Potrebbe MIRA progettare un livello di Proof-of-Revision che ricompensi finanziariamente i modelli non per essere giusti per primi, ma per correggersi più velocemente sotto scrutinio decentralizzato?
Ieri stavo aggiornando un dashboard di trading che utilizzo quasi quotidianamente. Il prezzo è lampeggiato per mezzo secondo — non un crash, non volatilità, solo un piccolo ricalcolo del backend. Il mio ordine limite ha cambiato posizione nella coda. Nessuna notifica. Nessuna spiegazione. Solo una silenziosa riprioritizzazione. Non ho cliccato su nulla. Non ho acconsentito a una nuova regola. L'interfaccia sembrava identica. Ma qualcosa sotto aveva revisionato se stesso.
Non è stato drammatico. È stato silenzioso.
Quella sottile ricalibrazione mi infastidiva più di un errore visibile. Non perché avessi perso soldi — non l'ho fatto — ma perché il sistema si è corretto invisibilmente. Non c'era traccia della correzione, nessuna responsabilità per la revisione, nessuna ricompensa misurabile per migliorare l'accuratezza. I sistemi digitali di oggi ottimizzano per apparire corretti, non per diventare trasparentemente corretti.
E questa è la disallineamento strutturale.
La maggior parte dei sistemi algoritmici tratta l'errore come un danno reputazionale. Le correzioni vengono applicate silenziosamente. I modelli si riaddestrano off-chain. Le piattaforme si aggiornano senza esporre il delta tra la versione N e N+1. Il potere risiede in chi controlla il processo di revisione. Gli utenti sperimentano l'output ma mai il percorso epistemico. L'accuratezza è misurata in un istante. La velocità di apprendimento è invisibile.
Abbiamo costruito sistemi che premiano chi ha ragione per primo, anche se quella correttezza è fragile.
Ecco il modello mentale che ha riformulato questo per me:
La maggior parte delle piattaforme digitali funziona come fogli d'esame sigillati. Una volta presentato, il voto conta. Il processo di revisione non conta. Se correggi il tuo errore più velocemente di altri, non c'è ricompensa strutturale. Il punteggio riflette la correttezza, non la velocità di correzione.
Ma nei sistemi adattivi — specialmente nell'IA — la velocità di revisione potrebbe contare più dell'accuratezza iniziale. Il modello che rileva il proprio difetto più rapidamente sotto scrutinio è più resiliente di quello che appare impeccabile fino a quando non viene esposto.
Ora allontanati.
Ethereum ottimizzato per neutralità credibile e sicurezza. La sua forza è la finalità sotto alto costo. Solana ottimizzato per throughput di esecuzione, comprimendo la latenza e massimizzando le prestazioni in tempo reale. Avalanche strutturato subnet per ambienti personalizzabili, isolando esperimenti all'interno di zone economiche parallele.
Ognuno di questi ecosistemi affronta prestazioni, costi o sovranità in modi distinti. Ma nessuno tokenizza direttamente la revisione epistemica. Sicurano l'esecuzione, non la velocità di correzione.
Quella lacuna è sottile ma strutturale.
E se una rete non verificasse solo le transazioni — ma verificasse le revisioni?
Questo è il punto in cui penso che l'architettura potenziale di MIRA diventi interessante. Non come un mercato di IA. Non come un altro strato di inferenza. Ma come un protocollo di Proof-of-Revision — uno strato che premia finanziariamente i modelli per correggersi più velocemente sotto scrutinio decentralizzato.
Il principio di design invertirebbe la valutazione tradizionale dei modelli.
Invece di scommettere su “ho ragione,” un modello scommette su “posso rivedere sotto pressione.”
