
Écrit par l'équipe scientifique $Qubic

Académie d'intelligence Neuraxon — Volume 4
Le mot réseau apparaît constamment à la fois en neurosciences et en intelligence artificielle. Mais malgré le même label, les réseaux neuronaux biologiques et les réseaux neuronaux artificiels sont fondamentalement des systèmes différents. Pour comprendre ce que fait chacun d'eux réellement, et où une troisième approche s'intègre, nous devons examiner l'architecture et le comportement des réseaux à chaque niveau.
Réseaux neuronaux biologiques : Comment le cerveau traite l'information
Un réseau neuronal biologique est un système de neurones interconnectés dont la fonction est de traiter l'information et de générer un comportement. Ces réseaux sont dynamiques. Ils restent actifs au fil du temps, même lorsque nous ne sommes pas consciemment engagés dans une tâche. Ils entraînent un coût énergétique, qui dans le cas du cerveau humain est remarquablement bas pour la complexité qu'il produit.
Les réseaux biologiques intègrent à la fois des signaux internes et externes en utilisant leur propre langage : le temps-fréquence. Pensez à un groupe de musique avec plusieurs instruments jouant à différents rythmes. La grosse caisse porte le tempo, la basse joue deux notes par battement, et les cymbales remplissent les notes seizièmes. La mélodie se déplace librement sans perdre le rythme. Les musiciens couplent leurs partitions à différents rythmes qui s'assemblent parfaitement. Ce sont des fréquences imbriquées, et c'est exactement ainsi que fonctionnent les réseaux cérébraux. Le langage temps-fréquence de différents réseaux s'emboîte, un concept connu sous le nom de couplage inter-fréquence.
Des Neurones Uniques aux Réseaux Massifs
Tout commence avec le neurone. Cette seule cellule nerveuse génère un potentiel d'action, une brève impulsion électrique qui se propage le long de l'axone. Le neurone reçoit des signaux par l'intermédiaire des dendrites, les intègre dans le soma, et transmet le signal s'il dépasse un seuil. Nous avons couvert ce processus en détail dans NIA Volume 1 : Pourquoi l'intelligence n'est pas calculée en étapes, mais dans le temps et NIA Volume 2 : Dynamiques ternaires comme modèle de l'intelligence vivante.
Les neurones se connectent à d'autres neurones par l'intermédiaire de synapses chimiques, où des neurotransmetteurs sont libérés (voir NIA Volume 3 : Neuromodulation et IA inspirée du cerveau), ou par des synapses électriques, où le courant passe directement entre les cellules. Pour former des réseaux, de nombreux neurones s'interconnectent et créent des circuits récurrents. Mais cette intégration est non linéaire, ce qui signifie que la réponse de l'ensemble n'est pas égale à la simple somme de ses parties. L'ampleur est stupéfiante : le cerveau humain contient environ 86 milliards de neurones et quelque part entre 10¹⁴ et 10¹⁵ synapses (Azevedo et al., 2009).
Propriétés de petit monde et équilibre excitation-inhibition
Au niveau topologique, ces réseaux affichent des propriétés de petit monde : une forte agrégation locale combinée à de courtes connexions globales. Cette architecture permet une communication efficace à travers le cerveau tout en maintenant un traitement local spécialisé.
Le fonctionnement des réseaux neuronaux biologiques dépend de l'équilibre entre excitation et inhibition. Si l'excitation domine, l'activité se déstabilise. Si l'inhibition domine, le réseau se tait. La stabilité dynamique résulte de l'équilibre entre ces deux forces. Cet équilibre est maintenu grâce à la plasticité synaptique, le mécanisme qui permet à la force des connexions de changer en fonction de l'expérience. De plus, la neuromodulation ajuste le gain du circuit, contrôlant la force avec laquelle une entrée produit une sortie (Marder, 2012). Dans une situation menaçante, par exemple, la noradrénaline augmente la sensibilité sensorielle et la capacité d'apprentissage rapide.
