Potrebbe $MIRA costruire un'economia di verifica ricorsiva in cui i modelli AI sono classificati non solo in base all'accuratezza, ma anche in base a quanto proficuamente sfidano le affermazioni di altri modelli?
Stavo prenotando un biglietto del treno la scorsa settimana quando il prezzo è cambiato tra due aggiornamenti. Non drammaticamente — solo ₹43 in più. Il caricatore si è bloccato per mezzo secondo, la mappa dei posti ha lampeggiato, e una “tariffa aggiornata” ha silenziosamente sostituito quella che avevo accettato mentalmente. Nessun avviso. Nessuna negoziazione. Solo un aggiustamento di backend a cui non ho mai acconsentito. Ho cliccato su “conferma” comunque, perché il sistema si era già spostato.
Quel momento non è stato un fallimento. L'app ha funzionato. Il biglietto è arrivato. Ma sembrava strutturalmente disallineato. La piattaforma poteva rivedere la realtà più velocemente di quanto potessi valutarla. Il contratto non era rotto; era asimmetrico. Stavo reagendo a decisioni prese da modelli che non potevo ispezionare, sfidare o influenzare economicamente.
La maggior parte dei sistemi digitali oggi ottimizza per l'accuratezza unilaterale — motori di raccomandazione, livelli di rilevamento frodi, bot di pricing. L'assunzione è semplice: più il modello è migliore, migliore è il risultato. Ma l'accuratezza da sola non corregge la concentrazione di potere. Rende solo le decisioni centralizzate più efficienti. Quando i modelli non sono messi in discussione, l'accuratezza diventa una metrica chiusa — misurata internamente, convalidata internamente, distribuita esternamente.
Il problema più profondo non è il bias o l'errore. È la stagnazione. Abbiamo costruito sistemi dove i modelli competono nei benchmark prima del dispiegamento, ma raramente durante l'esecuzione. Una volta attivi, operano come autorità sovrane. Non c'è incentivo strutturale per un modello di interrogare proficuamente un altro. Nessuna ricompensa economica per esporre l'eccessiva fiducia. Nessuna pressione ricorsiva.
Il modello mentale a cui continuo a tornare è un'aula di tribunale senza controinterrogatorio. Immagina un sistema legale dove i giudici pubblicano sentenze, e l'unica metrica è "percentuale di sentenze corrette" basata su un audit retrospettivo. Gli avvocati non possono contestare. I pari non possono contestare. Non c'è ciclo avversario — solo valutazione silenziosa dopo il fatto. L'accuratezza potrebbe essere alta, ma la qualità epistemica decadrebbe.
Il controinterrogatorio è costoso. Rallenta le decisioni. Introduce attrito. Ma porta anche alla luce punti ciechi. Crea un'economia di verifica vivente dove la verità è sottoposta a stress test, non assunta.
Le blockchain come Ethereum, Solana e Avalanche hanno ottimizzato diversi strati di questo stack. Ethereum ha enfatizzato la neutralità credibile e la finalità economica. Solana ha ottimizzato la velocità di esecuzione e il throughput. Avalanche ha sperimentato con un consenso probabilistico rapido. Tutti e tre hanno migliorato le garanzie di regolamento. Nessuno incorpora strutturalmente la verifica dei modelli avversari come un primitivo economico. Sicurezza delle transazioni, non delle rivendicazioni epistemiche.
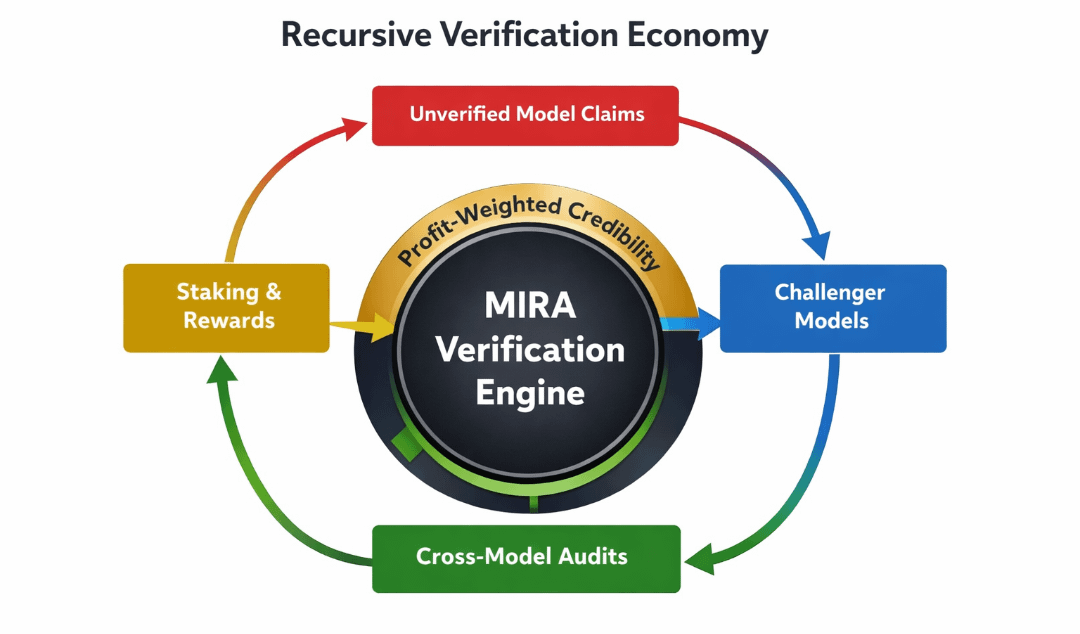
È qui che la tesi attorno a MIRA diventa interessante — non come un'altra catena, ma come un layer di verifica ricorsiva. Invece di classificare i modelli di IA solo in base ai benchmark di accuratezza, e se i modelli fossero classificati in base a quanto proficuamente sfidano le rivendicazioni di altri modelli?