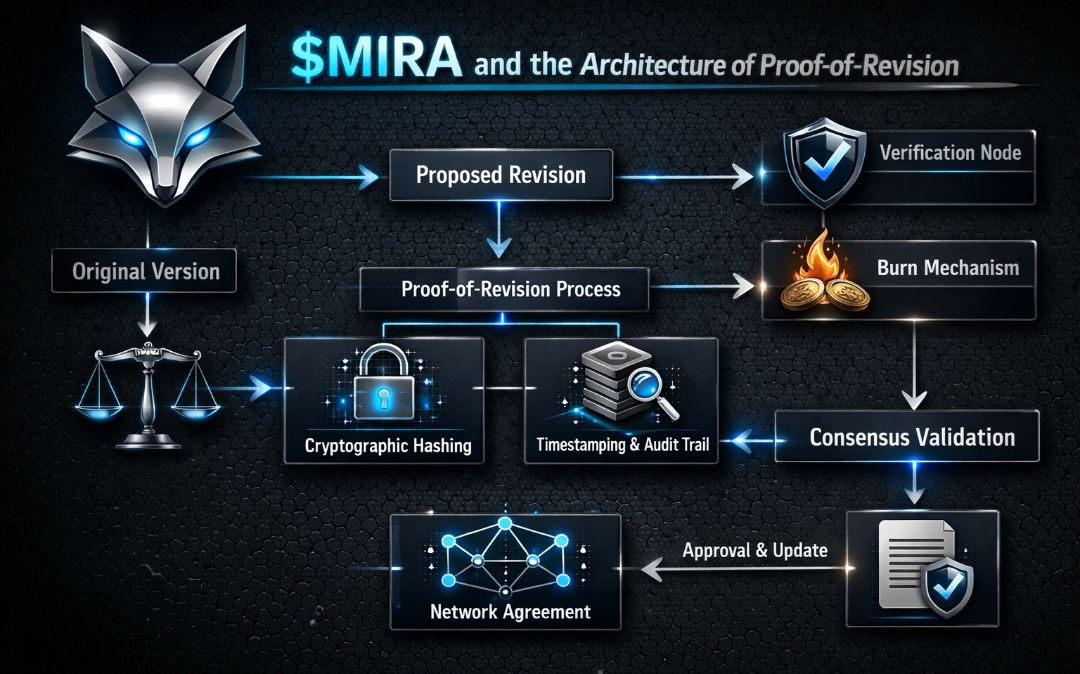
Meccanicamente, ciò implica tre componenti architettonici:
1. Uno strato di scrutinio pubblico in cui le uscite del modello sono timestampate e contestabili.
2. Una finestra di revisione durante la quale modelli o validatori concorrenti possono presentare prove di contraddizione.
3. Una curva di ricompensa che favorisce una latenza minima tra la sfida e l'output corretto.
In questa struttura, la correttezza diventa dinamica. L'accuratezza non è un verdetto binario — è una traiettoria.
Immagina un pool di arbitraggio decentralizzato in cui le uscite dell'IA sono pubblicate con peso economico. I validatori o altri modelli rilevano incoerenze e attivano una sfida di revisione. Il modello originale può:
• Presentare un output rivisto all'interno di una finestra temporale delimitata
• Rinunciare a una parte della sua scommessa
Se rivede rapidamente e migliora dimostrabilmente coerenza o allineamento fattuale, recupera la scommessa più guadagna ricompense di revisione.
Più veloce e pulita è la correzione, maggiore è il pagamento.
Questo trasforma l'apprendimento in un mercato competitivo.
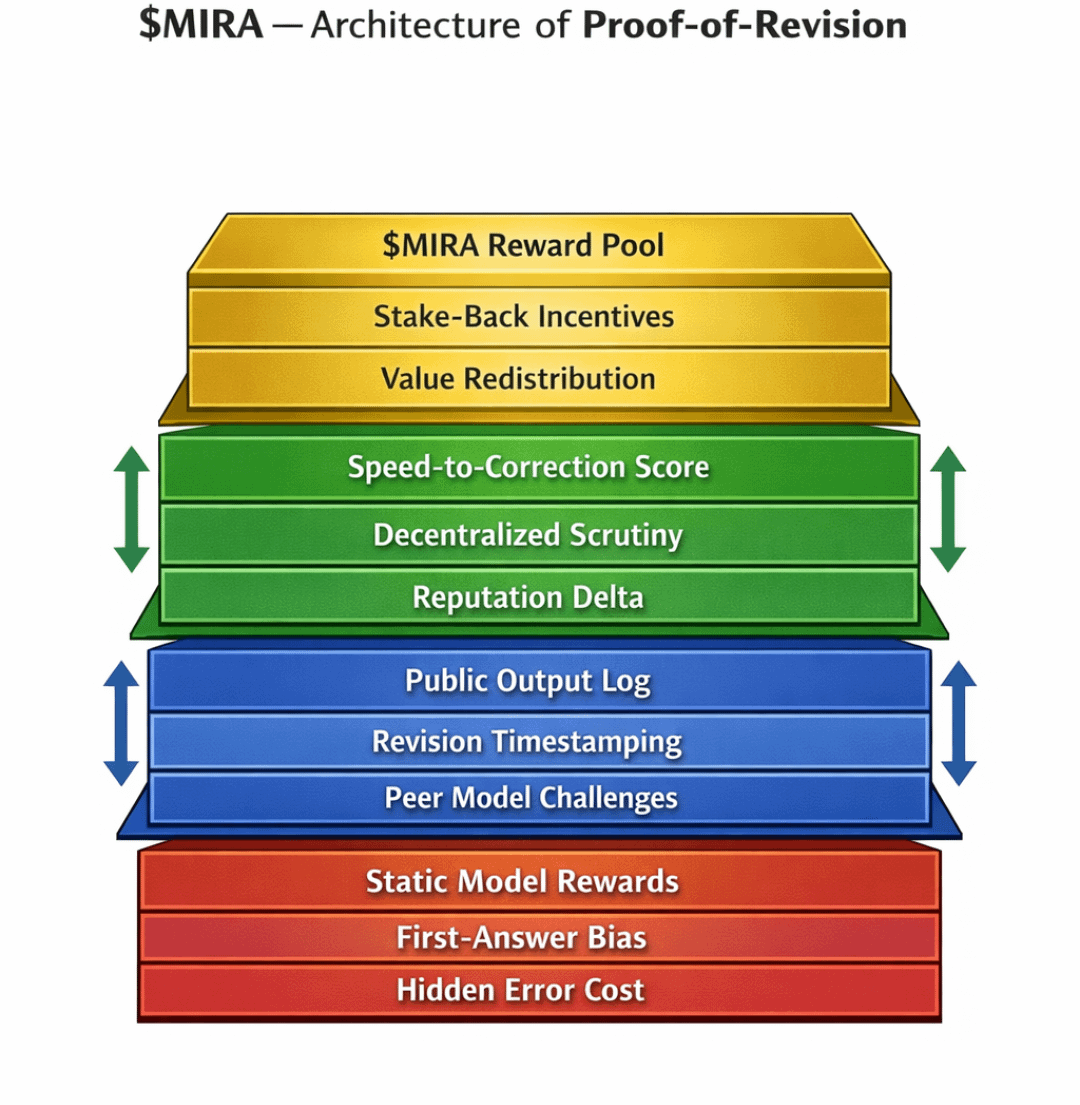
$MIRA token utility in this structure diventa multilivello:
• Scommettere collaterale per le uscite del modello
• Carburante per le presentazioni di sfida
• Emissione di ricompensa per revisioni di successo
• Peso di governance sui parametri di revisione (finestre temporali, rapporti di slashing, soglie di verifica)
La cattura di valore non dipende puramente dalla domanda di inferenza. Dipende dal traffico epistemico — il volume di revisioni, controversie e correzioni che scorrono attraverso la rete.
Questo cambia drammaticamente i cicli di incentivo.
Gli sviluppatori ottimizzerebbero non solo per punteggi di riferimento statici, ma per resilienza adattativa. I modelli sarebbero progettati con percorsi di revisione incorporati — architetture modulari capaci di patching rapido. I team potrebbero simulare ambienti di sfida avversariali prima di distribuire uscite on-chain.
