For a long time, the conversation about artificial intelligence has been dominated by one question: How accurate is the model? Researchers measure it with benchmarks, developers publish evaluation scores, and companies present impressive percentages to demonstrate reliability. Those numbers create a comforting narrative. If the model performs correctly most of the time, then we assume it can be trusted when it is deployed in the real world.
But something strange has been happening inside organizations that actually use AI for important decisions. Systems perform well on paper. The outputs are often correct. The internal validation steps appear to work exactly as designed. And yet, when a regulator, auditor, or legal team starts asking questions about a particular decision, the organization suddenly realizes it cannot fully explain what happened.
Not because the answer was wrong. Because the process cannot be reconstructed.
Accuracy and accountability turn out to be two very different things.
A model can generate the right answer, but if nobody can prove how that answer moved through the system, who checked it, or whether any safeguards were applied before it was used, then the decision becomes difficult to defend. In many industries that is a serious problem. Banks, hospitals, insurance firms, and government agencies are not just expected to make good decisions. They are expected to demonstrate how those decisions were made.
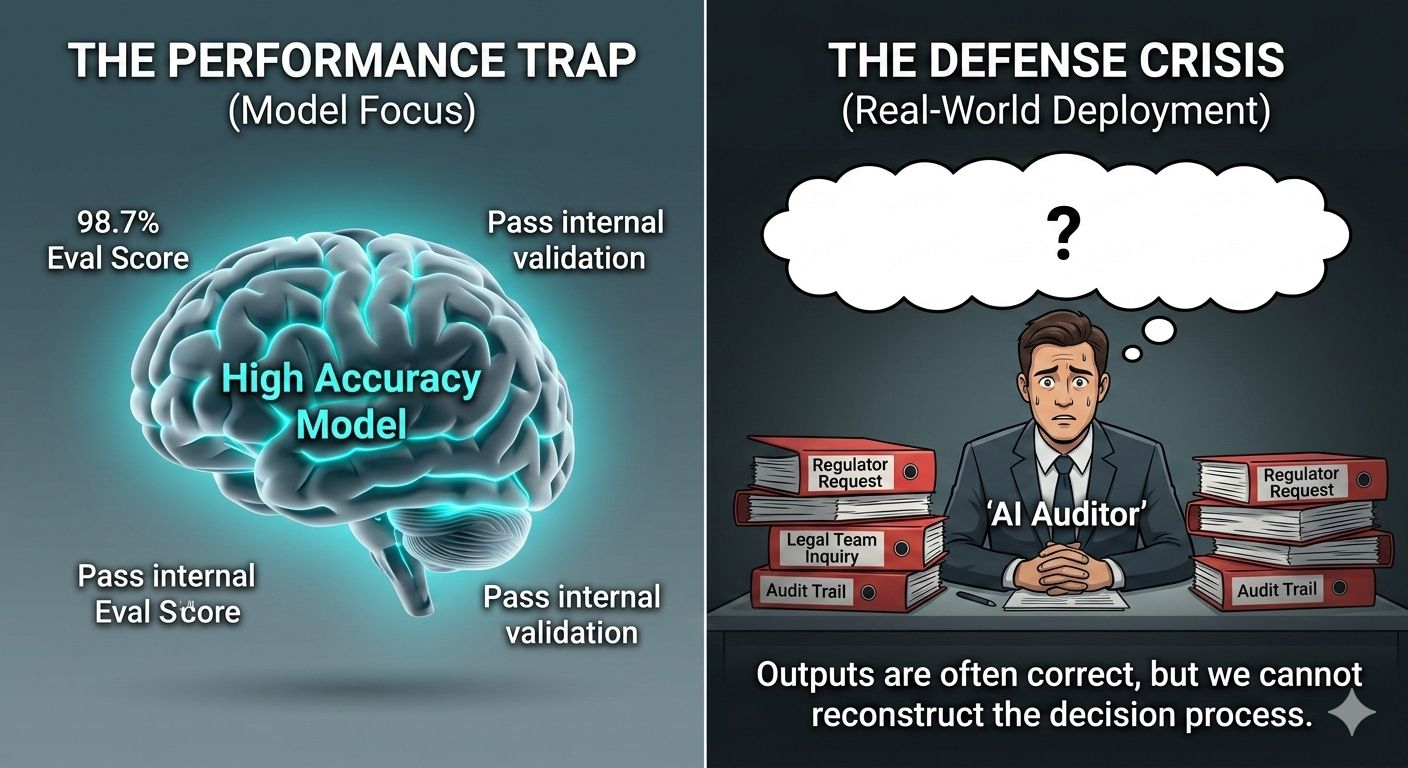
This gap between correct answers and defensible decisions has quietly become one of the most important structural problems in modern AI deployment.