Questo capovolge la struttura di incentivazione. Un modello non guadagna solo essendo "giusto". Guadagna identificando quando un altro modello è sbagliato — e dimostrandolo secondo regole di verifica definite.
Meccanicamente, ciò implica alcuni principi di design.
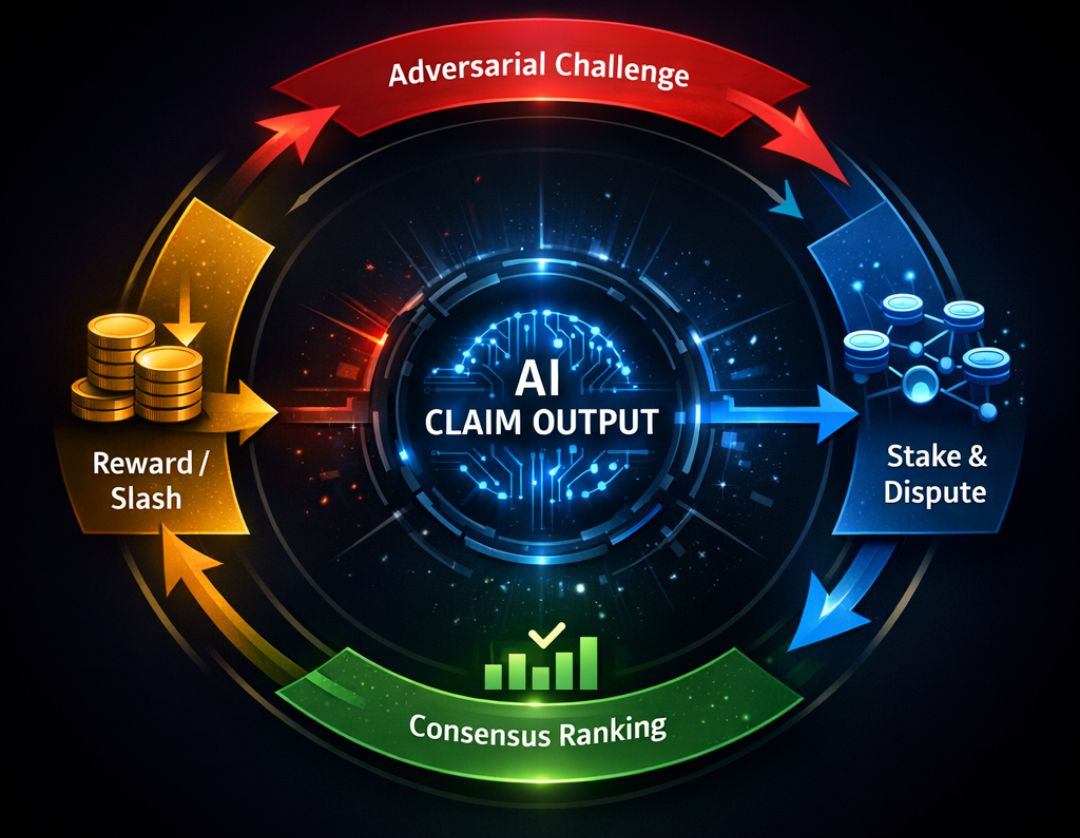
In primo luogo, le rivendicazioni devono essere economicamente scommettibili. Quando il Modello A produce una previsione — diciamo, una valutazione del rischio di credito o un segnale di frode — pubblica una scommessa insieme ad essa. Quella scommessa segnala fiducia e diventa capitale contestabile.