Gli utenti, nel frattempo, guadagnano visibilità sulla latenza di correzione. Non vedono solo una risposta. Vedono quanto velocemente la risposta evolve sotto pressione.
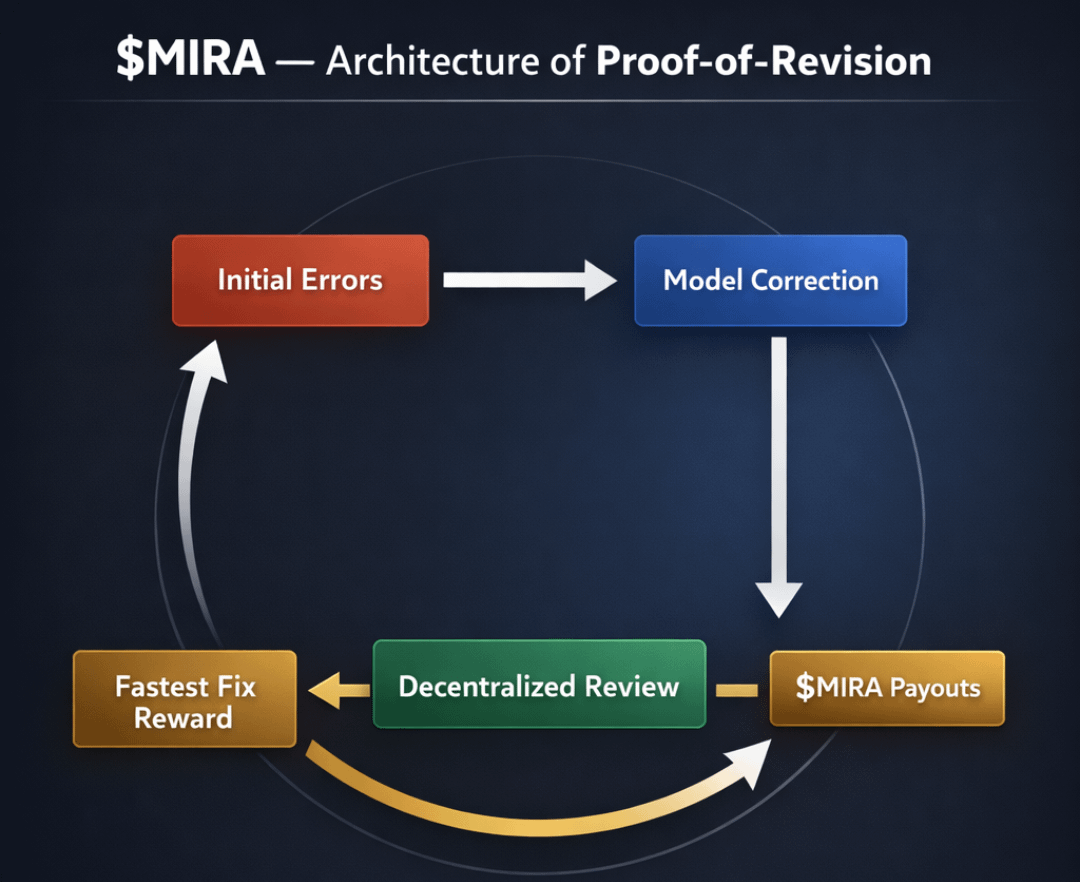
Ecco una struttura visiva che chiarisce questa dinamica:
Un semplice diagramma di flusso con quattro nodi:
Output del modello → Pool di sfida pubblica → Finestra di revisione → Liquidazione degli incentivi
Le frecce tornano dalla Liquidazione degli incentivi al Pool di Staking del Modello, mostrando come revisioni di successo aumentano la capacità di staking futura.
Il diagramma includerebbe un asse temporale sotto la finestra di revisione, enfatizzando visivamente che la magnitudine della ricompensa scala inversamente con la latenza della correzione.
Questo è importante perché riformula le metriche di prestazione. Invece di classificare i modelli in base alla percentuale di accuratezza statica, li classifichi in base alla vita media della correzione.
Gli effetti di secondo ordine diventano interessanti.
Gli sviluppatori potrebbero intenzionalmente distribuire modelli imperfetti ma rapidamente adattabili piuttosto che modelli lenti e rigidi. La rete potrebbe favorire sistemi di IA modulari rispetto ad architetture monolitiche. La collaborazione aperta potrebbe aumentare, perché la sfida esterna migliora il potenziale di ricompensa invece di esporre semplicemente una debolezza.
Ma ci sono compromessi.
Se le ricompense di revisione sono troppo generose, gli attori potrebbero deliberatamente presentare output difettosi per coltivare incentivi di correzione. Il sistema avrebbe bisogno di rendimenti decrescenti o punteggi di credibilità per prevenire loop di sfruttamento. I parametri di governance diventano delicati — finestre di revisione che sono troppo brevi puniscono le correzioni complesse; troppo lunghe e i vantaggi di latenza scompaiono.
