekcie zasięgu, tradycyjni giganci nadal mają przewagę w historycznych kategoriach i rozkładzie geograficznym;
Po piąte, w zakresie współpracy inżynieryjnej, „subskrypcje na żądanie” Pyth sprzyjają sprzężeniu z parametrami ryzyka i systemem alarmowym.
Dlatego strategia nie jest „jednolita”, ale priorytetowo traktuje Pyth w kluczowych scenariuszach: pożyczki, rozliczenia, opcje, aktywa syntetyczne to obszary, które są dla mnie najważniejszymi „modelami do naśladowania” przy wyborze.
Aby pomóc czytelnikom zbudować intuicję, przedstawiam diagram „oceny względnej”, który nie jest absolutnym wnioskiem, ale bardzo nadaje się jako punkt wyjścia do dyskusji i szablon przeglądów.
Cztery, „drugi etap” na mapie drogowej: subskrypcje danych na poziomie instytucjonalnym.
W praktyce tworzenia treści i doradztwa podzieliłem trasę Pyth na dwa wzajemnie powiązane etapy:
Pierwszy etap, wokół szybko rozwijającego się scenariusza DeFi, ustanawia standardy wyceny, a kluczowymi elementami są jakość i szybkość;
Drugi etap, skierowany na produktowe „subskrypcje danych na poziomie instytucjonalnym”, obejmuje: umowy SLA dla poziomów opóźnienia, audytowalne logi, system etykiet anomalii skierowany na zarządzanie ryzykiem, modułowe interfejsy rozliczeniowe i uzgadniające itd.
Ten krok rozszerza zdolności inżynieryjne na zdolności usługowe: łączy sygnały cenowe z umiejętnościami organizacyjnymi w zakresie nadzoru, zgodności i zarządzania ryzykiem; wiąże również „zrównoważony dochód” z rzeczywistym zarządzaniem siecią. Szczególnie interesuje mnie, czy model usług powtarzalnych może działać, na przykład:
(1) oferowanie subskrypcyjnych planów z wieloma poziomami opóźnienia i częstotliwości aktualizacji;
(2) źródło każdej aktualizacji ceny, podpis, znacznik czasowy, lista wydawców uczestniczących w agregacji mogą być eksportowane i pozostawiać ślady;
(3) etykiety anomalii skierowane na zarządzanie ryzykiem, które mogą być odtwarzane, mogą być analizowane oraz mogą łączyć się z wydarzeniami ryzykownymi.
Te szczegóły decydują o tym, czy instytucja jest skłonna do migracji i w jakim stopniu jest gotowa płacić.
Pięć, użyteczność tokenów i zamknięta gospodarka.
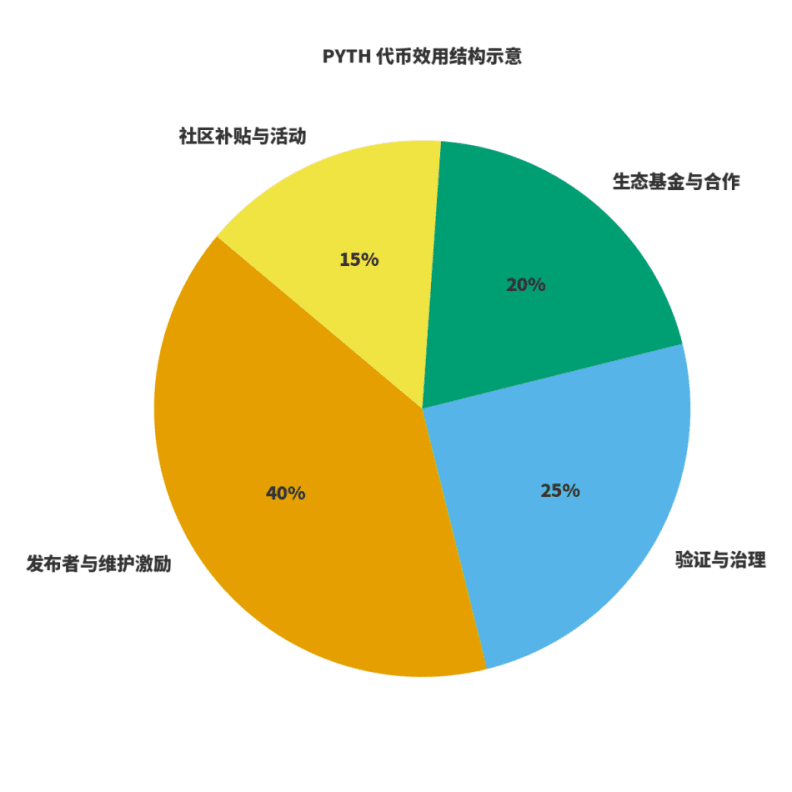
Aby ocenić, czy sieć jest zdrowa, należy zwrócić uwagę na dwie rzeczy: po pierwsze, czy dochody są związane z tworzeniem wartości; po drugie, czy bodźce są związane z długoterminową jakością. Dla $PYTH rozumiem to jako potrójną rolę: paliwo dla produkcji i utrzymania danych; waga dla zarządzania i weryfikacji; dźwignia dla rozszerzenia ekosystemu. Wydawcy i utrzymujący uczestniczą w sposób przewidywalny poprzez bodźce tokenowe; dochody sieci pochodzą z subskrypcji i użytkowania danych, a zarządzanie dystrybuuje dochody pomiędzy utrzymanie, bodźce i rozszerzenie ekosystemu. Na tej podstawie stworzyłem schemat „podziału użyteczności”, proporcje będą dostosowywane w miarę ewolucji zarządzania, ale zasada pozostaje niezmienna: publikacja i utrzymanie mają dużą wagę; zarządzanie i weryfikacja zapewniają stabilność; ekosystem i społeczność odpowiadają za rozszerzenie i przełamywanie granic.
