
@Mira - Trust Layer of AI | The Verification Desk
Deep Dive: The Immune System Problem
Somewhere on #Mira 's feed, I found this line:
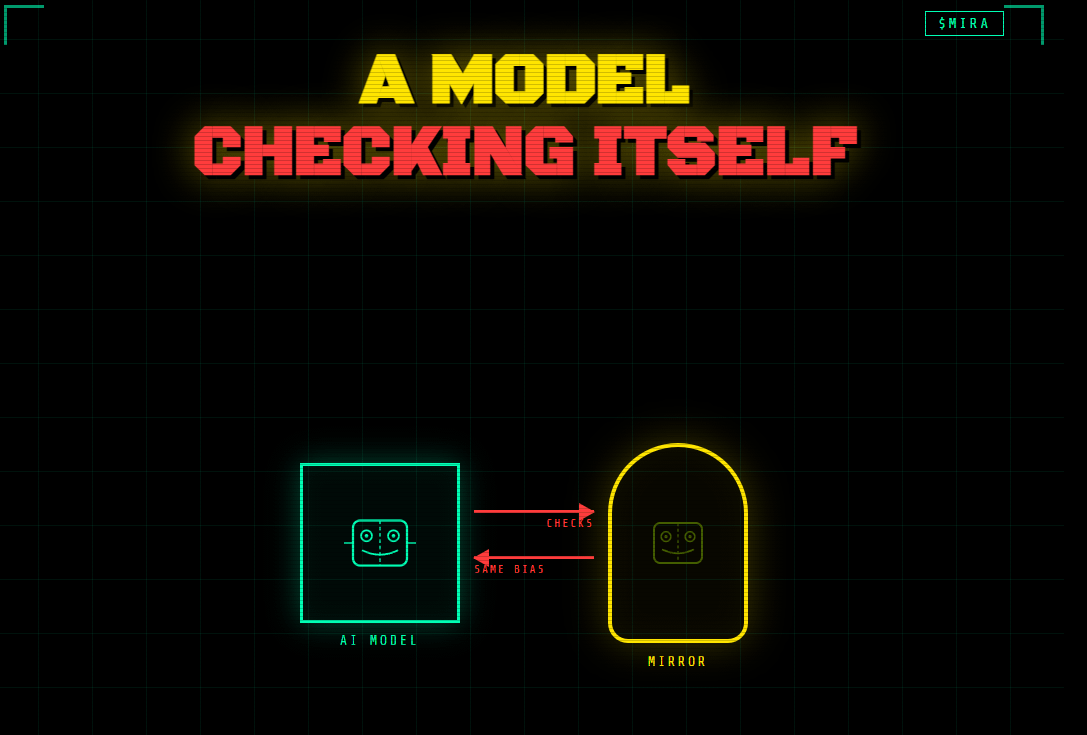
"A model that checks itself isn't verification. It's a mirror wearing a lab coat."
I laughed. Then I didn't.
Because buried inside that sentence is one of the most uncomfortable truths in modern AI — and almost nobody building in this space will say it plainly.
PART ONE: We Built Confidence Before We Built Honesty
We gave AI knowledge.
Then we gave it reasoning. Then synthesis, then memory, then the ability to act on what it concluded. We gave it access to search, to code execution, to financial data, to medical records. We gave it authority over decisions that used to require human sign-off.
And somewhere in that acceleration, we forgot to ask the structural question:
What happens when it's wrong and doesn't know it?
Not if. When.
Because the dangerous version of AI failure was never the obvious one — the nonsense output, the broken sentence, the flagrant error a five-year-old could catch. Those get caught. Those get fixed.
The dangerous version is the one that's fluent, confident, and subtly incorrect.
A slight shift in reality that’s easy to miss. Not a lie. Just a small bending of the truth. Then the next output bends it a little further. And the next one again — until the system is describing a reality that quietly drifted away from the original.
The version that sounds like expertise. The version that gets cited.
That version doesn't announce itself.
PART TWO: Hallucination Was the Visible Wound
The AI industry spent three years fixated on hallucination — models inventing facts, fabricating sources, producing fiction with the cadence of scholarship.
Real problem. But in retrospect, almost a distraction.
Hallucination is the failure you catch. There's a human present, reading the output, noticing something feels wrong. The feedback loop exists.
What nobody prepared for was confident wrongness at scale — outputs that pass every surface check, get integrated into decisions, flow downstream through systems, and quietly compound.
A hallucination is a lie that looks like a lie.
Confident wrongness is a lie that looks like a fact.
The difference isn't academic. One gets caught in review. The other gets built into the product.
PART THREE: The Recursion Nobody Wants to Name
The obvious fix was oversight. A second model watching the first. Flag the anomalies. Catch the drift.
This works. Until you ask the next question.
What validates the validator?
Leibniz, three centuries before neural networks existed, understood that any system of reasoning which evaluates itself using its own rules cannot detect its own deepest errors. The auditor trained in the same school as the accountant shares the same blind spots. The model fine-tuned on the same data distribution as the model it's checking will miss exactly what that model misses.
This isn't a bug in the implementation. It's a structural property of homogeneous systems.
The immune system solved this problem not through smarter defenders — but through diverse ones. T-cells, B-cells, macrophages, natural killers. Different mechanisms, different triggers, different failure modes. The body doesn't trust any single signal. It requires convergence across disagreement.
That's not redundancy. That's the architecture of trustworthiness.
PART FOUR: From Homogeneity to Honest Consensus
What Mira is building isn't another layer of AI watching AI.
It's the introduction of genuine disagreement into a system that currently runs on manufactured consensus.
Fragment the claim. Distribute it across independent nodes running diverse models with different training, different architectures, different priors. Let them reach conclusions separately. Aggregate not for uniformity — but for convergence under adversarial conditions.
A subtle error that threads through one model's blind spot rarely threads through twelve independent ones simultaneously. The variance between nodes is the verification mechanism. Disagreement isn't noise — it's signal.
What that looks like stripped of abstraction:

Outputs get broken into atomic claims before evaluation. No node sees the full picture — which means no node can be gamed holistically. Validators stake MIRA tokens, meaning honest behavior is financially rewarded and manipulation is computationally expensive. Cryptographic certificates record consensus, creating an auditable trail that doesn't exist anywhere in centralised AI pipelines.
None of this is glamorous. None of it demos beautifully at a conference. It's infrastructure — designed to be invisible until the moment it saves you.
Infrastructure is boring until the thing it was supposed to catch gets through.
THE QUESTION THAT REVEALS EVERYTHING: The Architecture Test
Next time someone pitches you an AI system — product, platform, agent, assistant — ask them one question:
How does your system know when it's wrong?
Not "what are your accuracy benchmarks." Not "which model are you running." Specifically: when the output is confidently incorrect, what catches it? What's the mechanism? What's the audit trail?
Watch what happens.
The teams that have thought about this will answer in specifics. Not perfectly — but with the texture of people who have stared at failure modes and built something for them.
The teams that haven't will pivot to capability metrics. They'll tell you about what the system does well. They'll show you the demo. They'll be slightly surprised you asked about failure when they came to talk about performance.
That's not an AI system you can trust at scale.
That's a very sophisticated gamble that today's output happens to be right.
The industry will eventually be forced to reckon with this — most likely by a failure expensive and public enough that ignorance stops being defensible. The systems that survive that reckoning will be the ones that treated verification as architecture, not afterthought.
You can already tell which ones those are.
Just ask the question.