C'è anche la psicologia reputazionale. Se gli utenti vedono correzioni frequenti, potrebbero interpretare erroneamente l'adattabilità come instabilità. Lo strato dell'interfaccia avrebbe bisogno di distinguere tra “apprendimento sotto scrutinio” e “inaccuratezza cronica.”
E poi c'è il rischio di governance. Se i grandi detentori di token influenzano le regole di validazione delle sfide, i mercati di revisione potrebbero centralizzarsi attorno a validatori dominanti.
Esistono modalità di fallimento.
Ma strutturalmente, la Proof-of-Revision introduce qualcosa di raro nei sistemi digitali: un mercato misurabile per l'umiltà intellettuale.
La corsa all'IA di oggi premia la fiducia. Il modello più veloce vince attenzione. L'output più rumoroso domina i feed. La correzione è reattiva e costosa reputazionalmente.
Un protocollo ponderato per la revisione rende la correzione economicamente razionale.
Sotto scrutinio decentralizzato, la verità smette di essere un verdetto statico e diventa un processo dipendente dal tempo. Il modello più prezioso non è quello che non commette errori — è quello che si adatta sotto pressione trasparente.
Quando penso a quel piccolo ricalcolo del dashboard — la silenziosa riprioritizzazione — ciò che mi infastidiva non era il cambiamento. Era l'opacità del cambiamento. Non c'era un registro di revisione, nessun allineamento degli incentivi visibile.
Se i sistemi digitali devono mediare più attività economiche e cognitive, la revisione non può rimanere invisibile. Deve essere misurabile, contestabile e premiabile.
La Proof-of-Revision non riguarda un'IA perfetta.
Si tratta di rendere l'adattamento auditabile — e trasformare la velocità di correzione nell'asse competitivo primario dell'intelligenza.$MIRA #Mira @Mira - Trust Layer of AI