
I keep landing on the same thought: data quality is not really about whether a file looks neat or a benchmark score looks impressive. What makes me trust data is being able to see where it came from, who handled it, and what changed along the way. That is why the idea of “Trust Tags” in the Fabric Protocol interests me. Public material around Fabric keeps stressing machine identity, observable behavior, task accountability, and payments for robots and AI agents, so I read Trust Tags as a natural extension of that same logic: a way to attach signed, inspectable claims to data, not just to machines.

I find it helpful to think of a Trust Tag less as a seal of truth and more as a chain-of-custody note. In the same way that C2PA’s Content Credentials are described as a kind of nutrition label for digital content, a trust tag for data would tell me what I am looking at, who is standing behind it, when it was created, how it was changed, and what sort of review or attestation it has gone through. That framing matters. It lowers the ambition from “prove this data is perfect” to something more realistic: “make the history visible enough that people and systems can judge quality with better evidence.” That is also where the wider standards conversation is heading. OASIS is now working on cross-industry standards for provenance, lineage, and metadata tagging, and NIST’s generative AI profile explicitly calls for documenting training data sources so provenance can be traced.
If a public ledger sits beneath this system, I do not see much value in storing whole datasets there. What feels more credible to me is using the ledger for compact, durable proofs—hashes, signatures, timestamps, the identities of people or systems making attestations, records of challenges, and changes in status—while the underlying files remain off the ledger. That pattern already shows up in ledger systems. Hyperledger Fabric describes a ledger as a place that stores facts about objects and the history of transactions around them, rather than the objects themselves, and AWS’s documentation for private data on Fabric notes that only a hash may be sent through the shared ordering path while the underlying private data stays off the main ledger. In other words, the ledger is there to preserve the claim trail. The data itself can remain private, large, or changeable without losing the audit record.
What makes this feel current, rather than like another old blockchain thought experiment, is the mix of pressures building at once. Fabric’s own foundation argues that AI is moving out of the digital realm and into the physical world, where safety, resource limits, and human interaction matter more. At the same time, Circle is starting to talk openly about tiny machine-to-machine payments through OpenMind as a real use case for autonomous systems. Around it, the wider provenance space is also moving in the same direction, trying to set clearer standards for showing where content came from and who made it before synthetic media and automated decisions become even harder to examine. A few years ago, this still would have felt mostly theoretical. Now it feels less like a distant idea and more like something slowly taking shape, even if not all at once.
Still, I do not think Trust Tags solve the hardest part by themselves. A tag can confirm that a dataset came from an identified sensor, that a named reviewer checked a file, or that a model used a declared source in training. But it still cannot magically tell us that the source was honest or that the reviewer was actually competent. That limitation is already visible in neighboring provenance systems. The Washington Post found that major social platforms stripped or hid Content Credentials from a test AI video, and The Verge has reported that interoperability gaps, missing device support, and even simple screenshots can break the chain people are supposed to trust. So the real test is not whether trust tags can exist. It is whether platforms, operators, and users will preserve them, display them, and treat them as something worth checking.
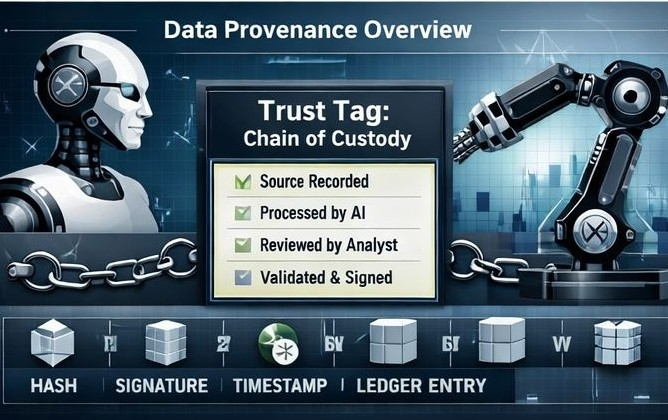
Even with that caveat, I think the idea is sound because it moves trust away from vague branding and toward explicit claims. Instead of saying “this is high-quality data,” a system could say: collected by this device, at this time, under this calibration, reviewed by these parties, challenged once, corrected twice, and last refreshed yesterday. That feels more honest to me. In the Fabric view of the world, where machines need identity, accountability, and a way to participate economically without becoming legal persons, a visible and contestable record of data quality fits the problem better than a hidden database note. I used to think public ledgers were most interesting when they tried to replace institutions. Here I think they are more useful when they force institutions, tools, and machines to leave a cleaner trail. A Trust Tag, at its best, would not tell me what to believe. It would give me a better basis for deciding.
@Fabric Foundation #ROBO #robo $ROBO