Sześć, lista wdrożeniowa skierowana do instytucji.
Na podstawie wcześniejszych doświadczeń związanych z integracją, stworzyłem listę, którą można od razu wykorzystać:
Po pierwsze, określić zakres danych i granice usług: które są podstawowymi wycenami, a które należą do warstwy wartości dodanej;
Po drugie, zharmonizować umowy SLA: w tym opóźnienia aktualizacji, stabilność, przetwarzanie anomalii, strategie alarmowe i plany awaryjne;
Po trzecie, zapewnić audytowalne linie logów: rejestrować źródło każdej aktualizacji ceny, zmiany przedziału ufności i etykiety anomalii;
Po czwarte, zintegrować wewnętrzne ramy zarządzania ryzykiem i testowania wstecznego: włączyć strumień cen do systemu odtwarzania, aby sprawdzić stabilność strategii przy różnych progach i oknach;
Po piąte, ustandaryzować rozliczenia i uzgadnianie: instytucje bardziej interesują przewidywalne terminy płatności i jasne szczegóły uzgadniania.
Na tej liście, jawną przewagą Pyth jest „zweryfikowana agregacja od źródła”, co może znacząco skrócić okres oceny zgodności i zarządzania ryzykiem.
Siedem, mapa ryzyka i projektowanie odpornych systemów.
Dzielę ryzyko na trzy kategorie: anomalne publikacje ze źródła, anomalie synchronizacji między łańcuchami, amplifikację opóźnienia w ekstremalnych warunkach rynkowych. Odpowiednie środki łagodzące muszą zostać „usankcjonowane” w inżynierii. Moje powszechne praktyki obejmują: subskrypcję wielokanałową z weryfikacją progową; automatyczne obniżanie dźwigni powiązane z przedziałami ufności; czasowe ważenie i ochronę przed poślizgiem po stronie umowy handlowej; oraz ćwiczenia ekstremalnych warunków rynkowych przeprowadzane co kwartał, z towarzyszącymi jednolitymi skryptami do odtwarzania i szablonami przeglądów. Te rodzaje zdyscyplinowanej praktyki inżynieryjnej, w połączeniu z weryfikowalnymi dziennikami Pyth, mogą znacząco zwiększyć odporność systemu.
Osiem, sugestie narracyjne dla twórców treści i deweloperów.
Zawsze podkreślam: wartość twórcy polega na tym, że tłumaczy złożoną wartość inżynieryjną na język, który czytelnicy i użytkownicy mogą „zrozumieć i wykorzystać”. Jeśli chodzi o Pyth, sugeruję zacząć od „zmiany paradygmatu”, a nie zatrzymywać się na „sporze o prognozy”. Mówić o tym, jak łączy stronę podaży i popytu w sposób audytowalny na łańcuchu; mówić o tym, jak dzięki przedziałom ufności i wizualizowanym procesom agregacyjnym zmniejsza ryzyko końcowe; mówić o tym, jak poprzez „subskrypcje na poziomie instytucjonalnym” łączy zdolności usługowe z zamkniętymi cyklami biznesowymi. To bardziej przekonywujące niż ogólne wymienianie wskaźników.
Dziewięć, wskaźniki, które będę śledzić w nadchodzącym roku.
Po pierwsze, szerokość i głębokość integracji ekosystemu: cztery główne kategorie projektów w zakresie pożyczek, aktywów syntetycznych, opcji i indeksów;
Po drugie, postęp w produktach subskrypcyjnych dla instytucji: poziomy opóźnienia, umowy SLA, czy audytowalne logi są aktualizowane na czas;
Po trzecie, przejrzystość dochodów i podziału w protokole: czy utworzyły się publicznie weryfikowalne dane;
Po czwarte, postępy w zakresie zgodności w różnych jurysdykcjach: w tym zgodność w zakresie eksportu danych i usług finansowych.
Te wskaźniki bezpośrednio wpłyną na moje wybory i tempo w zakresie treści, a także na moją długoterminową ocenę wartości PYTH.
Dziesięć, przewodnik dla deweloperów: od zera do jednego.
Aby pomóc nowym partnerom w szybszym postępie, przedstawiam zestaw wykonalnych „trzech kroków”.
Pierwszy krok, zakończyć jedną wywołanie subskrypcji cen w środowisku testowym; zrozumieć strukturę cen, precyzję czasową i pola przedziału ufności;
Drugi krok, wkomponować „subskrypcje i strategie żądania” w kontrakt lub robota handlowego, porównać różne progi i okna w systemie testów wstecznych;
Trzeci krok, zintegrować monitoring alarmów; ustawić progi alarmowe na podstawie wskaźników zarządzania ryzykiem i włączyć etykiety anomalii do odtwarzania i analizy.
Gdy ukończysz te trzy kroki, nie tylko zaczniesz korzystać z Pyth, ale także wprowadzisz ideę „zweryfikowanych danych” do kodu.
Jedenaście, porównanie branżowe i przestrzeń współpracy.
Nie popieram myślenia zerowej sumy „zysku i straty”. W scenariuszach o szerszym zasięgu, ale mniej rygorystycznych wymaganiach czasowych, tradycyjni dostawcy danych nadal mają przewagę; natomiast w scenariuszach, gdzie opóźnienie i weryfikowalność są niezwykle wrażliwe, model danych pierwszej strony Pyth ma większą szansę na sukces. W przyszłości bardziej oczekuję, że deweloperzy w modułowy sposób połączą różne źródła strumieni danych, dokonując dynamicznego bilansu między kosztami a wydajnością w oparciu o funkcję celu.
@Pyth Network #PythRoadmap $PYTH
