@Mira - Trust Layer of AI I did the 6:48 a.m. kitchen counter edit with my laptop balanced like a bad life choice while the kettle clicked off as if to judge me and then I saw a sentence casually name drop a statute number and my brain went “Cool is that an actual law or did someone just freestyle with authority” which is the moment I realized I am tired of guessing and I am tired of deciding who to trust.
That small moment is why “AI reliability” has stopped feeling abstract to me because I do not mind an assistant that helps me outline or rephrase but the moment a system starts supplying facts it becomes part of my work’s evidence chain. More teams are pushing models beyond chat and into workflows that act on the world so the risk is not theoretical because a model can say something plausible while I am busy and the mistake can slip through.
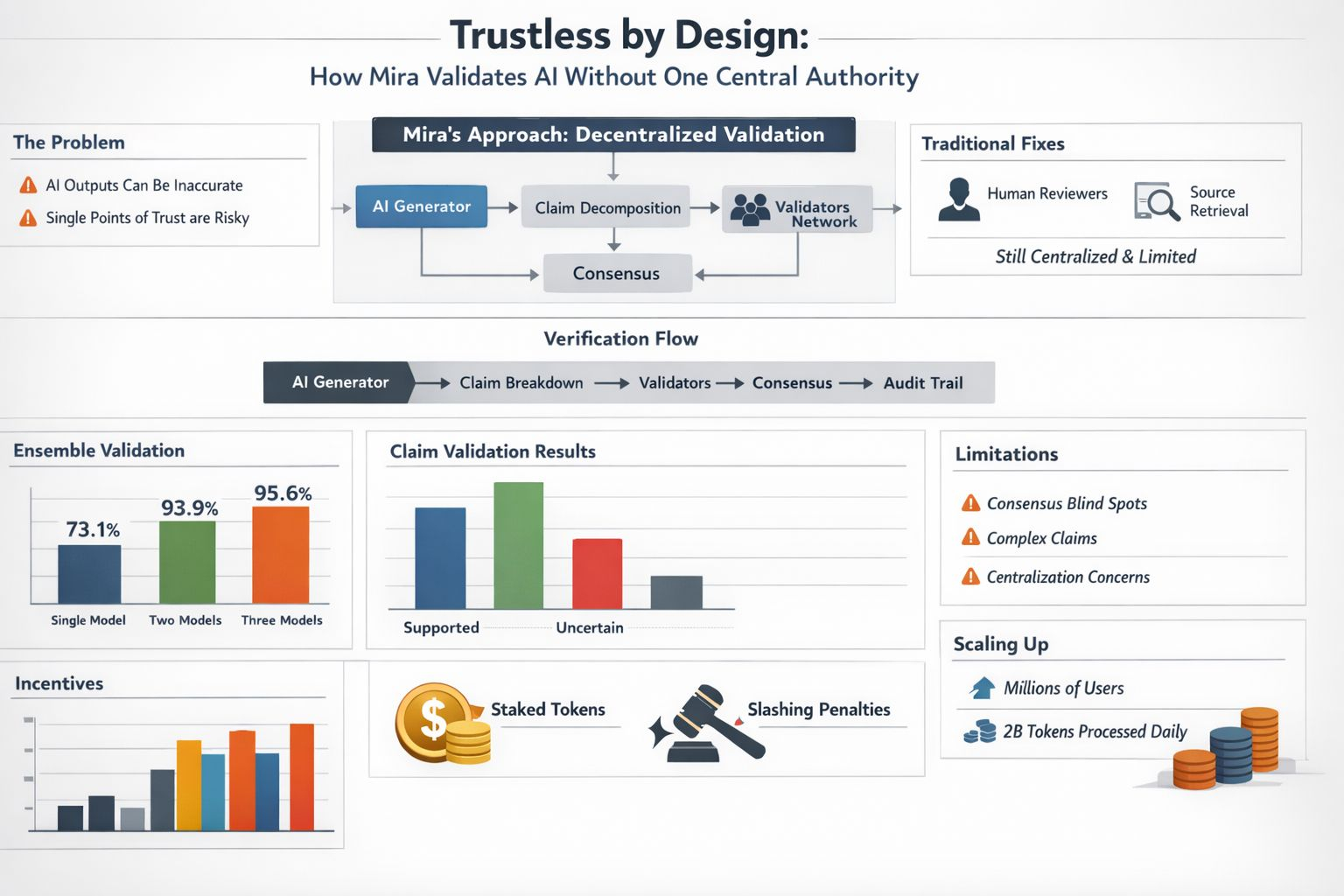
The usual fixes are familiar and I use them too. People add a human reviewer or they bolt on retrieval so the model can quote a source and both approaches help while still concentrating trust in one place such as a single model provider a single index or a single overworked person who cannot check everything. When an output will be reused downstream I want a way to validate it that does not depend on one central authority being careful or even available.
Mira’s approach is to make verification a property of the system rather than a promise. In its own compliance documentation Mira describes a decentralized verification model where outputs are broken into structured claims and independently validated by multiple AI models and consensus is used to verify AI outputs without relying on human oversight. That description matters because it shifts the unit of work so instead of asking whether a whole answer is “good” I can ask whether each claim is supported rejected or uncertain.
I find the mechanics easier to grasp if I picture a jury rather than a referee because one model generates text and then validators running different models check the decomposed claims and vote. Mira Verify which is the company’s API product frames this as multiple specialized models cross checking each other and producing an auditable record from input to consensus. Even if I never inspect every detail the existence of a trace changes how I think about accountability because if something goes wrong I can ask what the validators saw rather than only what the generator said.
