A few weeks ago I was reading through a long AI-generated answer about a blockchain project. At first glance it looked convincing. Dates, funding numbers, technical descriptions—everything seemed neatly arranged. But after a closer look something felt off. One sentence claimed the project launched in 2022. Another quietly suggested development began in 2023. Both statements could not be true at the same time. The strange thing was that the contradiction was easy to miss because it was buried inside a smooth paragraph. That small moment illustrates a problem people are starting to notice with AI systems. They don’t just produce information. They produce clusters of statements that blend together so neatly that errors hide in plain sight.
This is where Mira’s verification model begins from a surprisingly simple idea. Instead of treating an AI answer as one continuous piece of text, the system breaks it into individual claims. A claim is just a statement that can be checked. Nothing complicated about the definition. If an output says a protocol launched in 2023 and raised 50 million dollars, those are two claims. Each can be verified separately. The approach sounds almost obvious once you hear it, which is probably why it feels easy to overlook.
Large language models tend to produce explanations the way people speak when they are confident. They rarely present isolated facts. Instead they build flowing narratives. A single paragraph might contain several factual statements, a few interpretations, maybe even an assumption disguised as a fact. For readers, the narrative feels natural. For verification systems, though, it creates a messy situation. Trying to judge the accuracy of the entire paragraph at once is like trying to evaluate five arguments simultaneously. Breaking it into claims simplifies the problem. Suddenly the task becomes smaller and clearer.
There is a quiet design philosophy behind that decision. Mira seems less interested in arguing about whether AI models are intelligent and more interested in whether their outputs can be checked. That difference matters. In many discussions around AI, the focus sits almost entirely on model capability. People compare benchmarks, parameter counts, reasoning ability. Those are important topics, but they don’t necessarily address reliability. A powerful model can still produce confident mistakes. Verification infrastructure tries to solve a different problem altogether.
The process works something like this. An AI output is analyzed and separated into individual claims. Those claims are then sent through a verification network where participants review them. Each reviewer checks whether the statement matches reliable information sources. It sounds procedural when described like that, but the interesting part is how the workload changes. Evaluating a single statement is far easier than evaluating an entire narrative. Humans naturally think this way anyway. When something sounds suspicious, people usually question one sentence first rather than the whole explanation.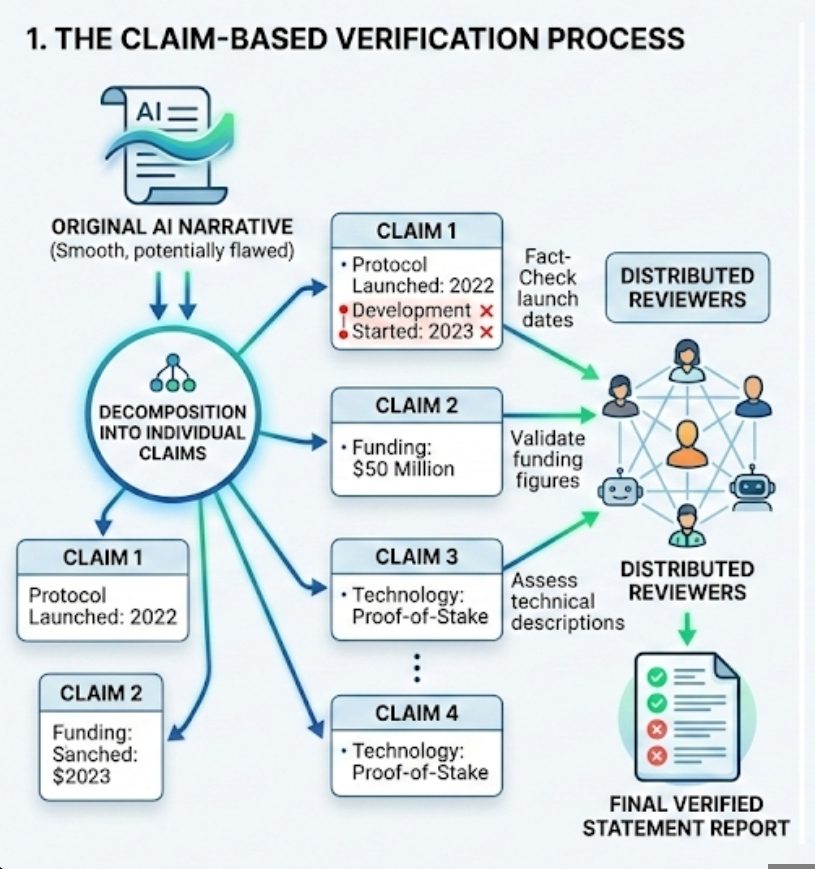
The structure also makes participation easier. In distributed verification systems, different participants handle different tasks.One person may simply look at the funding number and check if it’s actually correct. Another might take a moment to confirm the launch date. Someone else could read the technical description and compare it with the project’s real documentation to see if it truly matches. Instead of asking every participant to read a long AI response, the system distributes smaller pieces of work. That simple changes can make this large-scale verification more practical.
Still, the model raises questions about incentives. Networks that rely on human participants usually reward them in some form, whether through tokens, reputation points, or other metrics. Incentives attract attention, but they can also distort behavior. Anyone who has spent time around decentralized systems has seen this pattern. If rewards depend only on the number of tasks completed, some participants will rush through checks without thinking carefully. Accuracy suffers quietly in the background.
