While studying how Mira’s verification network works, one detail keeps pulling my attention back. It’s not necessarily a flaw, but it is something I’m still trying to fully make sense of.
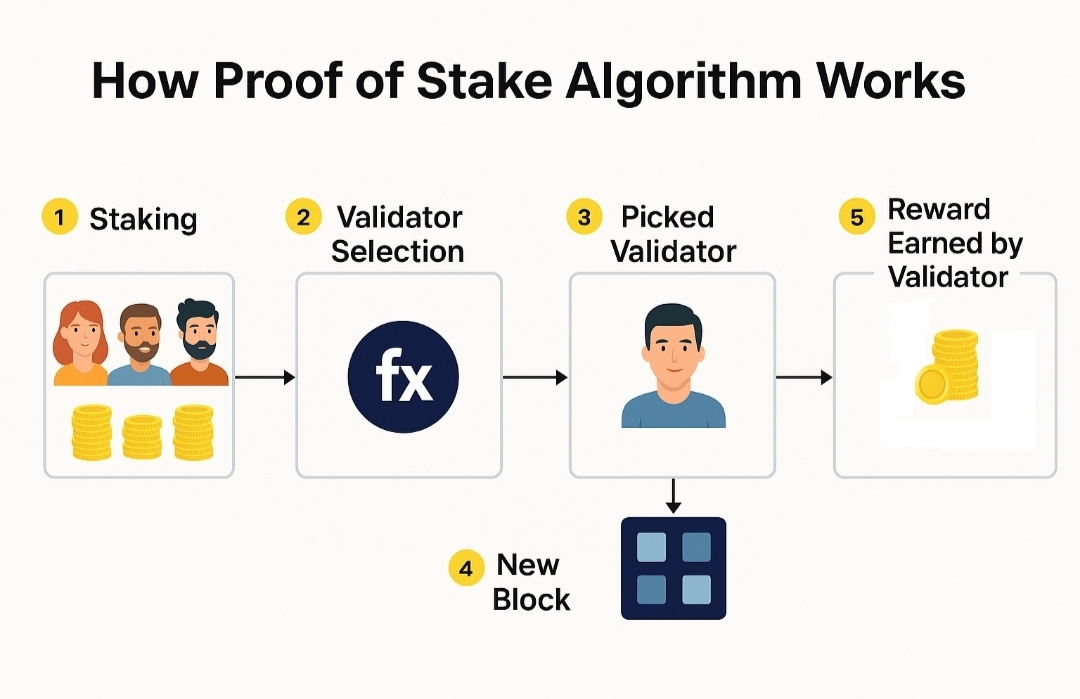
Mira relies on a stake-weighted consensus model to verify claims produced by AI systems.
The basic idea is fairly intuitive.
Validators place stake behind claims they believe are correct. If enough stake accumulates behind a particular outcome, the network accepts that result as verified. Validators who supported the correct outcome are rewarded, while those who backed incorrect claims risk losing part of their stake.
In theory, this mechanism introduces accountability.
When people have capital on the line, they tend to think carefully before committing to a decision. The economic pressure encourages participants to act honestly and evaluate claims more rigorously.
That logic is sound.
But while thinking through this model, one scenario keeps surfacing in my mind.
What happens when the minority position is actually the correct one?
History shows that the correct answer does not always begin as the popular one.
Many breakthroughs initially appeared incorrect or unrealistic to the majority. Scientific discoveries, unconventional investment theses, and even early conversations around Bitcoin were once dismissed by most observers.
At the beginning, the crowd often disagrees with the truth.
Now imagine a validator reviewing a claim that contradicts what most of the network appears to believe.
Even if the validator suspects the claim might be correct, another question immediately enters the equation:
Is it worth risking my stake if the rest of the network disagrees?
This shifts the decision from a purely intellectual judgment into an economic calculation.
Instead of only asking “What is correct?”, validators might also ask “Where is the majority leaning?”
And that distinction matters.

Because financial risk naturally influences behavior.
Losing stake carries real consequences, and rational actors tend to protect themselves from unnecessary losses. That could encourage validators to watch the broader network’s direction before committing their capital.
Not because they intend to manipulate outcomes, but simply because economic incentives shape decisions.
This creates an interesting dynamic inside the system.
Mira’s goal is to verify the reliability of AI outputs essentially trying to establish a layer of machine-verified truth.
Yet the incentive structure could sometimes reward something slightly different: correctly anticipating consensus.
In many cases, those two outcomes will likely align. If most validators independently reach the same conclusion, it often means the answer is genuinely correct.
But there may also be moments where the two diverge.
Situations where the truth sits with a smaller group, while the majority leans the other direction.
That tension doesn’t necessarily invalidate Mira’s design. In fact, it highlights how difficult the underlying challenge really is.
Creating intelligent systems is already complex.
Designing networks capable of evaluating and verifying intelligence may be an even harder problem.
And that’s why this question keeps lingering in my mind.
Not as a criticism, but as a reminder that building trust infrastructure for AI will involve trade-offs we’re only beginning to understand.
For now, I’m still thinking through it.