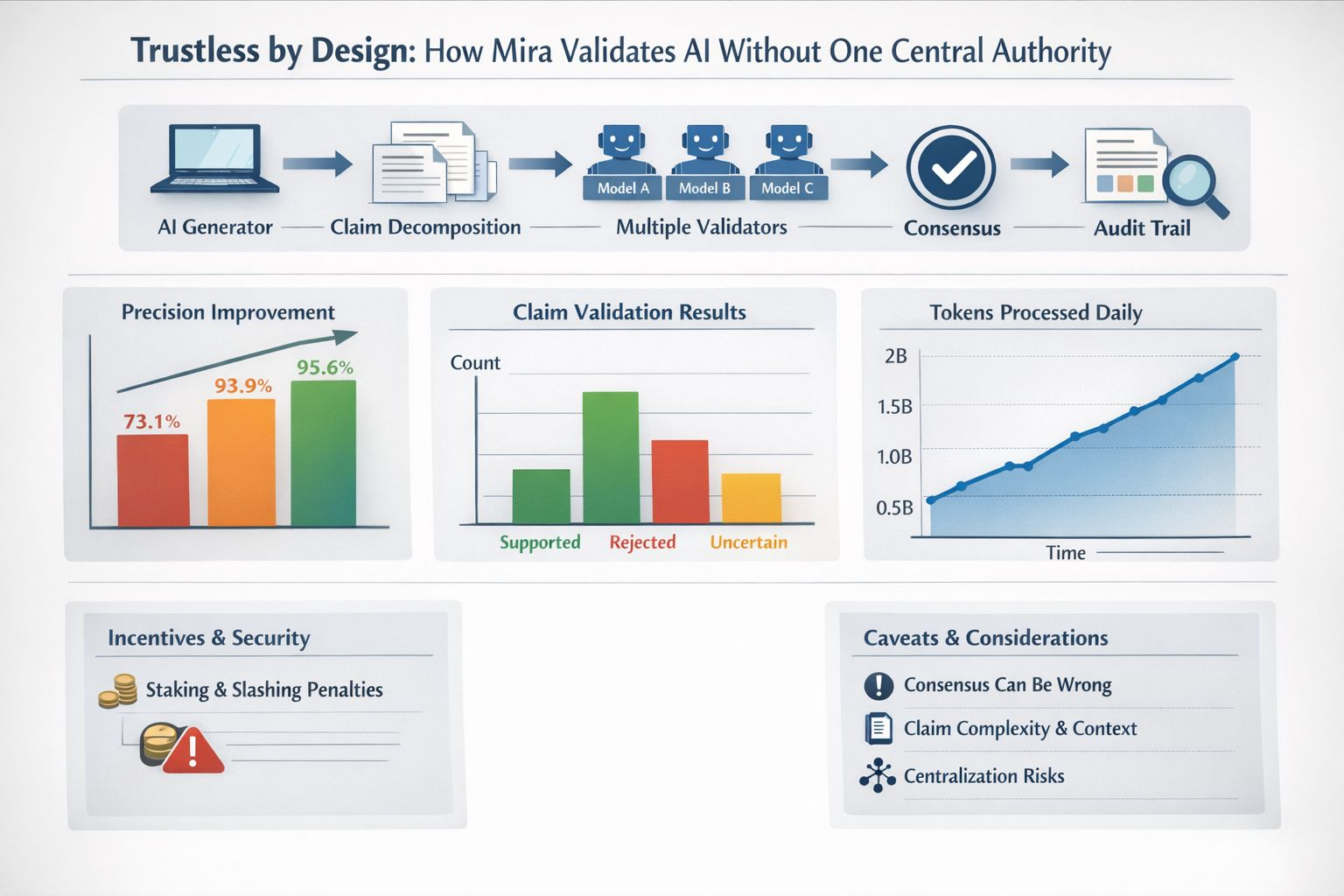
The “trustless” part is not only philosophical because Mira pairs the validation flow with incentives. Node operators stake value to participate and face slashing penalties for incorrect assessments while using a hybrid delegated Proof of Stake and Proof of Work model. I do not treat token economics as a magic shield but I like the direction since it acknowledges that verification can be attacked and that “please behave” is not a security model.
I also appreciate that consensus checking is starting to look like a normal reliability technique rather than a niche idea. Academic work on ensemble validation makes a similar point because in one study of 78 complex cases precision rose from 73.1% to 93.9% using two models and to 95.6% using three. Those numbers will not map neatly onto my memo but they match my lived experience because disagreements between competent systems are often where the errors hide.
Still I do not want to pretend consensus equals truth because if every validator shares the same blind spot then a supermajority can be confidently wrong. Claim decomposition can also be messy since real writing bundles context and hedged language that does not reduce neatly to true or false. Any network also invites governance questions about who selects validators how diversity is measured and what happens when incentives reward speed over care. Mira’s own documentation even notes centralization realities in the underlying chain infrastructure including the current use of a centralized sequencer on Base so trustless design is a direction rather than a switch.
What keeps me interested is progress from concept to throughput because Mira has publicly reported growth to millions of users and two billion tokens processed daily across its ecosystem applications. I read that less as a milestone and more as evidence that verification can survive contact with latency cost and scale.
Right now the wider reason this is trending is simple because AI is moving from answering questions to making calls. As that happens my tolerance for opaque confidence drops fast since I do not need a magic truth machine and I do need something transparent that shows the steps spreads the trust and flags the shaky bits. Used right it becomes a quality gate before I publish or push changes so if Mira and others in that lane keep embedding verification into the underlying systems then I can stop burning time on “is this even true” and spend it on “okay so what now”.