
Scritto dal Team Scientifico Qubic

Accademia di Intelligenza Neuraxon — Volume 4
La parola rete appare costantemente sia nella neuroscienza che nell'intelligenza artificiale. Ma nonostante condividano la stessa etichetta, le reti neurali biologiche e le reti neurali artificiali sono sistemi fondamentalmente diversi. Per capire cosa fa ciascuno di essi e dove si inserisce un terzo approccio, dobbiamo esaminare l'architettura e il comportamento delle reti a ogni livello.
Reti Neurali Biologiche: Come il Cervello Elabora le Informazioni
Una rete neurale biologica è un sistema di neuroni interconnessi la cui funzione è elaborare informazioni e generare comportamento. Queste reti sono dinamiche. Rimangono attive nel tempo, anche quando non siamo impegnati consapevolmente in alcun compito. Comportano un costo energetico, che nel caso del cervello umano è notevolmente basso per la complessità che produce.
Le reti biologiche integrano sia segnali interni che esterni utilizzando il loro linguaggio: tempo-frequenza. Pensa a una band musicale con più strumenti che suonano a ritmi diversi. La grancassa mantiene il ritmo, il basso suona due note per battuta e i piatti riempiono i sedicesimi. La melodia si muove liberamente senza perdere il ritmo. I musicisti accoppiano i loro spartiti a ritmi diversi che si incastrano perfettamente. Queste sono frequenze nidificate, e questo è esattamente come funzionano le reti cerebrali. Il linguaggio tempo-frequenza di diverse reti si nidifica al suo interno, un concetto noto come accoppiamento incrociato delle frequenze.
Da neuroni singoli a reti massive
Tutto inizia con il neurone. Quella singola cellula nervosa genera un potenziale d'azione, un breve impulso elettrico che si propaga lungo l'assone. Il neurone riceve segnali attraverso i dendriti, li integra nel soma e trasmette il segnale se supera una soglia. Abbiamo coperto questo processo in dettaglio nel NIA Volume 1: Perché l'intelligenza non è calcolata in passaggi, ma nel tempo e nel NIA Volume 2: Dinamiche ternarie come modello di intelligenza vivente.
I neuroni si connettono ad altri neuroni attraverso sinapsi chimiche, dove i neurotrasmettitori vengono rilasciati (vedi NIA Volume 3: Neuromodulazione e IA ispirata al cervello), o attraverso sinapsi elettriche, dove la corrente passa direttamente tra le cellule. Per formare reti, molti neuroni si interconnettono e creano circuiti ricorrenti. Ma questa integrazione è non lineare, il che significa che la risposta dell'intero non è uguale alla semplice somma delle sue parti. L'entità è sbalorditiva: il cervello umano contiene circa 86 miliardi di neuroni e da qualche parte tra 10¹⁴ e 10¹⁵ sinapsi (Azevedo et al., 2009).
Proprietà Small-World e equilibrio eccitazione-inibizione
A livello topologico, queste reti mostrano proprietà small-world: alta aggregazione locale combinata con connessioni globali brevi. Questa architettura consente una comunicazione efficiente attraverso il cervello mantenendo al contempo un'elaborazione locale specializzata.
Il funzionamento delle reti neurali biologiche dipende dall'equilibrio tra eccitazione e inibizione. Se l'eccitazione domina, l'attività si destabilizza. Se l'inibizione domina, la rete tace. La stabilità dinamica deriva dall'equilibrio tra entrambe le forze. Questo equilibrio è mantenuto attraverso la plasticità sinaptica, il meccanismo che consente alla forza delle connessioni di cambiare in base all'esperienza. Inoltre, la neuromodulazione regola il guadagno del circuito, controllando quanto fortemente un input produce un output (Marder, 2012). In una situazione minacciosa, ad esempio, la noradrenalina aumenta la sensibilità sensoriale e la capacità di apprendimento rapido.