Breaking AI outputs into claims partly addresses that problem because performance becomes measurable. If a validator repeatedly approves claims that later prove incorrect, the system can record that pattern. Reputation systems—basically long-term trust scores—can adjust influence accordingly. People who verify carefully gain more weight in the network. Those who behave carelessly lose credibility over time. The idea resembles how trust forms in normal communities, although digital systems attempt to track it mathematically.
Interestingly, the idea of claim verification also echoes how information spreads on platforms like Binance Square. Posts there compete for visibility through engagement metrics—views, comments, likes, and interactions with tokens or links. The leaderboard systems behind CreatorPad, for example, measure content quality partly through AI evaluation and partly through audience response. In practice, this creates subtle pressure. Writers learn quickly that confident statements travel further than cautious ones.
That environment can unintentionally reward certainty over accuracy. A bold claim often gains attention faster than a careful explanation with caveats. If verification networks become more integrated into the information ecosystem, that balance could shift slightly. When statements are easy to isolate and test, creators may become more careful about the factual pieces embedded inside their narratives. The reputational cost of being wrong becomes clearer.
Of course, the system is not perfect. Some kinds of knowledge resist simple claim structures. Economic predictions are one example. If someone writes that a token could double in value next year due to increasing developer activity, the statement blends data with interpretation. It’s not purely factual. Breaking that sentence into claims might capture the data points but miss the broader judgment behind them. Verification systems work best with factual statements, not with opinions or forecasts.
Another complication lies in scale. Modern AI models produce enormous amounts of text every day. A single response may contain dozens of small claims, many implied rather than clearly stated. Detecting and separating those claims is not trivial. In some cases other AI models are used to identify them automatically. That creates a slightly ironic loop where AI helps organize the verification of AI-generated information. Whether that loop remains stable is still an open question.
Even so, the design choice reveals a shift in how people think about AI reliability. Instead of assuming better models will eventually eliminate mistakes, some developers are building systems that expect mistakes to happen. Verification becomes part of the infrastructure rather than a last-minute correction. It is a quieter approach to the problem.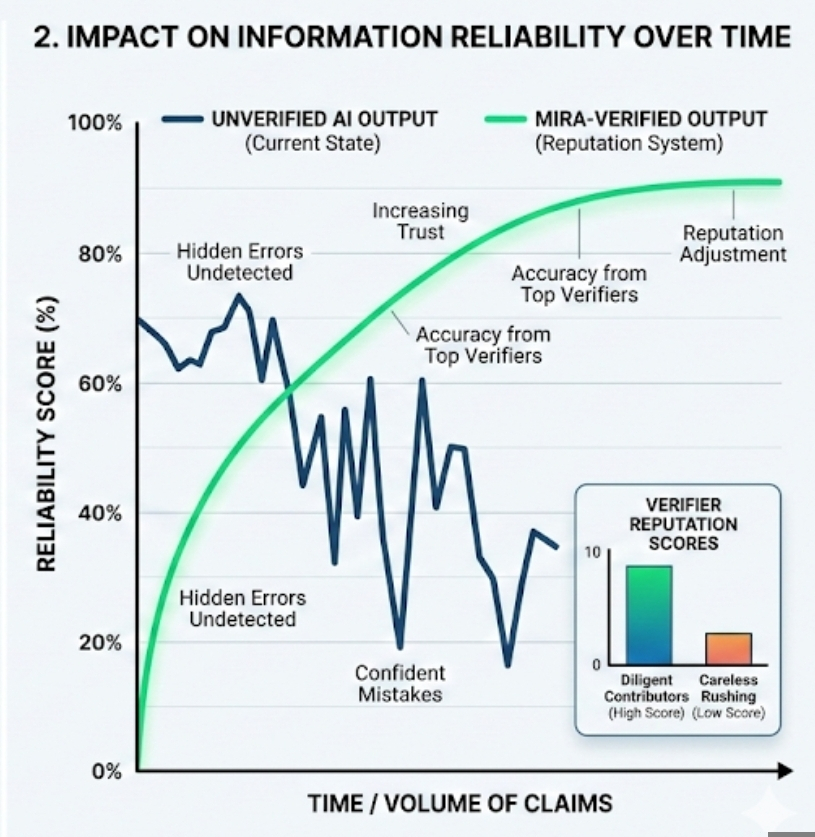
What I find most interesting about Mira’s model is how ordinary the core idea feels. Break information into checkable pieces. Let different people verify those pieces. Track who tends to be right. None of this sounds futuristic. In fact, it resembles how humans have evaluated claims in conversations for centuries.
Technology often moves forward that through the complex breakthroughs. Occasionally, though, progress comes from small structural adjustments that change how a system behaves over time. Breaking an AI response into smaller claims could end up being one of those quiet changes that slowly reshape how the whole system works.Not dramatic. Not especially glamorous either. But sometimes the quiet decisions around information structure end up shaping how trust forms in digital systems.
Articolo
Breaking AI Outputs into Claims: The Quiet Design Choice Behind Mira’s Verification Model
Disclaimer: Include opinioni di terze parti. Non è una consulenza finanziaria. Può includere contenuti sponsorizzati. Consulta i T&C.
0
6
67
Esplora le ultime notizie sulle crypto
⚡️ Partecipa alle ultime discussioni sulle crypto
💬 Interagisci con i tuoi creator preferiti
👍 Goditi i contenuti che ti interessano
Email / numero di telefono