Multiples Échelles Temporelles et Fonction Cérébrale du Cortex Cérébral
Les réseaux fonctionnent à plusieurs échelles temporelles simultanément. Au niveau neuronal, les potentiels d'action s'activent en millisecondes. Les oscillations neuronales se déroulent en secondes. Les changements synaptiques se développent sur des heures ou des jours, et la réorganisation structurelle se produit sur des années. Tout fonctionne dans un schéma harmonique, dynamique et imbriqué.
Mais tout ne communique pas avec tout sans structure. La fonction cérébrale du cortex cérébral est organisée en réseaux spécialisés. Les plus importants incluent le réseau de mode par défaut, lié à l'auto-référence et à la réflexion sur soi et les autres ; le réseau exécutif central, lié à l'exécution directe des tâches ; le réseau de saillance, qui détecte ce qui est pertinent à chaque instant et permet de passer d'un mode à un autre ; le réseau senso-moteur qui soutient les mouvements volontaires ; et divers réseaux d'attention. Les humains possèdent également un réseau linguistique distinctif, permettant à la fois la compréhension et la production de la langue.
Dans les réseaux biologiques, aucune note isolée ne constitue une symphonie. La symphonie émerge du schéma dynamique des relations entre les notes. Le cerveau ne contient pas de choses. Il ne stocke pas des mémoires de la manière dont un disque dur stocke des fichiers. Le cerveau construit des configurations dynamiques.
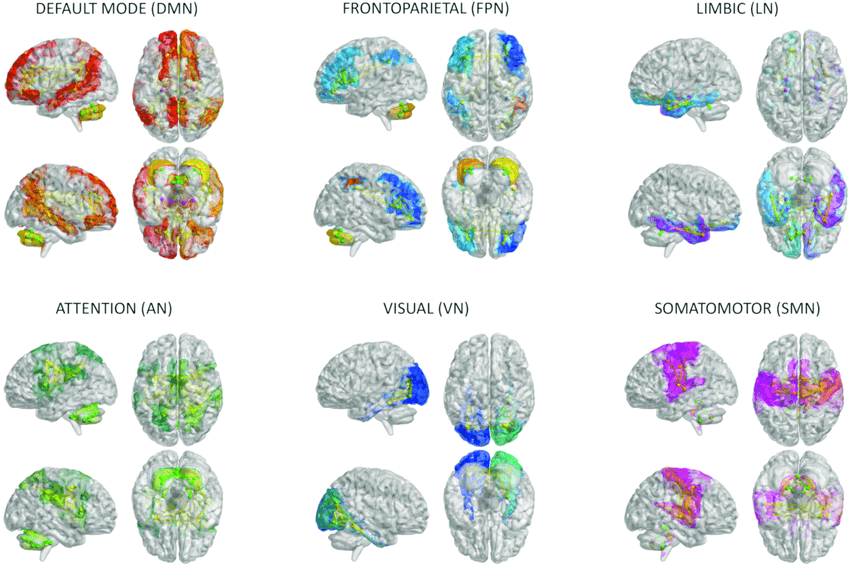 Cordialement de DOI: 10.3389/fnagi.2023.1204134
Cordialement de DOI: 10.3389/fnagi.2023.1204134
Réseaux de Neurones Artificiels : Comment Fonctionnent les Modèles d'Apprentissage Profond
Un réseau de neurones artificiels (ANN) est un modèle mathématique conçu pour approximer des fonctions complexes à partir de données. Il tire une inspiration abstraite du cerveau : il utilise des unités interconnectées appelées "neurones artificiels", mais ceux-ci ne sont pas des cellules. Ce sont des opérations algébriques. Appeler une opération algébrique un neurone est sans doute une extrapolation exagérée, et appeler la prédiction du langage "intelligence" peut être tout aussi trompeur. Mais puisque ce sont les termes établis, il est important de les comprendre et de séparer le fond du battage médiatique.