Multiple scale temporali e funzione cerebrale della corteccia cerebrale
Le reti operano a più scale temporali simultaneamente. A livello neuronale, i potenziali d'azione si attivano in millisecondi. Le oscillazioni neuronali si svolgono in secondi. I cambiamenti sinaptici si sviluppano nell'arco di ore o giorni, e la riorganizzazione strutturale avviene nel corso degli anni. Tutto funziona in un modello armonico, dinamico e intrecciato.
Ma non tutto comunica con tutto senza struttura. La funzione del cervello della corteccia cerebrale è organizzata in reti specializzate. Le più importanti includono la rete di modalità predefinita, collegata all'auto-riferimento e al pensiero su se stessi e sugli altri; la rete esecutiva centrale, collegata all'esecuzione diretta dei compiti; la rete di salienza, che rileva ciò che è rilevante in ogni momento e consente di passare tra diversi modi; la rete sensorimotoria che sostiene i movimenti volontari; e varie reti di attenzione. Gli esseri umani possiedono anche una rete linguistica distintiva, che consente sia la comprensione che la produzione del linguaggio.
Nelle reti biologiche, nessuna nota isolata è una sinfonia. La sinfonia emerge dal modello dinamico delle relazioni tra le note. Il cervello non contiene cose. Non immagazzina ricordi come un disco rigido immagazzina file. Il cervello costruisce configurazioni dinamiche.
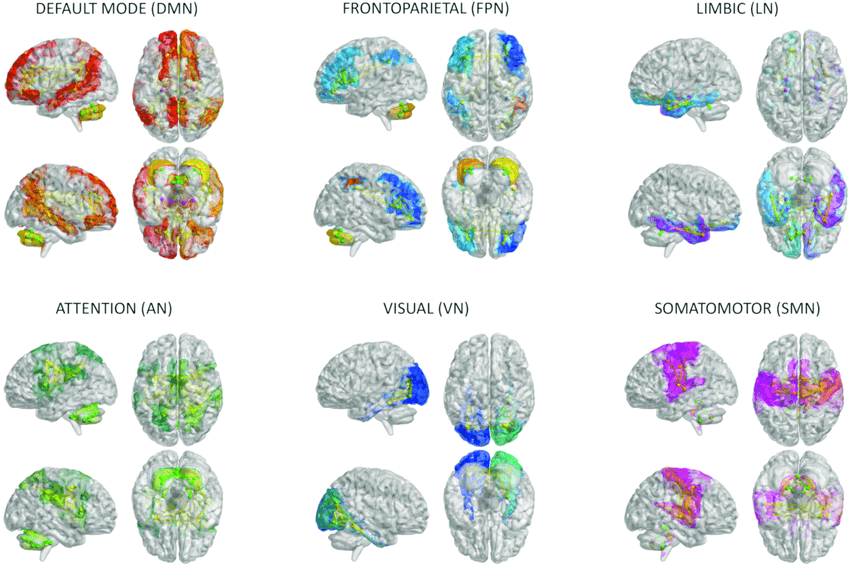 Per gentile concessione di DOI: 10.3389/fnagi.2023.1204134
Per gentile concessione di DOI: 10.3389/fnagi.2023.1204134
Reti neurali artificiali: Come funzionano i modelli di apprendimento profondo
Una rete neurale artificiale (ANN) è un modello matematico progettato per approssimare funzioni complesse dai dati. Trae ispirazione astratta dal cervello: utilizza unità interconnesse chiamate "neuroni artificiali", ma questi non sono cellule. Sono operazioni algebriche. Chiamare un'operazione algebrica un neurone è discutibilmente un'iperbole esagerata, e chiamare la previsione del linguaggio "intelligenza" può essere altrettanto fuorviante. Ma poiché questi sono i termini stabiliti, è importante comprenderli e separare la sostanza dalla pubblicità.
