Of course AI systems have become extraordinarily capable in a remarkably short time. They write code, compose symphonies, summarize legal briefs, and diagnose diseases at superhuman speed. They are available everytime, never tire, and can synthesize more information in a second than a human expert can absorb in a lifetime. The promise they carry is enormous comparable, as the Mira whitepaper boldly states, to the invention of the printing press, the steam engine, electricity, and the internet combined.
But beneath this dazzling surface lies a fundamental, structural crack AI cannot be trusted to be consistently right. Every large language model is, at its core, a probabilistic machine. It does not reason from first principles the way humans aspire to. It predicts. It extrapolates. It approximates. And in doing so, it fabricates confidently, fluently, and without remorse a phenomenon the AI world calls "hallucination."
AI doesn't know what it doesn't know. It fills every gap with plausible-sounding fiction.
I think the consequences of this flaw are not abstract. A hallucinating AI prescribing the wrong medication dosage can kill. A biased AI evaluating loan applications can entrench systemic inequality for generations. A confident but incorrect legal AI drafting a contract can expose a company to ruinous liability. These are not hypothetical futures. These are the realistic stakes of deploying today's AI in high-consequence domains.
The root of the problem is what researchers call the training dilemma. When AI builders curate training data to eliminate inconsistencies improving precision and reducing hallucinations they inadvertently bake in the biases of whoever selected that data. Conversely, training on broader, more diverse data reduces bias but creates a model prone to producing contradictory outputs.
Fine tuned models offer some relief. A medical AI trained exclusively on peer reviewed clinical literature hallucinates less about medicine. But even these narrowly focused models crumble at the edges when a novel situation arises outside their training distribution, they fail, often without any signal that they are failing.
Check this out, here is a dual-axis diagram showing the inverse relationship between hallucination rate and bias as model training scope changes the training dilemma trade off.
simple graph with two crossing curves labeled Hallucination Risk and Bias Risk.
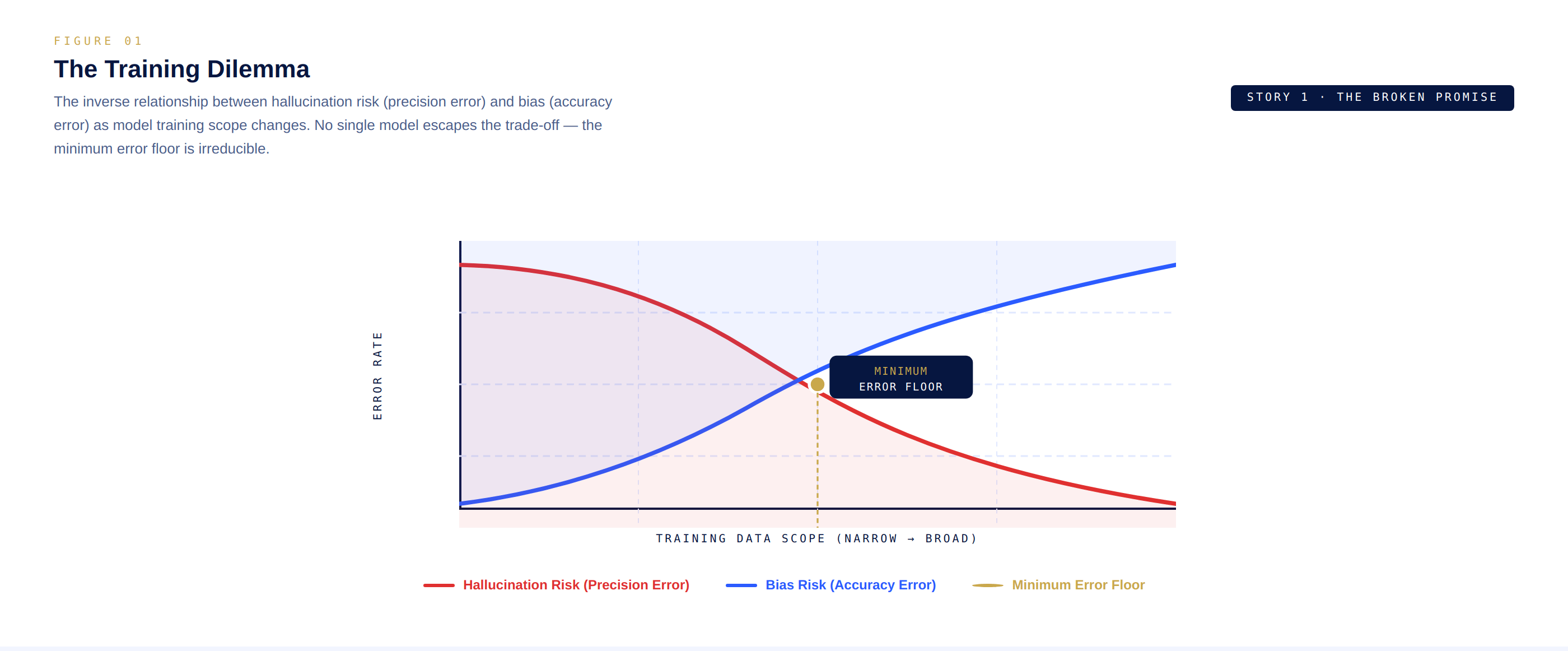
This creates what @Mira - Trust Layer of AI architects describe as an immutable boundary a minimum error floor that no single model, regardless of size or sophistication, can breach. You can throw more compute at it. You can pour in more data. You can architect deeper networks. But the floor remains. The probabilistic nature of the technology guarantees it.
This is not a counsel of despair. It is an invitation to think differently. The question is not "How do we build a perfect AI?" The question is: "How do we build a system that catches AI's mistakes before they cause harm?" That is the question Mira was built to answer and the story of how begins here.