How Mira’s Network of Verifier Nodes Validates AI Outputs
@Mira - Trust Layer of AIwhy Mira’s verifier nodes exist in the first place
A few months ago I watched an AI assistant produce a risk note that looked perfect at first glance—tight language, clean structure, even the right tone for a compliance audience. Then I traced one number back to the source and realized it wasn’t “wrong” in an obvious way. It was wrong in the most dangerous way: it had silently filled a gap with something plausible. No error message. No uncertainty flag. Just a confident sentence that slid into the workflow like it belonged there.
That’s the gap Mira Network is trying to address with verifier nodes. In high-stakes workflows, the issue isn’t only hallucination—it’s that AI outputs often arrive with the appearance of certainty. “Sounds confident” is not the same as “is true,” and that difference becomes unacceptable once systems move from drafting text to triggering actions. Mira frames its network as a decentralized verification protocol designed to turn AI outputs into checkable claims and validate them through a consensus process, producing auditable proof of what was evaluated and what passed.
From output to verifiable claims: what verifier nodes are actually checking
The first idea I look for in any “AI verification” pitch is whether it tries to verify an entire blob of text at once. Because that tends to fail in practice. When you pass a full answer to a verifier, different verifiers latch onto different parts. One model checks a date. Another checks the overall gist. A third checks the tone and assumes the facts are fine. You end up with agreement that is more like vibes alignment than validation.
Mira’s approach, as described in its own writing, is to transform AI outputs into smaller, independently checkable claims that can be validated by a decentralized network of verifier nodes.That’s the right direction conceptually, because “verification” only becomes concrete when everyone is verifying the same atomic statements.
But claim decomposition is hard to do well, and I don’t treat it like a solved problem. If you break a paragraph into claims too loosely, you miss the dangerous parts. If you break it too aggressively, you create a huge number of tiny checks that raise cost and latency. And there’s a more subtle failure: you can verify the wrong thing. A claim can be technically verifiable while missing the real decision point. So when I think about verifier nodes, I don’t only think “how do they vote?” I think “what exactly are they being asked to judge?”
The tradeoff is straightforward: more structure and more checks can increase assurance, but also increases overhead and creates new edges to attack. Mira’s design intent is to make verification systematic, not ad hoc—yet the quality of the claim breakdown still matters because it defines what “truth” even means inside the protocol.
Multi-model consensus: why “independent judges” matters more than “smart judges”
On the surface, multi-model verification sounds like a simple ensemble trick: ask multiple models, take the majority answer. In reality, the key word is independence. If all your “verifiers” are the same family of model, trained on similar data, prompted the same way, and deployed through the same provider stack, you can get correlated failures—everyone hallucinates the same wrong citation, or everyone misses the same subtle contradiction.
Mira’s product language around verification leans on “multiple specialized AI models independently verify each claim” and reach a consensus-based validation. I read that as an intention to reduce single-model failure modes: hallucinations, blind spots, bias, and the general tendency for one model to be overconfident about its own mistakes
In practice, independence should mean variation across at least three dimensions:
The first is model diversity—different families or providers, not just different temperature settings. The second is prompt diversity—different ways of framing the verification question so you don’t herd all verifiers into the same reasoning path. The third is context diversity—carefully controlling what each verifier sees so they don’t all anchor on the same misleading snippet.
This is where a “trustless” posture matters. Mira frames itself around eliminating central points of arbitration by relying on decentralized verification nodes rather than a single entity acting as judge and jury.That’s appealing, but it also raises the bar: you need the network design—selection, weighting, incentives—to keep the independence real rather than cosmetic.
Cryptographic and economic finality: credibility that doesn’t rely on vibes
I’m skeptical of systems that say, “Trust us, we have a reputation.” Reputation is useful, but it’s also social and reversible. What I want, especially for machine-generated outputs, is something closer to finality: a result is credible because the process is auditable and costly to fake.
Mira’s framing emphasizes auditing “from input to consensus,” and providing auditable certificates for validated outputs. That’s the cryptographic side of the story: you can inspect what was checked and how the system arrived at the result, rather than treating verification as a black box.
Then there’s the economic side. In Mira’s MiCA-related documentation on its own site, the network is described as using a token that enables staking to participate in the network’s verification process; node operators who run AI models for verification “will have to stake” to participate, contributing to security by validating transactions and proposing new blocks.The same document also describes token-based governance and token payments for API access.
The point of incentives, in theory, is simple: honest verification should be rewarded, and dishonest or low-effort behavior should be expensive. But I keep my skepticism on. Incentives can be gamed. If rewards are tied to “agreeing with consensus,” you can get conformity instead of truth. If penalties are weak or enforcement is unclear, you get lazy validators rubber-stamping outputs. Verification is only as good as the rules, the participants, and the attack surface those rules create.
Full stack verified information: the part builders actually care about
A lot of projects get stuck at the slogan level—“verified AI”—and never ship the workflow that makes it real. If you want developers to rely on “verified information,” you need more than consensus theory. You need plumbing.
At minimum, you need a flow that takes an output, decomposes it into claims, runs verification across multiple models, aggregates results, produces attestations, and exposes a clean interface so applications can consume the verified result without re-implementing the whole system.
Mira’s own “Mira Verify” product page describes an API path where you can “verify everything,” then “audit everything,” with certificates tied to the verification process, and multi-model verification reaching consensus. Separately, Mira’s SDK documentation describes a unified interface to integrate multiple language models with routing, load balancing, and flow management—more of an application-layer developer surface than a pure research artifact.