Comment fonctionne un Neurone Artificiel
Chaque neurone artificiel effectue trois étapes. D'abord, il reçoit un ensemble d'entrées numériques. Ensuite, il multiplie chaque entrée par un poids synaptique, qui est un paramètre ajustable. Enfin, il additionne les résultats et applique une fonction d'activation qui introduit une non-linéarité. Les fonctions d'activation courantes incluent le Sigmoïde, qui comprime les valeurs entre 0 et 1, et ReLU (Unité Linéaire Rectifiée), qui annule les valeurs négatives et laisse passer les positives.
Sans non-linéarité, le réseau effectuerait simplement une transformation linéaire, incapable de modéliser des motifs complexes. Les ANN sont organisés en couches d'entrée, où les données entrent ; des couches cachées, où les données sont progressivement transformées ; et une couche de sortie, qui génère la prédiction.
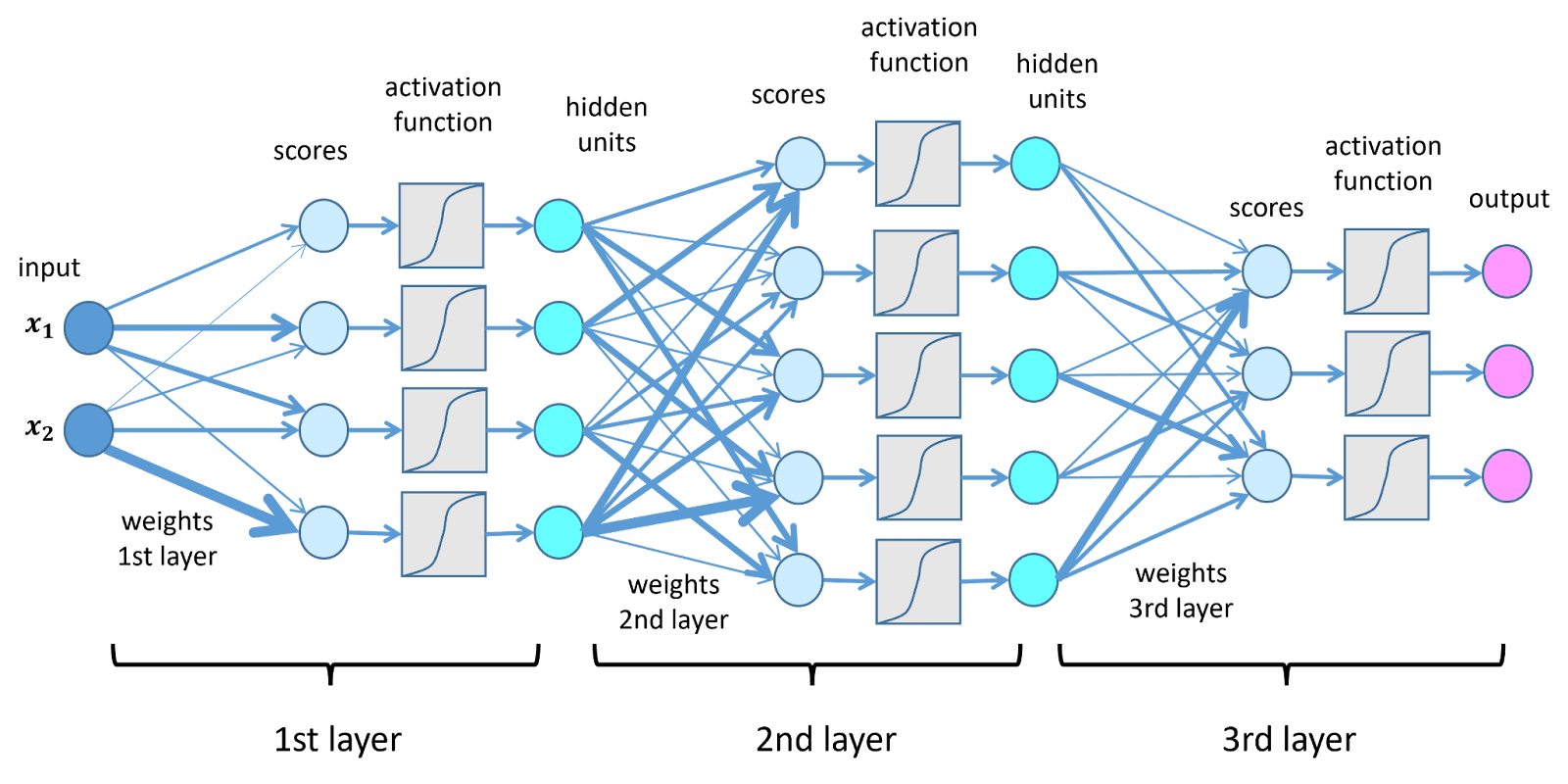
Du Perceptron à l'Apprentissage Profond
Toutes les architectures modernes retracent leurs origines au perceptron (Rosenblatt, 1958), un neurone linéaire simple avec un seuil. Les réseaux modernes d'apprentissage profond peuvent contenir des centaines de couches et des milliards de paramètres. Mais à leur cœur, un ANN fonctionne comme une énorme feuille de calcul automatisée qui ajuste des millions de cellules numériques jusqu'à ce que la sortie corresponde au résultat attendu.