Come funziona un neurone artificiale
Ogni neurone artificiale esegue tre passaggi. Prima riceve un insieme di input numerici. Poi moltiplica ogni input per un peso sinaptico, che è un parametro regolabile. Infine, somma i risultati e applica una funzione di attivazione che introduce non linearità. Le funzioni di attivazione comuni includono la Sigmoide, che comprime i valori tra 0 e 1, e la ReLU (Unità Lineare Rettificata), che annulla i valori negativi e lascia passare quelli positivi.
Senza non linearità, la rete eseguirebbe semplicemente una trasformazione lineare, incapace di modellare schemi complessi. Gli ANN sono organizzati in strati di input, dove i dati entrano; strati nascosti, dove i dati vengono progressivamente trasformati; e uno strato di output, che genera la previsione.
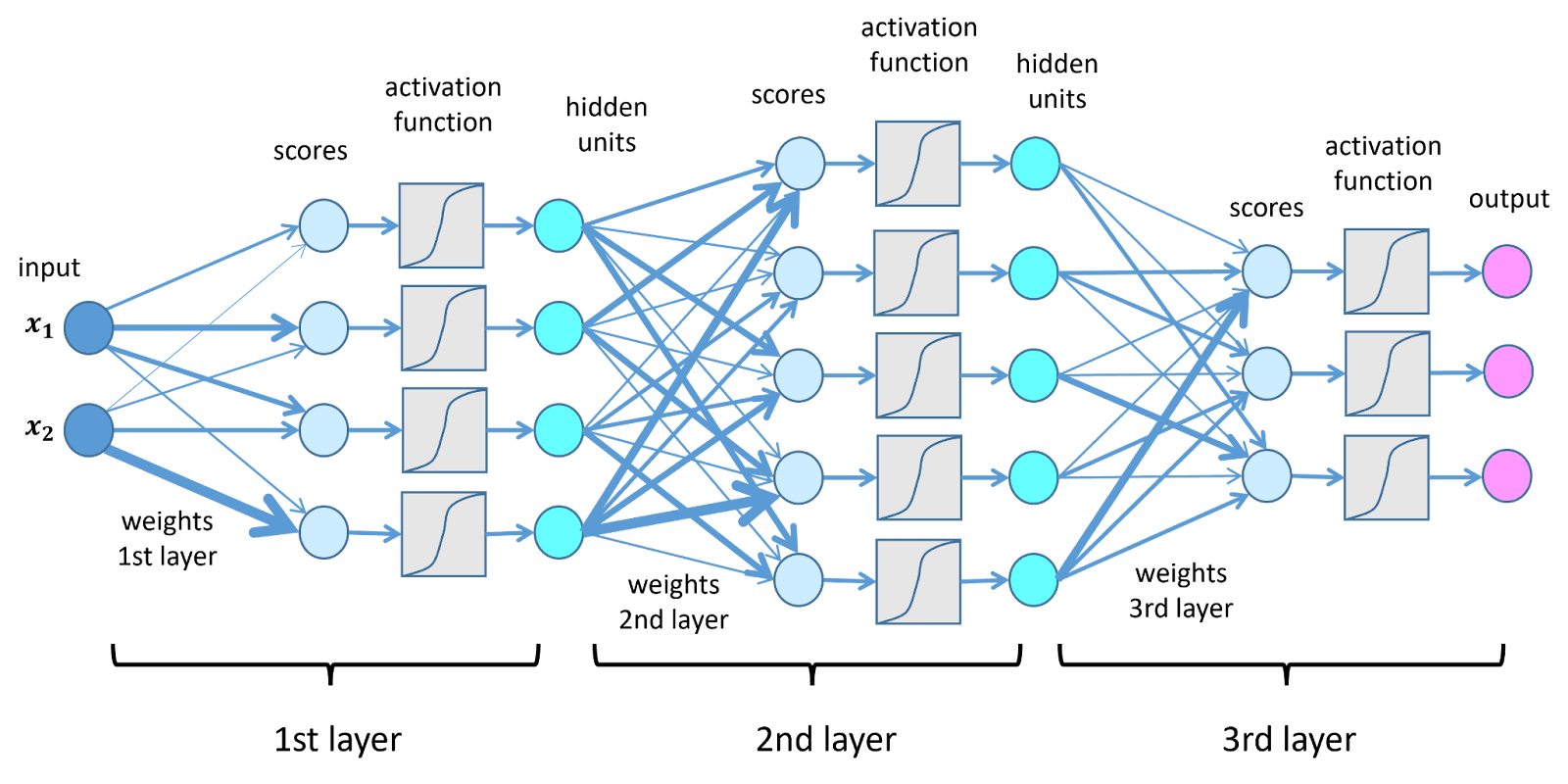
Dal Perceptron all'Apprendimento Profondo
Tutte le architetture moderne tracciano le loro origini al perceptron (Rosenblatt, 1958), un semplice neurone lineare con una soglia. Le moderne reti di apprendimento profondo possono contenere centinaia di strati e miliardi di parametri. Ma al loro interno, un ANN funziona come un enorme foglio di calcolo automatizzato che regola milioni di celle numeriche fino a quando l'output non corrisponde al risultato atteso.