The idea behind Mira Network starts from that uncomfortable reality. At first glance, it might look like another attempt to improve AI accuracy by having multiple systems verify each other. That is part of the story, but it is not the most interesting part. The deeper goal is to treat AI outputs less like casual responses and more like inspectable records.
To understand the logic behind this, it helps to think about how quality control works in industries that cannot afford ambiguity. Imagine a factory producing aircraft components or medical devices. Engineers do not simply say that the machines are calibrated correctly on average. Every individual unit that leaves the production line can be traced. Inspectors check it. Records are created. If a problem appears months later, investigators can follow the trail backward and understand exactly where things went wrong.
Artificial intelligence has not historically worked that way. Models generate answers continuously, often at massive scale. The output appears on a screen, someone uses it, and the system moves on to the next query. If a problem emerges later, organizations can show general documentation about the model and its training process, but they cannot always show what happened to the specific output that caused the issue.
That is the gap Mira’s architecture is trying to close.
Instead of letting an AI output travel directly from model to user, the system treats it as a claim that needs to be checked. The claim moves through a network of validators, each evaluating it independently. Once enough validators reach agreement, the network produces a cryptographic certificate that essentially says: this output was examined, these validators participated, this was the level of agreement, and this is the exact version of the answer that was approved.
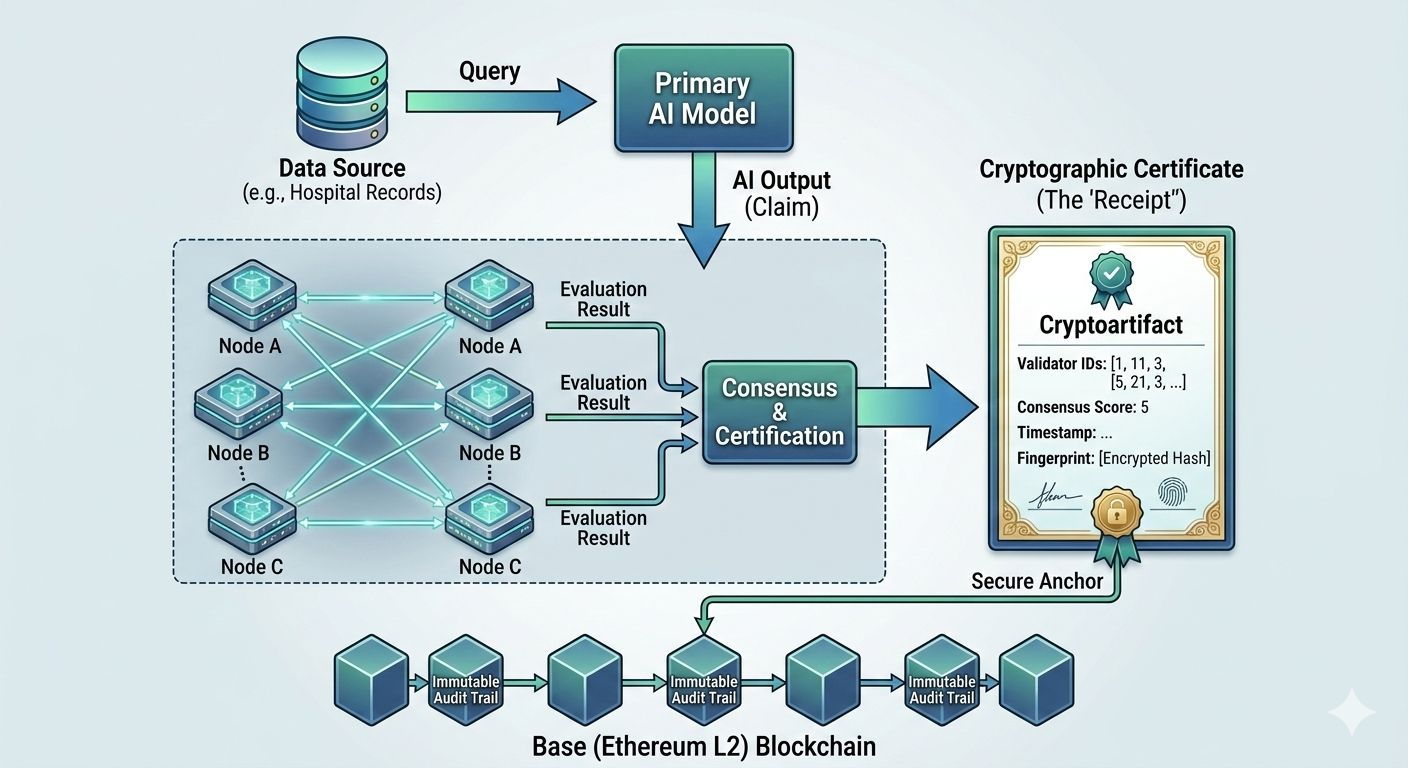
The result is not just an answer. It is an answer with a documented inspection history.