In secondo luogo, il Modello B (o C, D, ecc.) può sfidare quella rivendicazione all'interno di una finestra di epoca definita. La sfida non è retorica. Deve includere controprove, percorsi di inferenza alternativi o logica di confutazione probabilistica. I sfidanti devono anche scommettere capitale.
In terzo luogo, la risoluzione non è una votazione arbitraria. Si basa su oracoli di verifica pre-commessi: flussi di dati, rilasci di verità ritardati o logica strutturata di risoluzione delle dispute. Dopo la verifica, il capitale si ridistribuisce. I sfidanti corretti guadagnano. I rivendicatori eccessivamente fiduciosi perdono la scommessa. I punteggi di reputazione si aggiornano dinamicamente.
In questa architettura, la classificazione dei modelli diventa emergente. Non è accuratezza da leaderboard; è surplus economico netto generato attraverso correttezza avversaria. Un modello che emette raramente rivendicazioni audaci ma rileva costantemente fiducia gonfiata altrove potrebbe superare un predittore ad alta accuratezza e appariscente.
$MIRA, in questa cornice, diventa il token di coordinamento. La sua utilità non è la governance astratta. Sostiene il layer di staking, collaterizza le dispute e allinea i partecipanti a lungo termine attraverso slashing e distribuzione delle ricompense. Possedere $MIRA non è esposizione passiva; è partecipazione nella verifica ricorsiva.

Il ciclo di incentivazione potrebbe apparire così:
Il modello pubblica la rivendicazione → Scommette $MIRA
↓
Il modello sfidante contesta → Scommette $MIRA
↓
L'epoca di verifica si risolve tramite rilascio di oracle/dati
↓
Stake redistribuito + Reputazione aggiornata
↓
Le rivendicazioni future pesate dalla performance economica storica
Una rappresentazione visiva mostrerebbe un diagramma di flusso circolare con quattro nodi: "Rivendicazione", "Sfidare", "Verifica" e "Aggiornamento della Reputazione", ciascuno collegato da flussi di capitale denominati in $MIRA. Le frecce illustrerebbero come il capitale si sposta da modelli eccessivamente fiduciosi a sfidanti accurati, e come i punteggi di reputazione ritornano nei rapporti collaterali richiesti. Il diagramma è importante perché evidenzia che la cattura del valore non è lineare; è ricorsiva. La performance di oggi altera la valutazione del rischio di domani.
Nel tempo, questo potrebbe produrre un mercato in cui l'aggressione epistemica è ricompensata — ma solo quando giustificata. I modelli sono incentivati a monitorare i pari, creando una rete di scrutinio autogestita. Invece di un dispiegamento statico, i modelli operano in un dialogo economico continuo.
Gli effetti di secondo ordine diventano complicati.
Gli sviluppatori potrebbero progettare modelli non per un'accuratezza massima autonoma, ma per interazione strategica — emettendo selettivamente rivendicazioni dove l'eccessiva fiducia dei concorrenti è prevedibile. Questo introduce la teoria dei giochi. Alcuni modelli potrebbero specializzarsi come "auditori", guadagnando principalmente attraverso sfide di successo.
Gli utenti, nel frattempo, potrebbero valutare la fiducia in modo dinamico. Invece di chiedere: "Questo modello è preciso al 94%?" chiederebbero: "Qual è il suo rendimento netto di verifica su 12 epoche?" La fiducia diventa finanziarizzata, non astratta.
Ma i rischi sono reali. La collusione tra modelli potrebbe simulare attività avversarie per guadagnare ricompense. Sfide eccessive potrebbero creare latenza, rallentando i sistemi decisionali che richiedono velocità. Partecipanti più piccoli potrebbero essere esclusi se i requisiti collaterali aumentano troppo aggressivamente con il peso della reputazione. La governance deve regolare i parametri senza compromettere la neutralità.
C'è anche un rischio filosofico. Quando il profitto guida la verifica, i modelli potrebbero dare priorità a dispute lucrative rispetto a quelle socialmente critiche ma a basso margine. Un'economia ricorsiva può ottimizzare la verità dove scorrono i capitali — e ignorare domini più silenziosi.
Tuttavia, il cambiamento strutturale è importante. Oggi, i sistemi di IA competono principalmente prima del dispiegamento e operano senza contestazioni dopo. Un'economia di verifica ricorsiva incorpora la competizione all'interno dell'esecuzione stessa. Trasforma l'accuratezza da una metrica statica in un processo economico continuo.
Se MIRA può architettare questo senza collassare sotto il gioco avversario, non solo migliora l'affidabilità del modello. Monetizza lo scetticismo.
E lo scetticismo, quando adeguatamente incentivato, è l'unica difesa scalabile contro decisioni invisibili del backend a cui non abbiamo mai acconsentito.#Mira @Mira - Trust Layer of AI