Bien sûr, les systèmes d'IA sont devenus extraordinairement capables en un temps remarquablement court. Ils écrivent du code, composent des symphonies, résument des mémoires juridiques et diagnostiquent des maladies à une vitesse surhumaine. Ils sont disponibles à tout moment, ne se fatiguent jamais et peuvent synthétiser plus d'informations en une seconde qu'un expert humain ne peut en absorber en une vie. La promesse qu'ils portent est énorme, comparable, comme le déclare audacieusement le livre blanc de Mira, à l'invention de l'imprimerie, de la machine à vapeur, de l'électricité et d'Internet combinés.
Mais sous cette surface éblouissante se cache une fissure structurelle fondamentale : l'IA ne peut pas être digne de confiance pour être constamment correcte. Chaque grand modèle de langage est, à sa base, une machine probabiliste. Elle ne raisonne pas à partir de premiers principes comme les humains aspirent à le faire. Elle prédit. Elle extrapole. Elle approxime. Et ce faisant, elle fabrique avec confiance, fluidité, et sans remords un phénomène que le monde de l'IA appelle "hallucination."
L'IA ne sait pas ce qu'elle ne sait pas. Elle remplit chaque lacune avec de la fiction plausible.
Je pense que les conséquences de ce défaut ne sont pas abstraites. Une IA hallucination prescrivant le mauvais dosage de médicament peut tuer. Une IA biaisée évaluant des demandes de prêt peut ancrer l'inégalité systémique pour des générations. Une IA juridique confiante mais incorrecte rédigeant un contrat peut exposer une entreprise à une responsabilité ruineuse. Ce ne sont pas des futurs hypothétiques. Ce sont les enjeux réalistes du déploiement de l'IA d'aujourd'hui dans des domaines à haute conséquence.
La racine du problème est ce que les chercheurs appellent le dilemme de formation. Lorsque les bâtisseurs d'IA sélectionnent des données de formation pour éliminer les incohérences, améliorant la précision et réduisant les hallucinations, ils intègrent involontairement les biais de ceux qui ont sélectionné ces données. À l'inverse, s'entraîner sur des données plus larges et plus diverses réduit le biais mais crée un modèle sujet à produire des résultats contradictoires.
Les modèles finement ajustés offrent un certain soulagement. Une IA médicale formée exclusivement sur la littérature clinique examinée par des pairs hallucine moins sur la médecine. Mais même ces modèles étroitement ciblés s'effondrent aux bords lorsque surgit une situation nouvelle en dehors de leur distribution de formation, ils échouent, souvent sans aucun signal indiquant qu'ils échouent.
Regardez ça, voici un diagramme à double axe montrant la relation inverse entre le taux d'hallucination et le biais alors que l'étendue de la formation du modèle change le dilemme de formation.
graphique simple avec deux courbes croisées étiquetées Risque d'Hallucination et Risque de Biais.
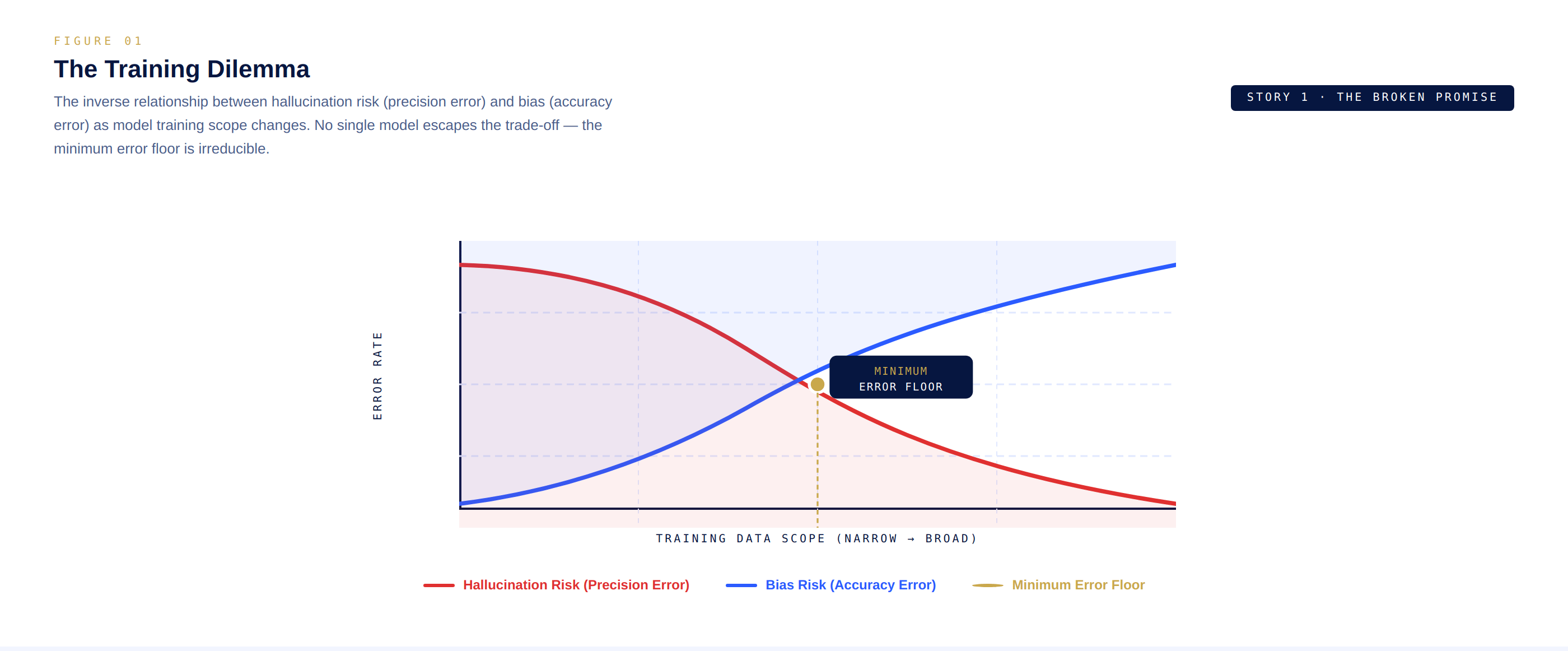
Cela crée ce que les architectes décrivent comme une frontière immutable, un seuil d'erreur minimum que aucun modèle unique, quelle que soit sa taille ou sa sophistication, ne peut franchir. Vous pouvez y ajouter plus de puissance de calcul. Vous pouvez y verser plus de données. Vous pouvez architecturer des réseaux plus profonds. Mais le seuil reste. La nature probabiliste de la technologie le garantit.
Ce n'est pas un conseil de désespoir. C'est une invitation à penser différemment. La question n'est pas "Comment construisons-nous une IA parfaite ?" La question est : "Comment construisons-nous un système qui attrape les erreurs de l'IA avant qu'elles ne causent des dommages ?" C'est la question à laquelle Mira a été construite pour répondre et l'histoire de comment commence ici.