Scritto dal Qubic Scientific Team

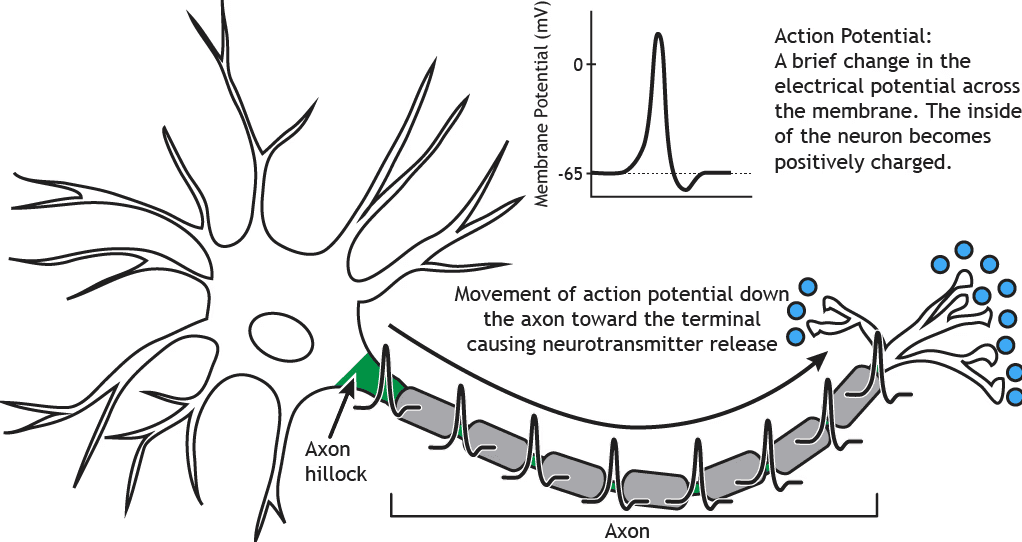
Il cervello è dinamico e non binario
Le reti cerebrali biologiche non funzionano come un interruttore decisionale tra attivazione e riposo. Nei sistemi viventi, l'inattività stessa implica dinamismo. Un “riposo” assoluto sarebbe incompatibile con la vita. Come abbiamo visto nel primo capitolo, la vita si svolge nel tempo.
Un singolo neurone può apparire come un evento tutto o niente, trasmettendo corrente elettrica a un altro neurone per inibirlo o eccitarlo. Tuttavia, prima di quella trasmissione, il potenziale d'azione, il neurone riceve continuamente input positivi e negativi in una regione chiamata dendriti. Se la somma globale di questi input supera una certa soglia, si verifica un cambiamento conformazionale fisico e la corrente elettrica si propaga lungo l'assone verso il neurone successivo. Per la maggior parte del tempo, l'elaborazione neuronale avviene al di sotto della soglia d'azione, dove le correnti eccitatorie e inibitorie vengono continuamente integrate.
Nelle neuroscienze computazionali, è ben stabilito che il cervello è un sistema dinamico continuo i cui stati evolvono anche in assenza di stimoli esterni (Deco et al., 2009; Northoff, 2018).
Non ci sono eventi discreti o reset nel cervello. Ogni stimolo esterno agisce su un sistema vivente che ha già una configurazione precedente. Uno stimolo può influenzare uno stato eccitatorio o inibitorio, ma mai uno statico. È come una palla su un campo da calcio: la stessa traiettoria provoca risultati diversi a seconda delle posizioni dinamiche dei giocatori. Con un percorso identico, il gioco può fallire o diventare un assist decisivo.
I meccanismi che mantengono i neuroni attivi indipendentemente dagli stimoli immediati sono ben noti.
Uno di essi consiste in input sottosoglia, che alterano il potenziale di membrana senza generare un potenziale d'azione.
Altri includono sinapsi silenziose e spine dendritiche, che preservano la connettività latente tra i neuroni o promuovono l'attivazione locale.