Retropropagazione e discesa del gradiente: come apprendono le reti artificiali
L'apprendimento nelle reti artificiali non funziona come l'apprendimento biologico. Non c'è aggiustamento dei neuromodulatori o dell'intensità sinaptica basato sull'esperienza vissuta. Invece, l'apprendimento si basa sulla minimizzazione di una funzione di errore che quantifica la differenza tra la previsione della rete e la risposta corretta.
Considera un semplice esempio: il modello è invitato a completare "Parigi è la capitale di..." Se la previsione è l'Italia, la funzione di errore misura il divario tra Italia e Francia, quindi regola i pesi di conseguenza. Il meccanismo centrale dietro questo aggiustamento è la retropropagazione (Rumelhart et al., 1986). Questo algoritmo calcola l'errore all'uscita, propaga quell'errore all'indietro strato per strato e regola i pesi utilizzando la discesa del gradiente, un metodo matematico che modifica i parametri nella direzione che riduce l'errore.
Formalmente, l'apprendimento consiste nell'ottimizzare una funzione differenziabile in uno spazio di molte dimensioni. Se pensi allo spazio fisico, le dimensioni sono x, y e z. Ma nel linguaggio, immagina dimensioni come singolare, plurale, femminile, maschile, verbo, soggetto, attributo, sostantivo, aggettivo, intonazione e sinonimo. Introduci milioni di dimensioni e abbastanza potenza computazionale, e un modello può imparare che Parigi è la capitale della Francia semplicemente riducendo gli errori di previsione durante l'addestramento.
Architetture delle reti neurali artificiali
Sebbene la terminologia si sovrapponga con la neuroscienza, il processo non assomiglia a come un sistema vivente apprende. In un ANN, l'aggiustamento dipende da calcoli globali e dalla conoscenza esplicita dell'errore finale. La rete deve sapere esattamente quanto era sbagliata.
Se una rete impara a riconoscere i gatti, riceve migliaia o milioni di immagini etichettate. Ogni volta che fallisce, regola leggermente i pesi. Dopo milioni di iterazioni, il modello interno si stabilizza in una configurazione che discrimina i gatti da altri oggetti. Il processo è puramente statistico. La rete non "comprende" cosa sia un gatto. Rileva correlazioni numeriche nei pixel. Non possiede un "modello del mondo" di un gatto, solo matrici di numeri su scale massive. Per uno sguardo più profondo su perché questo sia importante, leggi la nostra analisi sul benchmarking dell'apprendimento del modello del mondo.
Ci sono diverse architetture chiave delle reti neurali artificiali. Le reti convoluzionali (CNN) utilizzano filtri spaziali che rilevano bordi, texture e modelli gerarchici, rendendole essenziali per la visione artificiale. Le reti ricorrenti (RNN, LSTM) incorporano memoria temporale per l'elaborazione delle sequenze. E i Transformer, ora dominanti, utilizzano meccanismi di attenzione che pesano dinamicamente quali parti dell'input sono più rilevanti (Vaswani et al., 2017). I Transformer attualmente alimentano la maggior parte dei modelli di linguaggio di grandi dimensioni nell'elaborazione del linguaggio naturale.