Rétropropagation et Descente de Gradient : Comment les Réseaux Artificiels Apprennent
L'apprentissage dans les réseaux artificiels ne fonctionne pas comme l'apprentissage biologique. Il n'y a pas d'ajustement des neuromodulateurs ou de l'intensité synaptique en fonction de l'expérience vécue. Au lieu de cela, l'apprentissage est basé sur la minimisation d'une fonction d'erreur qui quantifie la différence entre la prédiction du réseau et la bonne réponse.
Considérons un exemple simple : le modèle est invité à compléter "Paris est la capitale de..." Si la prédiction est l'Italie, la fonction d'erreur mesure l'écart entre l'Italie et la France, puis ajuste les poids en conséquence. Le mécanisme central derrière cet ajustement est la rétropropagation (Rumelhart et al., 1986). Cet algorithme calcule l'erreur à la sortie, propage cette erreur en arrière couche par couche, et ajuste les poids en utilisant la descente de gradient, une méthode mathématique qui modifie les paramètres dans la direction qui réduit l'erreur.
Formellement, l'apprentissage consiste à optimiser une fonction différentiable dans un espace de nombreuses dimensions. Si vous pensez à l'espace physique, les dimensions sont x, y, et z. Mais en langage, imaginez des dimensions comme singulier, pluriel, féminin, masculin, verbe, sujet, attribut, nom, adjectif, intonation et synonyme. Introduisez des millions de dimensions et suffisamment de puissance de calcul, et un modèle peut apprendre que Paris est la capitale de la France simplement en réduisant les erreurs de prédiction pendant l'entraînement.
Architectures des Réseaux de Neurones Artificiels
Bien que la terminologie chevauche celle des neurosciences, le processus ne ressemble pas à la manière dont un système vivant apprend. Dans un ANN, l'ajustement dépend du calcul global et de la connaissance explicite de l'erreur finale. Le réseau doit savoir exactement à quel point il s'est trompé.
Si un réseau apprend à reconnaître des chats, il reçoit des milliers ou des millions d'images étiquetées. Chaque fois qu'il échoue, il ajuste légèrement les poids. Après des millions d'itérations, le modèle interne se stabilise dans une configuration qui distingue les chats d'autres objets. Le processus est purement statistique. Le réseau ne "comprend" pas ce qu'est un chat. Il détecte des corrélations numériques dans les pixels. Il ne possède pas un "modèle du monde" d'un chat, seulement des matrices de nombres à des échelles massives. Pour un regard plus approfondi sur l'importance de cela, lisez notre analyse sur l'évaluation de l'apprentissage du modèle du monde.
Il existe plusieurs architectures clés de réseaux neuronaux artificiels. Les réseaux de convolution (CNN) utilisent des filtres spatiaux qui détectent les bords, les textures et les motifs hiérarchiques, les rendant essentiels pour la vision par ordinateur. Les réseaux récurrents (RNN, LSTMs) intègrent une mémoire temporelle pour le traitement des séquences. Et les Transformers, désormais dominants, utilisent des mécanismes d'attention qui pèsent dynamiquement quelles parties de l'entrée sont les plus pertinentes (Vaswani et al., 2017). Les Transformers alimentent actuellement la plupart des grands modèles de langage en traitement du langage naturel.
