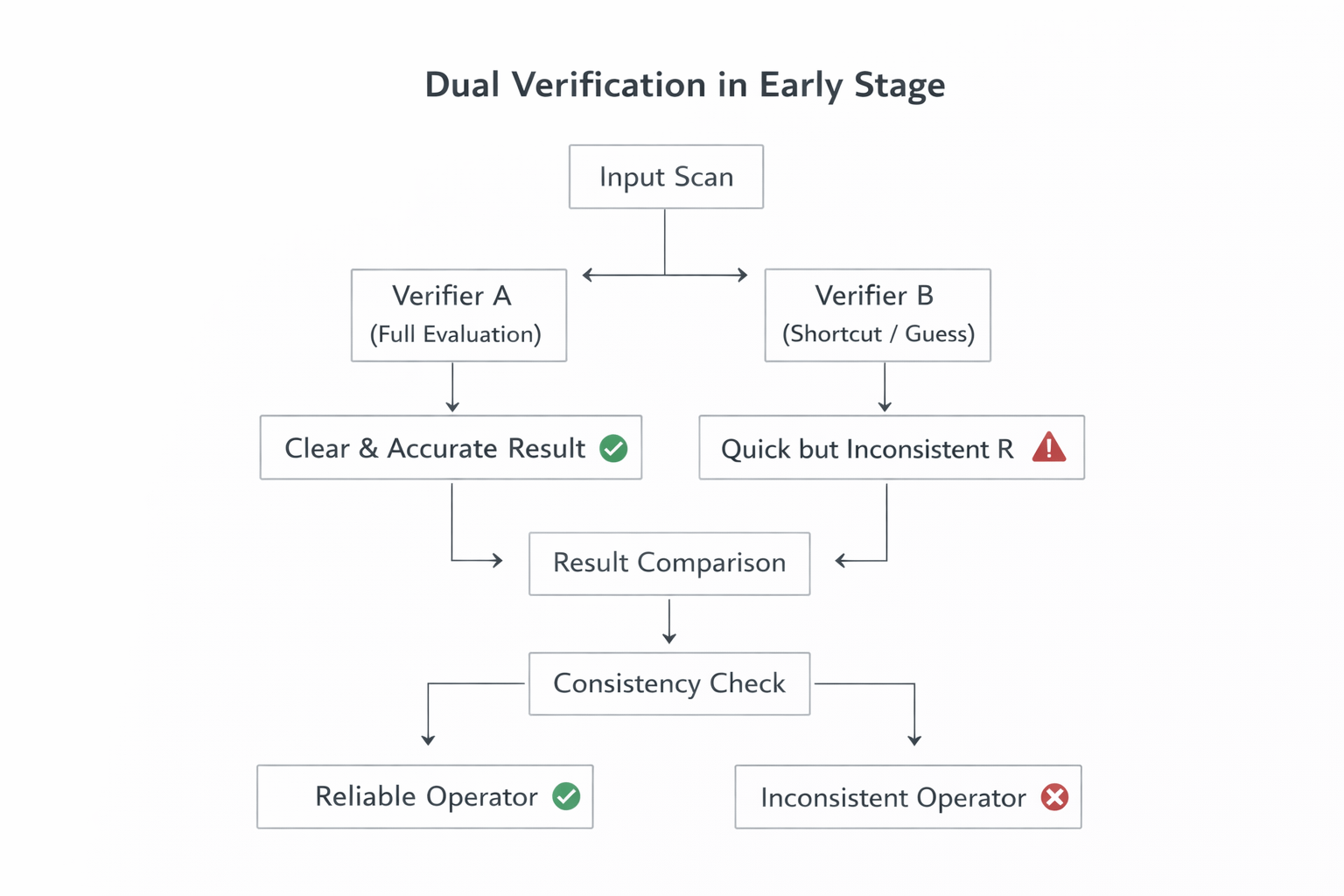
I started paying closer attention to MIRA when I saw how explicitly it treats early verification. Instead of assuming every operator will behave honestly from day one, it appears to accept a more practical premise. Some participants will cut corners if the system makes that easy.
That matters because a lot of the discussion around decentralized AI infrastructure still gravitates toward scale, speed, and open participation. The louder argument is usually about how fast a network can grow. The harder question is what happens when the cheapest path for a node is to bluff, stall, or recycle shallow work.
What MIRA’s approach signals to me is a more operational view of trust. Running duplicate verifier instances is expensive. It slows the clean narrative. But it also creates an early filter for lazy or adversarial behavior before that behavior hardens into network culture. That is not a growth trick. It is quality control.
How This Works in the Real World.
Think about a hospital using an AI system to verify whether a scan should be flagged for urgent review. If two operators are assigned the same verification task, one may carefully run the full process while another may rush, guess, or rely on shortcuts just to collect rewards faster. In a system optimized too early for cost and speed, both outputs can look equally valid on the surface. But if MIRA deliberately runs duplicate verifier instances in the early stage, it becomes much easier to spot which operator is consistently doing the work and which one is simply coasting on probability. That is what makes the design feel production-minded: it treats verification less like a demo metric and more like a real operational control.