La crescita di queste reti non avviene organicamente come nei sistemi viventi. Avviene attraverso un design esplicito e una scalatura dei parametri tramite un addestramento massiccio in centri di calcolo ad alte prestazioni. L'adattamento è limitato al periodo di addestramento. Una volta addestrata, la rete non riorganizza spontaneamente la sua architettura. Qualsiasi modifica richiede un nuovo processo di ottimizzazione. Come abbiamo esplorato in Che l'IA statica è un vicolo cieco, questa natura congelata è una limitazione fondamentale degli attuali sistemi di IA.
Nonostante condividano il nome "rete", la somiglianza tra reti neurali artificiali e biologiche è limitata. L'analogia è strutturale e astratta: entrambe utilizzano unità interconnesse e apprendimento attraverso l'aggiustamento delle connessioni. Ma il cervello è un sistema evolutivo, incarnato e autoregolato. Un ANN è un ottimizzatore di funzioni in uno spazio numerico.
Tra reti biologiche e artificiali: come Neuraxon Aigarth colma il divario
Le reti simulate in Neuraxon Aigarth sono concettualmente posizionate tra reti biologiche e reti neurali artificiali convenzionali. Non sono tessuti viventi, ma non sono neppure semplici funzioni matematiche ottimizzate dal gradiente. Il loro obiettivo è approssimare dinamiche tipiche dei sistemi biologici, inclusa la plasticità multiscala, la modulazione dipendente dal contesto e l'auto-organizzazione, il tutto all'interno di un framework computazionale costruito per l'infrastruttura decentralizzata di Qubic.
Se nel Volume 1 abbiamo descritto sistemi metabolici auto-organizzati e nel Volume 2 abbiamo esplorato funzioni di ottimizzazione differenziabile, Neuraxon tenta di incorporare proprietà dinamiche dei primi senza abbandonare la formalizzazione matematica dei secondi.
Stati trivalenti: Catturare l'equilibrio eccitazione-inibizione
Invece di attivazioni continue tipiche (valori reali dopo una ReLU, ad esempio), Neuraxon utilizza stati trivalenti: -1, 0 e +1. Qui, +1 rappresenta l'attivazione eccitatoria, -1 rappresenta l'attivazione inibitoria e 0 rappresenta riposo o inattività.
Questo schema non tenta di copiare il potenziale d'azione biologico. Piuttosto, cattura il principio funzionale dell'equilibrio eccitazione-inibizione descritto nella sezione delle reti biologiche sopra. Nel cervello, la stabilità emerge dall'equilibrio tra queste forze. In Neuraxon, lo spazio degli stati discreti impone una dinamica più vicina ai sistemi di transizione di stato che a semplici trasformazioni continue.
A differenza delle reti artificiali classiche, dove l'attivazione è un numero in virgola mobile senza significato fisiologico, il sistema trivalente impone vincoli strutturali che plasmano come l'attività si propaga attraverso la rete.
Plasticità a doppio peso: apprendimento veloce e lento
Le reti neurali biologiche mostrano plasticità a diverse scale temporali: cambiamenti rapidi nell'efficacia sinaptica e una consolidazione più lenta nel tempo. Neuraxon introduce questa idea attraverso due componenti di peso:
w_fast: cambiamenti rapidi che sono sensibili all'ambiente immediato.
w_slow: cambiamenti lenti che stabilizzano schemi ripetuti nel tempo.
Questo impedisce al sistema di dipendere esclusivamente da un aggiornamento di peso omogeneo come la retropropagazione standard. Parte dell'apprendimento può essere transitoria, mentre un'altra parte è gradualmente consolidata. Questo meccanismo introduce una dimensione assente nella maggior parte delle reti neurali artificiali: il tasso di apprendimento non è fisso, ma dipende dallo stato globale del sistema.