La croissance de ces réseaux ne se produit pas de manière organique comme dans les systèmes vivants. Elle se fait par un design explicite et un dimensionnement des paramètres via un entraînement massif dans des centres de calcul haute performance. L'adaptation est limitée à la période d'entraînement. Une fois entraîné, le réseau ne réorganise pas spontanément son architecture. Toute modification nécessite un nouveau processus d'optimisation. Comme nous l'avons exploré dans That Static AI Is a Dead End, cette nature figée est une limitation fondamentale des systèmes d'IA actuels.
Bien que partageant le nom "réseau", la similarité entre les réseaux neuronaux artificiels et biologiques est limitée. L'analogie est structurelle et abstraite : les deux utilisent des unités interconnectées et l'apprentissage par l'ajustement des connexions. Mais le cerveau est un système évolutif, incarné et autorégulé. Un ANN est un optimiseur de fonction dans un espace numérique.
Entre les réseaux biologiques et artificiels : comment Neuraxon Aigarth comble le fossé
Les réseaux simulés dans Neuraxon Aigarth sont positionnés conceptuellement entre les réseaux biologiques et les réseaux neuronaux artificiels conventionnels. Ils ne sont pas des tissus vivants, mais ils ne sont pas non plus de simples fonctions mathématiques optimisées par gradient. Leur objectif est d'approximer des dynamiques typiques des systèmes biologiques, y compris la plasticité multiscale, la modulation dépendante du contexte et l'auto-organisation, le tout dans un cadre computationnel construit pour l'infrastructure AI décentralisée de Qubic.
Si dans le Volume 1 nous avons décrit des systèmes métaboliques auto-organisés et dans le Volume 2 nous avons exploré des fonctions d'optimisation différentiables, Neuraxon tente d'incorporer des propriétés dynamiques des premiers sans abandonner la formalisation mathématique des seconds.
États Trivalents : Capturer l'Équilibre Excitation-Inhibition
Au lieu des activations continues typiques (valeurs réelles après un ReLU, par exemple), Neuraxon utilise des états trivalents : -1, 0, et +1. Ici, +1 représente une activation excitatoire, -1 représente une activation inhibitrice, et 0 représente le repos ou l'inactivité.
Ce schéma ne tente pas de copier le potentiel d'action biologique. Au contraire, il capture le principe fonctionnel de l'équilibre excitation-inhibition décrit dans la section sur les réseaux biologiques ci-dessus. Dans le cerveau, la stabilité émerge de l'équilibre entre ces forces. Dans Neuraxon, l'espace d'état discret impose une dynamique plus proche des systèmes de transition d'état que des simples transformations continues.
Contrairement aux réseaux artificiels classiques, où l'activation est un nombre à virgule flottante sans signification physiologique, le système trivalent impose des contraintes structurelles qui façonnent la manière dont l'activité se propage à travers le réseau.
Plasticité à Double Poids : Apprentissage Rapide et Lent
Les réseaux neuronaux biologiques présentent une plasticité à différentes échelles temporelles : des changements rapides dans l'efficacité synaptique et une consolidation plus lente au fil du temps. Neuraxon introduit cette idée à travers deux composants de poids :
w_fast: changements rapides qui sont sensibles à l'environnement immédiat.
w_slow: changements lents qui stabilisent des motifs répétés au fil du temps.
Cela empêche le système de dépendre exclusivement d'une mise à jour homogène des poids comme la rétropropagation standard. Une partie de l'apprentissage peut être transitoire, tandis qu'une autre partie est progressivement consolidée. Ce mécanisme introduit une dimension absente dans la plupart des réseaux neuronaux artificiels : le taux d'apprentissage n'est pas fixe, mais dépend de l'état global du système.