Il meccanismo più importante coinvolge i recettori metabotropici legati ai neurotrasmettitori, che organizzano il contesto. Non determinano direttamente se viene attivato un potenziale d'azione. Invece, definiscono ciò che è rilevante o meno, quale previsione di ricompensa porta uno stimolo, quale livello di allerta o pericolo è presente, quanta novità esiste nel sistema, quale grado di attenzione sostenuta è richiesto, quale equilibrio tra esplorazione e sfruttamento è appropriato, cosa dovrebbe essere codificato rispetto a ciò che va dimenticato, come viene regolato lo stato interno e quando il controllo degli impulsi o la stabilità temporale è vantaggioso.
In altre parole, i recettori metabotropici implementano una forma di metacontrollo saggio. Non sono dati, ma parametri! Funzionano come variabili dinamiche che regolano il comportamento del sistema. Permettono al sistema di diventare sensibile al significato funzionale di una situazione (novità, rilevanza, ricompensa o minaccia) senza richiedere risposte immediate.
Tornando alla metafora del calcio, i recettori metabotropici corrispondono alle tattiche di squadra: decidere quando attaccare o difendere, cioè, decidere come si gioca.
Da una prospettiva computazionale, questi meccanismi operano attraverso stati intermedi. Non sono binari (attivo/inattivo). Il sistema opera in tre modalità: eccitatorio, inibitorio e uno stato intermedio che non produce output immediato ma modula le dinamiche future.
Quando parliamo di ternario nelle reti cerebrali biologiche, non ci riferiamo a un'astrazione matematica o a un calcolo ma a una descrizione funzionale letterale di come il cervello mantiene l'equilibrio nel tempo.
Per questo motivo, le neuroscienze computazionali non studiano principalmente le mappature input-output, ma piuttosto come gli stati si riorganizzano continuamente. Questi stati sono fondamentalmente predittivi per natura (Friston, 2010; Deco et al., 2009).
Gli LLM sono calcoli binari.
Nei modelli di linguaggio di grandi dimensioni, il concetto di ternarietà non ha senso. L'apprendimento si basa fondamentalmente sulla retropropagazione dell'errore. Vale a dire, una volta che è nota l'entità dell'errore rispetto ai dati attesi, un algoritmo di ottimizzazione regola i parametri utilizzando un segnale esterno.
Come funziona? Il modello produce un output, ad esempio la previsione della parola successiva più probabile: "Parigi è la capitale di ...". Se la risposta è Finlandia, questa viene confrontata con la parola corretta del set di addestramento (Francia). Da questo confronto, viene calcolato un errore numerico. Questo errore quantifica quanto la previsione si discosti dal valore atteso. L'errore viene quindi trasformato in un gradiente, ossia un segnale matematico che indica in quale direzione e di quanto i parametri del modello dovrebbero essere regolati per ridurre l'errore. I pesi vengono aggiornati all'indietro solo dopo che l'output è stato prodotto e valutato.
L'errore è calcolato a posteriori, i pesi sono regolati affinché la risposta corretta diventi Francia, e il sistema riprende a funzionare come se nulla fosse accaduto.
Nei modelli di linguaggio di grandi dimensioni, la separazione tra dinamiche e apprendimento è particolarmente pronunciata. Durante l'inferenza, i parametri rimangono fissi; non c'è plasticità online, nessuna abituzione, nessuna fatica e nessuna adattamento dipendente dal tempo. Il sistema non cambia essendo attivo.
Nella metafora del calcio, gli LLM somigliano a un allenatore che rivede gli errori dopo la partita e regola le tattiche per la successiva. Ma durante la partita stessa, la squadra gioca i novanta minuti pieni senza alcuna possibilità di modifica tecnica o tattica!
C'è strategia pre-partita e correzione post-partita, ma nessun dinamismo durante il gioco!
Gli LLM non sono quindi ternari in un senso funzionale. Sono matrici di "attenzione" (transformers) addestrati offline (Vaswani et al., 2017). Questa non è una limitazione quantitativa ma una differenza ontologica.
Dinamiche trinarie di Neuraxon e Aigarth
Neuraxon introduce un framework fondamentalmente diverso. La sua unità base non è una funzione di input-output, come negli LLM, ma uno stato interno continuo che evolve nel tempo. In Neuraxon, l'eccitazione è rappresentata come +1, l'inibizione come −1, e tra questi due stati esiste un intervallo neutro rappresentato da 0.