Neuromodulazione contestuale attraverso la variabile meta
Nelle reti biologiche, i neuromodulatori come la noradrenalina e la dopamina non trasmettono contenuti informativi specifici. Invece, alterano il guadagno e la plasticità di ampie popolazioni neuronali. Abbiamo esplorato questo in profondità nel NIA Volume 3: Neuromodulazione e IA ispirata al cervello.
In Neuraxon, la variabile meta gioca un ruolo funzionalmente analogo. Non codifica informazioni specifiche, ma modifica l'entità dell'aggiornamento sinaptico. Questo approssima il principio biologico secondo cui l'apprendimento dipende dal contesto motivazionale o di salienza. In una rete artificiale convenzionale, il gradiente viene applicato uniformemente in base all'errore. In Neuraxon, l'apprendimento può essere intensificato o attenuato a seconda dello stato interno o dei segnali esterni globali.
La differenza concettuale è significativa. Nelle reti di apprendimento profondo classiche, l'errore guida l'apprendimento. In Neuraxon, l'errore può coesistere con un segnale modulatore contestuale che altera quanto viene appreso in un dato momento.
Criticalità auto-organizzata e comportamento adattivo
Le reti biologiche operano vicino a un regime chiamato criticalità auto-organizzata, dove il sistema mantiene un equilibrio tra ordine e caos. Questo regime consente flessibilità senza perdita di stabilità.
Neuraxon modella questa proprietà consentendo alla rete di evolversi verso stati dinamici intermedi in cui piccole perturbazioni possono produrre ampie riorganizzazioni senza far collassare il sistema.
In modelli come il Gioco della Vita esteso con propriocezione che il team sta attualmente sviluppando, il sistema può ricevere segnali esterni (ambiente) e segnali interni (il proprio stato, energia, collisioni precedenti). Se un agente collide ripetutamente con un ostacolo, potrebbe essere generato un aumento nel segnale meta, analogo a un aumento dell'eccitazione. Quel segnale aumenta temporaneamente la plasticità, facilitando la riorganizzazione strutturale.
Qui, la rete non impara solo perché commette errori. Impara perché l'ambiente acquisisce rilevanza adattativa. La somiglianza con il cervello rimane limitata: Neuraxon non possiede biologia, metabolismo o esperienza soggettiva. Tuttavia, introduce dimensioni dinamiche assenti nella maggior parte delle reti neurali artificiali convenzionali, posizionandola come un approccio genuinamente nuovo all'IA ispirata al cervello su infrastruttura decentralizzata.
La potenza computazionale necessaria per eseguire le simulazioni di Neuraxon è fornita dalla rete globale di mineratori di Qubic attraverso il Proof of Work utile, trasformando l'addestramento dell'IA nel meccanismo di consenso stesso.

Riferimenti scientifici
#Azevedo, F. A. C., et al. (2009). Numeri uguali di cellule neuronali e non neuronali rendono il cervello umano un cervello primate scalato isometricamente. Journal of Comparative Neurology, 513(5), 532-541. DOI: 10.1002/cne.21974
#Marder, E. (2012). Neuromodulazione dei circuiti neuronali: Torniamo al futuro. Neuron, 76(1), 1-11. DOI: 10.1016/j.neuron.2012.09.010
#Rosenblatt, F. (1958). Il Perceptron: un modello probabilistico per l'immagazzinamento e l'organizzazione delle informazioni nel cervello. Psychological Review, 65(6), 386-408. DOI: 10.1037/h0042519
#Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Apprendere rappresentazioni retropropagando errori. Nature, 323(6088), 533-536. DOI: 10.1038/323533a0
#Vaswani, A., et al. (2017). L'attenzione è tutto ciò di cui hai bisogno. Advances in Neural Information Processing Systems, 30. arXiv: 1706.03762
Immagini delle reti cerebrali per gentile concessione: DOI: 10.3389/fnagi.2023.1204134