The week that changed my view on ROBO was the one where an urgent task sat for 11 minutes even though the queue looked full of available supply.
Nothing was down. Plenty of operators were technically online. The task still closed. But the first touch came from the same small responder cohort that always seemed to appear when timing actually mattered. A week later we stopped staring at the queue and started tracking 2 things instead. 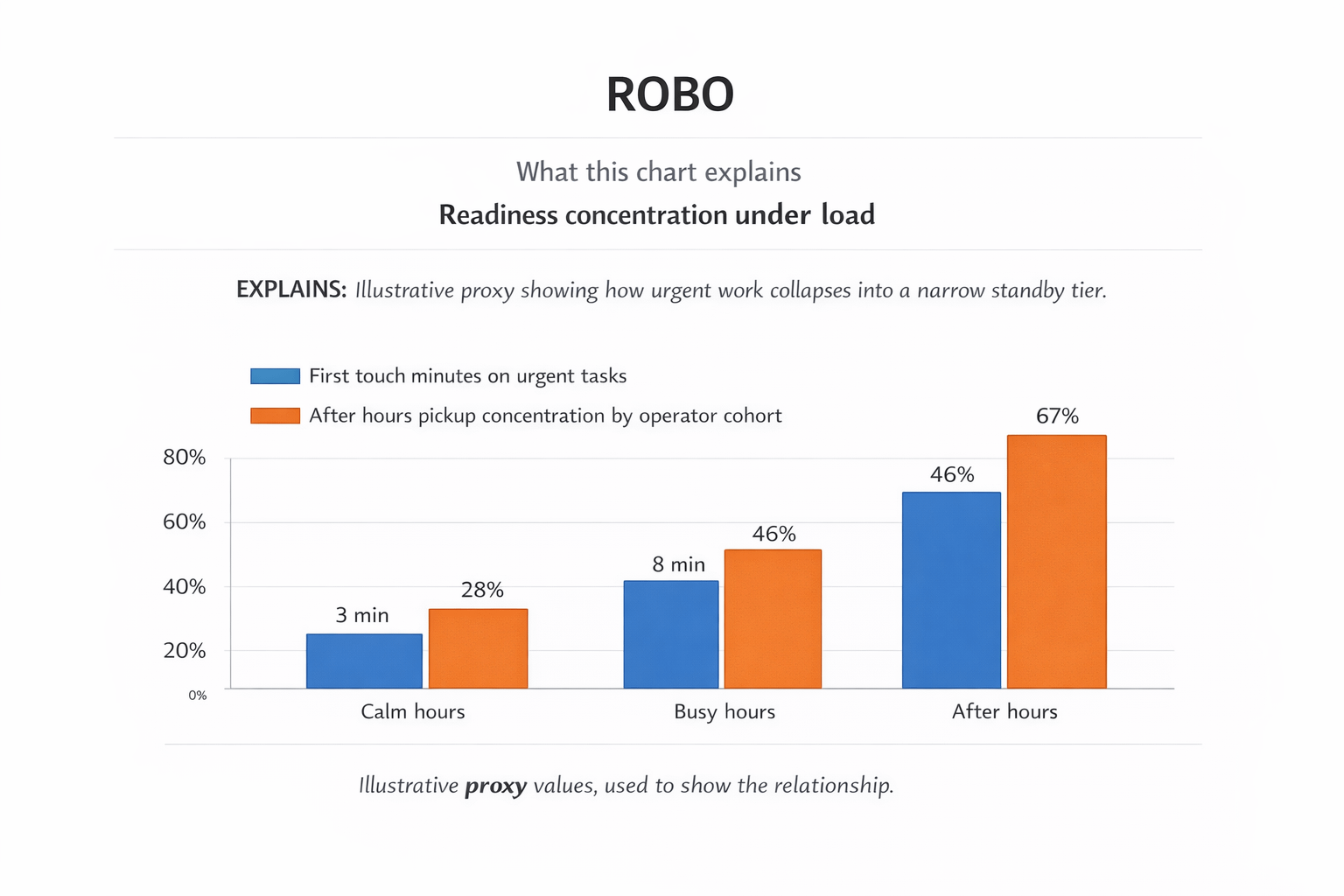
First touch minutes on urgent tasks. After hours pickup concentration by operator cohort. Both pointed in the same direction. The queue looked public. Readiness did not.
That was when idle capacity stopped looking like waste to me.