In ogni momento, il sistema integra l'influenza degli input attuali, della storia recente e dei meccanismi interni per generare un output trinomiale discreto (eccitazione, inibizione o neutralità).
La relazione tra tempo e ternario è centrale. Lo stato neutro non rappresenta l'assenza di calcolo o inattività ma una fase sottosoglia in cui il sistema accumula influenza senza produrre output immediato. È comparabile a un cambiamento tattico dinamico in una squadra di calcio, indipendentemente dal fatto che porti a un gol a favore o contro.
Aigarth esprime la stessa logica a livello strutturale. Non solo le unità stesse sono ternarie, ma la rete può crescere, riorganizzarsi o collassare a seconda della sua utilità, introducendo una dimensione evolutiva che rinforza l'adattamento continuo. La combinazione Neuraxon–Aigarth (micro–macro) dà origine a tessuti computazionali capaci di rimanere attivi (unità di tessuto intellettivo), qualcosa di impossibile per architetture basate esclusivamente sulla retropropagazione.
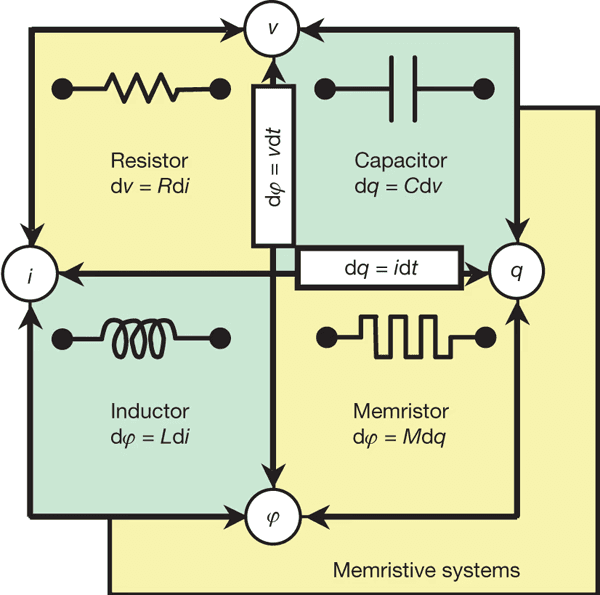
La questione dell'hardware non può essere ignorata. Attualmente, non esiste hardware ternario di uso generale, ma ci sono linee di ricerca attive nella logica ternaria, inclusi memristori multivalenti e calcolo neuromorfico basato su dispositivi resistivi o spintronici (Yang et al., 2013; Indiveri & Liu, 2015). Questi approcci mirano a ridurre il consumo energetico e, cosa più importante, a raggiungere un calcolo ternario allineato con le dinamiche fisiche, vive e continue.
Ha senso un'architettura ternaria anche senza hardware ternario dedicato? Nonostante questa limitazione, sì, perché l'architettura precede il substrato fisico. Progettando sistemi ternari, riveliamo l'incapacità della logica binaria di riflettere un mondo dinamico. Allo stesso tempo, architetture ternarie come Neuraxon–Aigarth possono già fornire miglioramenti sull'hardware binario esistente riducendo attività non necessarie.
Riferimenti
Deco, G., Jirsa, V. K., Robinson, P. A., Breakspear, M., & Friston, K. J. (2009). Il cervello dinamico: dai neuroni che scaricano alle masse neurali e campi corticali. PLoS Computational Biology, 5(8), e1000092.
Friston, K. (2010). Il principio dell'energia libera: una teoria unificata del cervello? Nature Reviews Neuroscience, 11(2), 127–138.
Indiveri, G., & Liu, S.-C. (2015). Memoria e elaborazione delle informazioni nei sistemi neuromorfici. Proceedings of the IEEE, 103(8), 1379–1397.
Northoff, G. (2018). Il cervello spontaneo: dal problema mente-corpo a una neurofenomenologia. MIT Press.
Vaswani, A., Shazeer, N., Parmar, N., et al. (2017). L'attenzione è tutto ciò di cui hai bisogno. Advances in Neural Information Processing Systems, 30.
Yang, J. J., Strukov, D. B., & Stewart, D. R. (2013). Dispositivi memristivi per il calcolo. Nature Nanotechnology, 8(1), 13–24.