That distinction matters more than it might seem at first. When an organization faces an audit or regulatory review, the conversation changes dramatically if it can present a record showing exactly how a particular AI output was verified. Instead of relying on general assurances about system reliability, the institution can point to a specific artifact that reconstructs the decision process.
Building something like that requires more than simply adding another layer of software. The architecture itself needs to ensure that everyone evaluating the claim is actually looking at the same thing. AI outputs can be messy. A slight change in wording or context can lead to different interpretations. So the system first converts the output into a standardized format before sending it to validators. That way every participant is examining the same structured claim rather than slightly different versions of the same idea.
From there the claim is distributed across the validator network in a way that prevents predictable patterns. Validators do not always see the same claims or the same data. Random distribution helps protect sensitive information while also making it much harder for groups of validators to coordinate manipulation. Each validator runs its own evaluation, and the results are collected and compared.
Agreement does not happen through a simple vote. The system looks for strong consensus among validators before issuing a certificate. When that consensus forms, the outcome is sealed as a cryptographic record.
That record includes information about the validators who participated, the timing of the verification process, and a cryptographic fingerprint of the output itself. If someone later questions the decision, investigators can use that fingerprint to confirm that the output being examined is exactly the same one that passed through the verification round.
To make these records durable, they are anchored to a blockchain network. The idea here is not simply about decentralization for its own sake. It is about making sure the verification record cannot quietly disappear or be rewritten later. In environments where compliance matters, an audit trail that can be modified after the fact does not inspire much confidence.
Anchoring records to a public ledger ensures that once a certificate exists, it becomes extremely difficult to alter without leaving evidence behind.
The network itself runs on Base, an Ethereum Layer-2 platform designed to handle large numbers of transactions quickly and cheaply while still benefiting from Ethereum’s underlying security model. For a verification system that may need to record massive volumes of AI outputs, this balance between speed and reliability becomes essential. The process needs to be fast enough to operate in real-world workflows but secure enough that the records can be trusted months or years later.
One of the more interesting aspects of the system involves how it handles sensitive information. Many organizations rely on internal databases that cannot be exposed to external validators for privacy or regulatory reasons. Yet those same organizations may still need to prove that an AI-generated answer was based on accurate data.
This is where zero-knowledge proof technology enters the picture. Using cryptographic techniques, it becomes possible to demonstrate that a particular database query returned the correct result without revealing the query itself or the data behind it. In simple terms, the system can prove that an answer is valid without exposing the underlying information.

For companies working under strict confidentiality rules, that capability can make the difference between experimental AI projects and real operational deployment.
There is also an economic dimension to the network that shapes how participants behave. Validators do not simply volunteer their time. They stake capital in order to participate. If their evaluations align with the broader consensus and the verification process works correctly, they earn rewards. If they behave carelessly or attempt to manipulate outcomes, they risk losing part of their stake.
That incentive structure creates a system where accuracy is financially encouraged rather than purely ethical. Validators have something tangible to lose if they perform their role poorly.
Of course, none of this completely solves the deeper question of responsibility. If a verified AI output later contributes to harm, determining who is legally accountable will still require legal frameworks and institutional decisions. A cryptographic certificate cannot replace that process.
What it can do is provide clarity about what actually happened.
Instead of debating whether the system might have been checked, investigators can see the evidence of how it was checked. That difference may sound subtle, but it fundamentally changes how organizations manage risk around AI.
As governments and regulators begin to introduce stricter oversight of automated decision systems, this kind of verifiable record keeping is likely to become increasingly important. Regulators are already signaling that they want more than policy documents and technical reports. They want traceable logs that show exactly how individual decisions were handled.
Organizations that cannot produce that level of detail may eventually struggle to deploy AI systems in regulated environments.
The broader shift happening here is philosophical as much as technical. For years, the technology industry has treated trust in AI as something that emerges from model performance. If the system performs well enough, we trust it.
But the next phase of AI adoption may revolve around something different. Instead of asking whether models are impressive, institutions will ask whether their outputs can be examined, verified, and reconstructed when necessary.
In other words, trust will increasingly depend not just on intelligence but on evidence.
And when AI systems begin operating in areas where decisions carry legal, financial, or social consequences, that evidence may matter just as much as the answer itself.