On ROBO, readiness is not empty time. It is reserved capacity.
That is the only lens I care about here.
A shared work surface only feels shared if ordinary integrations can get timely execution without quietly building a side roster of people who stay warm. The moment important work depends on a small standby tier, the network is still open on paper, but the service layer has already moved somewhere else.
A network that cannot pay for standby will recreate it privately.
That is the whole problem.
Fast pickup does not happen because somebody becomes motivated at the perfect minute. It happens because somebody was already carrying slack. A runner was warm. Tool access was live. Attention was sitting close to the queue. That capacity could have been used somewhere else, or not held at all. Instead it was being reserved in advance for work that might show up and might not.
That is not free effort. It is inventory.
The moment some tasks become sensitive to first touch time, that inventory matters. Some work is still fine if it gets picked up in 20 minutes. Some work is not. Once that difference exists, the system has created a premium for availability whether it admits it or not. If the protocol does not name that premium, it does not disappear. It gets paid by whoever is willing to stay ready and hope the queue pays them back later.
Queues rarely pay that cost back evenly.
That is why the same names start showing up on the work with the least tolerance for delay. Not always because they are the best overall. Because they are the ones carrying enough slack to respond without hesitation.
This is where the public story starts drifting from the operational one.
The public story says the queue is open.
The operational story says urgent work already has a preferred tier.
You can see the coping layer form in the same order every time. A standby roster appears in a runbook. A preferred responder list starts shaping urgent work. Coverage windows get written down because available stops meaning much. Rules for work outside normal hours show up because nobody trusts raw queue visibility to tell them who can really move now.
None of this looks dramatic. It looks like operations getting practical.
But this is also the moment where infrastructure starts being rebuilt privately.
That is why I do not read idle capacity as a staffing issue. I read it as a coordination issue.
If ROBO cannot make the cost of readiness legible, serious integrations will make it legible themselves. They will route important work to the operators with the best response history. They will avoid the broad public lane for anything time sensitive. They will stop asking who is technically eligible and start asking who is actually warm.
That is how a network that looks broad ends up feeling narrow.
The queue can still be full. Participation can still be open. But the real question becomes who can pick up immediately without rebuilding context, waking a human, or reestablishing tool access. Once that question matters enough, work is no longer being allocated only by skill or eligibility. It is being allocated by standby capital.
And standby capital concentrates.
The operators who can afford it get more of the high value work. The high value work gives them more reason to preserve slack. Everyone else sees the pattern and either accepts the long tail or tries to join the same availability game. Over time the system starts teaching a very simple lesson.
Being ready matters more than merely being present.
That is not automatically bad. Some work should reward fast readiness. The problem starts when the cost of maintaining that readiness stops being a public design choice and becomes a private tax.
Then service guarantees drift out of the protocol and into relationships.
You can see the bill in places dashboards usually flatten. Response time variance on urgent tasks. Dependence on the same names when work arrives outside normal hours. Escalation minutes before first touch. The share of workflows that quietly depend on a preferred responder list even though the network is supposedly open.
Those are not side details. That is the real service layer.
If ROBO wants to feel like common infrastructure, it has to decide whether standby is something the network recognizes and pays for, or something the ecosystem is forced to improvise around. Because if it is improvised, it will not stay neutral. It will become a soft moat. A small group of operators will become the practical entry point for urgent work, and everyone will pretend that is still the same thing as broad participation.
It is not.
If urgent work needs a roster, the queue is not the service layer.
That is where the token becomes concrete for me.
$ROBO matters here only if it can help fund readiness in the open instead of leaving it to private side deals. As operating capital for standby capacity, response guarantees, and the reliability layer that keeps urgent work from collapsing into a preferred responder club. If that cost is not carried publicly, it will still be paid. Just not by the protocol. It will be paid through hidden rosters, soft exclusivity, and the same small set of operators quietly becoming the service layer everyone depends on.
The only way I would judge this later is by watching what operators stop building around.
Urgent work should stop falling into the same small standby tier.
Coverage outside normal hours should stop depending on the same names.
Serious integrations should stop maintaining side rosters just to get reliable first touch.
If those behaviors stay, the queue is still public and the service layer is still private.
If they fade, ROBO is finally paying for readiness in the open instead of asking operators to finance it off the books.
That is the point where idle capacity stops looking inefficient and starts looking like what it was all along.