From a builder’s perspective, what I want is: clear provenance, auditability, reproducible verification steps, and composability into agents, search, and decision support tools. Not because it sounds impressive, but because it’s the difference between “a demo that looks safe” and “a system you can explain to a risk team when something goes wrong.”
Performance requirements: cost, latency, and throughput don’t negotiate
Verification isn’t free. If you involve multiple models and a consensus layer, you’re paying for additional inference, additional coordination, and whatever overhead comes from producing audit artifacts. Even before you touch blockchain mechanics, you’ve already increased compute and time.
So the tension is unavoidable: higher assurance usually means higher cost and higher latency. Mira has to balance “fast enough to be useful” with “strict enough to be meaningful,” or else it becomes either a toy (too slow/expensive) or theater (too weak to matter).
Real-world pressure shows up in boring places: bursty demand, large payloads, and adversarial inputs. Bursts break systems that assume smooth traffic. Large payloads force you to decide what you verify versus what you merely record. Adversarial inputs punish every ambiguous rule. And once money is involved, people will adversarially optimize.
If Mira’s verifier network is going to sit in the loop for agents, not just for offline reports, the performance profile matters as much as the cryptography.
Incentives and participation: utility over narrative
Decentralized networks only work when participation is rational. In Mira’s own compliance documentation, staking is framed as a participation mechanism for verification, with rewards for staking and token-based governance rights. That’s a recognizable design pattern in crypto: stake to align incentives, reward helpful behavior, and (in many designs) penalize harmful behavior
But what I care about most is definitional clarity. What does “verified” mean in this system? Does it mean a claim is likely true? Does it mean multiple models agreed? Does it mean the network produced an auditable certificate that some process occurred?
Don’t treat these as the same. “Verified” needs guardrails: it’s not a blanket guarantee, it’s not a substitute for source checks when the consequences are serious, and it can’t make an ambiguous prompt suddenly precise. Spelling that out sets the right expectations and helps on the compliance side
Don’t treat these as the same. “Verified” needs guardrails: it’s not a blanket guarantee, it’s not a substitute for source checks when the consequences are serious, and it can’t make an ambiguous prompt suddenly precise. Spelling that out sets the right expectations and helps on the compliance side. If you oversell verification, you train users to over-trust it.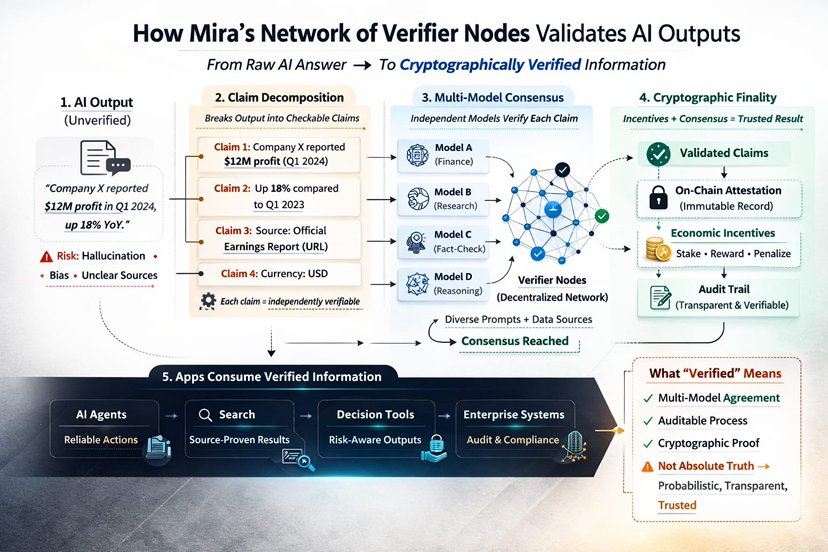
Risks and safe usage: how I’d integrate it without fooling myself
Even with the right intent, the risks are real.
Correlated model failures are the first: diversity can be claimed but not achieved. Adversarial prompting is the second: verifiers can be manipulated, especially if claim framing is sloppy. “Verification theater” is the third: you end up checking format, consistency, or plausibility rather than truth. Governance or parameter drift is the fourth: the network slowly changes what it considers valid. Concentration is the fifth: too much power in a few validators or a few model providers. And integration risk is the sixth: developers treat “verified” as permission to automate decisions that still deserve human review.
My safety habits stay boring on purpose. I treat outputs as probabilistic. I verify sources when stakes are high. I start with lower-risk use cases where mistakes are recoverable. I log proofs and attestations so there’s a trail. And I resist giving systems more autonomy than verification can justify, even if the demo looks clean.
Conclusion: a direction that matches where AI is going
I don’t think the world needs more fluent AI. It needs AI that can be held to account. Mira is early and it carries real execution risk, but its design direction—breaking outputs into verifiable claims, validating them through multi-model consensus, and backing results with auditable artifacts and crypto-economic participation—aims at the right future shape.
When I picture the next wave of agents, I don’t imagine them being trusted because they’re persuasive. I imagine them being trusted because they can show their work, prove what was checked, and clearly mark what remains uncertain. If Mira can make that practical at scale—without turning verification into theater—it’s the kind of infrastructure that could change how we judge AI: not by confidence, but by reliability
#Mira $MIRA @Mira - Trust Layer of AI