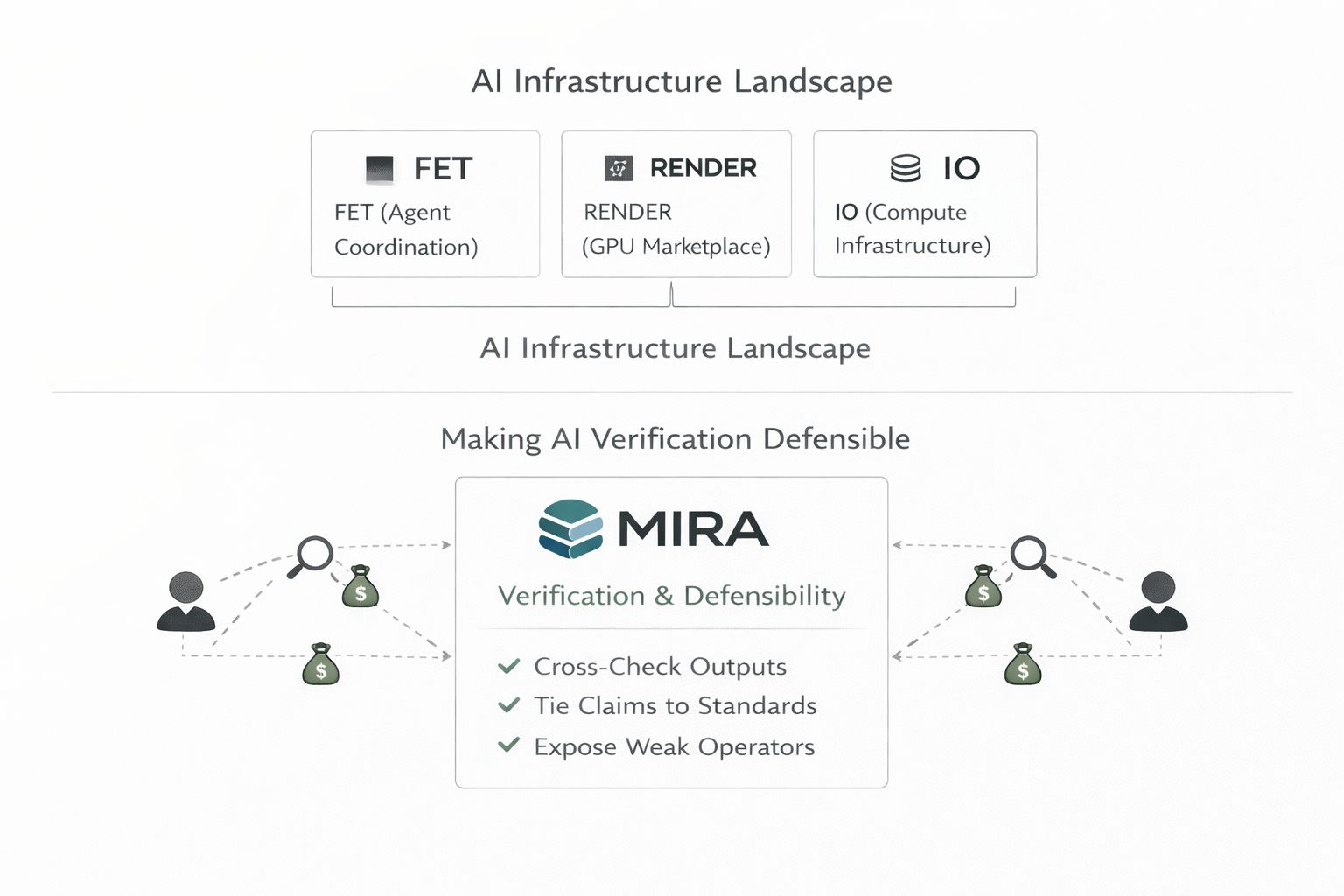
Compared with AI infrastructure names like FET, RENDER, and IO, $MIRA looks less focused on broad agent coordination, GPU marketplace demand, or raw compute aggregation and more focused on whether verification itself can remain honest under incentives. FET ($FET ) is closer to the agent and orchestration layer, RENDER ($RNDR ) is tied more directly to decentralized GPU supply and compute demand, and IO is positioned around distributed compute infrastructure. MIRA sits in a stricter lane. Its emphasis is on turning outputs into standardized claims, checking them across distributed verifiers, and using economic design to expose weak or lazy operator behavior early. That makes the category split clearer: others are helping AI scale, route, or run, while MIRA is trying to make AI verification defensible.
Right now, much of the sector still feels like a factory line chasing output targets while inspection is treated as a future software update. Everyone wants more throughput. Fewer teams want to fund discipline while the numbers still look small.
The network MIRA describes is effectively warning against premature efficiency. Imagine a verification workflow where two operators review the same binary task, one actually runs the model, the other guesses and submits quickly, hoping variance hides the shortcut. If the network only rewards speed, the lazy path scales. If the network deliberately duplicates checks, that pattern becomes visible. What it is building instead is controlled behavior, measurable reliability, and an audit trail around effort.
This signals a move from cheap verification to accountable verification.
The market usually reacts coldly to that kind of design because redundancy looks like waste in the early phase. It adds cost before it adds spectacle. It does not produce the kind of dashboard metrics that momentum traders love. It can even look inefficient compared with networks that expand faster on paper. That reaction is normal. Markets often discount safeguards until failure makes them legible.
But the logic behind MIRA’s model holds. The first buyers who care are not tourists. They are teams that need verification they can defend internally: enterprise operators, model marketplaces, compliance-heavy deployments, and any workflow owner who cannot afford probabilistic honesty. These users do not want the cheapest verifier if the cheapest verifier quietly corrupts the result.
Over the next 8 to 18 months, I think this becomes harder to ignore. As agentic systems move closer to real financial, legal, and operational workflows, networks will be judged less by how broadly they distribute participation and more by how consistently they detect weak behavior under load. At that point, duplication will not look like overhead. It will look like underwriting.
And that is where institutional trust gets priced. Not in the promise of open verification, but in the discipline to prove that verification can withstand incentives.
@Mira - Trust Layer of AI #Mira