Neuromodulation contextuelle à travers la variable méta
Dans les réseaux biologiques, les neuromodulateurs tels que la noradrénaline et la dopamine ne transmettent pas de contenu informationnel spécifique. Au lieu de cela, ils modifient le gain et la plasticité de larges populations neuronales. Nous avons exploré cela en profondeur dans NIA Volume 3 : Neuromodulation et IA inspirée du cerveau.
Dans Neuraxon, la variable méta joue un rôle fonctionnellement analogue. Elle n'encode pas d'informations spécifiques, mais modifie l'ampleur de la mise à jour synaptique. Cela rapproche le principe biologique selon lequel l'apprentissage dépend du contexte motivationnel ou de saillance. Dans un réseau artificiel conventionnel, le gradient est appliqué uniformément en fonction de l'erreur. Dans Neuraxon, l'apprentissage peut être intensifié ou atténué en fonction de l'état interne ou des signaux externes globaux.
La différence conceptuelle est significative. Dans les réseaux classiques d'apprentissage profond, l'erreur conduit l'apprentissage. Dans Neuraxon, l'erreur peut coexister avec un signal modulatoire contextuel qui modifie la quantité apprise à tout moment donné.
Criticalité auto-organisée et comportement adaptatif
Les réseaux biologiques fonctionnent près d'un régime appelé criticalité auto-organisée, où le système maintient un équilibre entre ordre et chaos. Ce régime permet de la flexibilité sans perte de stabilité.
Neuraxon modélise cette propriété en permettant au réseau d'évoluer vers des états dynamiques intermédiaires dans lesquels de petites perturbations peuvent produire des réorganisations larges sans faire s'effondrer le système.
Dans des modèles tels que le Jeu de la Vie étendu avec la proprioception que l'équipe développe actuellement, le système peut recevoir des signaux externes (environnement) et des signaux internes (son propre état, énergie, collisions précédentes). Si un agent entre en collision à plusieurs reprises avec un obstacle, un accroissement du signal méta peut être généré, analogue à une augmentation de l'excitation. Ce signal augmente temporairement la plasticité, facilitant la réorganisation structurelle.
Ici, le réseau n'apprend pas seulement parce qu'il fait des erreurs. Il apprend parce que l'environnement acquiert une pertinence adaptative. La similarité avec le cerveau reste limitée : Neuraxon ne possède pas de biologie, de métabolisme ou d'expérience subjective. Cependant, il introduit des dimensions dynamiques absentes dans la plupart des réseaux neuronaux artificiels conventionnels, le positionnant comme une approche véritablement novatrice de l'IA inspirée du cerveau sur une infrastructure décentralisée.
La puissance de calcul requise pour exécuter les simulations Neuraxon est fournie par le réseau mondial de mineurs de Qubic grâce à un Preuve d'Utilité de Travail, transformant l'entraînement de l'IA en mécanisme de consensus lui-même.

Références scientifiques
#Azevedo, F. A. C., et al. (2009). Des nombres égaux de cellules neuronales et non neuronales font du cerveau humain un cerveau de primate à échelle isométrique. Journal of Comparative Neurology, 513(5), 532-541. DOI: 10.1002/cne.21974
#Marder, E. (2012). Neuromodulation des circuits neuronaux : Retour vers le futur. Neuron, 76(1), 1-11. DOI: 10.1016/j.neuron.2012.09.010
#Rosenblatt, F. (1958). Le Perceptron : Un modèle probabiliste de stockage et d'organisation de l'information dans le cerveau. Psychological Review, 65(6), 386-408. DOI: 10.1037/h0042519
#Rumelhart, D. E., Hinton, G. E., & Williams, R. J. (1986). Apprendre des représentations en rétro-propageant des erreurs. Nature, 323(6088), 533-536. DOI: 10.1038/323533a0
#Vaswani, A., et al. (2017). L'attention est tout ce dont vous avez besoin. Advances in Neural Information Processing Systems, 30. arXiv: 1706.03762
Images de réseaux cérébraux fournies par : DOI: 10.3389/fnagi.2023.1204134