 L'année dernière, j'étais dehors devant un bureau gouvernemental sous la chaleur, essayant de payer des frais de document via mon application bancaire. L'application a gelé après que l'argent ait été débité. Pas de reçu. Pas de confirmation. Juste une roue qui tourne. Le fonctionnaire a haussé les épaules et m'a dit de « revenir demain ». J'avais l'alerte de débit. Le système n'avait aucun enregistrement. J'étais coincé entre deux vérités. 😐
L'année dernière, j'étais dehors devant un bureau gouvernemental sous la chaleur, essayant de payer des frais de document via mon application bancaire. L'application a gelé après que l'argent ait été débité. Pas de reçu. Pas de confirmation. Juste une roue qui tourne. Le fonctionnaire a haussé les épaules et m'a dit de « revenir demain ». J'avais l'alerte de débit. Le système n'avait aucun enregistrement. J'étais coincé entre deux vérités. 😐
Ce moment semblait petit, mais il a révélé quelque chose de plus grand. L'argent a circulé. Le système n'était pas d'accord. Les données existaient. L'institution ne lui faisait pas confiance. Je ne traitais pas avec un problème technique. Je faisais face à une autorité fragmentée — plusieurs bases de données prétendant être une seule réalité.
Nous parlons de vitesse comme si c'était la solution ultime. Internet plus rapide. Rails de paiement plus rapides. Blockchains plus rapides. Mais ce que j'ai vécu n'était pas un problème de vitesse. C'était un problème de coordination. La main gauche du système ne comprenait pas ce que la main droite avait déjà fait.
L'économie numérique moderne est comme une ville où chaque bâtiment a sa propre horloge. Certaines sont en avance. D'autres sont en retard. Elles prétendent toutes donner l'heure. Aucune d'entre elles ne se synchronise. 🕰️
Si vous zoomez, cette fragmentation explique pourquoi les transactions échouent, pourquoi le règlement prend des jours, et pourquoi les institutions s'appuient encore sur des départements de réconciliation. Les finances ne sont pas lentes parce que les ordinateurs sont lents. Elles sont lentes parce que les bases de données ne s'accordent pas — et aucune couche unique n'a de compréhension contextuelle de ce que les données signifient réellement.
C'est la lentille structurelle que j'ai commencé à utiliser : le véritable goulet d'étranglement n'est pas le débit des transactions ; c'est la coordination sémantique. Les systèmes peuvent déplacer des chiffres rapidement. Ils luttent pour comprendre les relations entre ces chiffres.
Lorsque les gens louent des réseaux comme Ethereum pour leur décentralisation ou Solana pour leur vitesse brute, ils discutent souvent de mesures de performance. Ethereum a été optimisé pour la sécurité et la programmabilité. Solana a été optimisé pour la vitesse d'exécution. Les deux résolvent de réelles contraintes. Mais aucun ne résout directement la fragmentation sémantique — le problème de la cohérence des données contextuelles à travers les couches.
L'écosystème d'Ethereum, par exemple, est puissant mais en couches. L'exécution se produit sur une couche, la mise à l'échelle sur une autre, la disponibilité des données ailleurs. Cela fonctionne, mais la complexité de la coordination croît. Solana atteint un débit impressionnant, mais la haute performance n'égale toujours pas l'intelligence contextuelle. La vitesse sans structure interprétative peut amplifier les erreurs plus rapidement. ⚡
La question plus profonde est l'alignement des incitations. Les validateurs sécurisent les réseaux. Les développeurs construisent des applications. Les utilisateurs génèrent de l'activité. Mais aucune couche structurelle n'assure que les données de transaction sont contextuellement significatives au-delà de l'exécution.
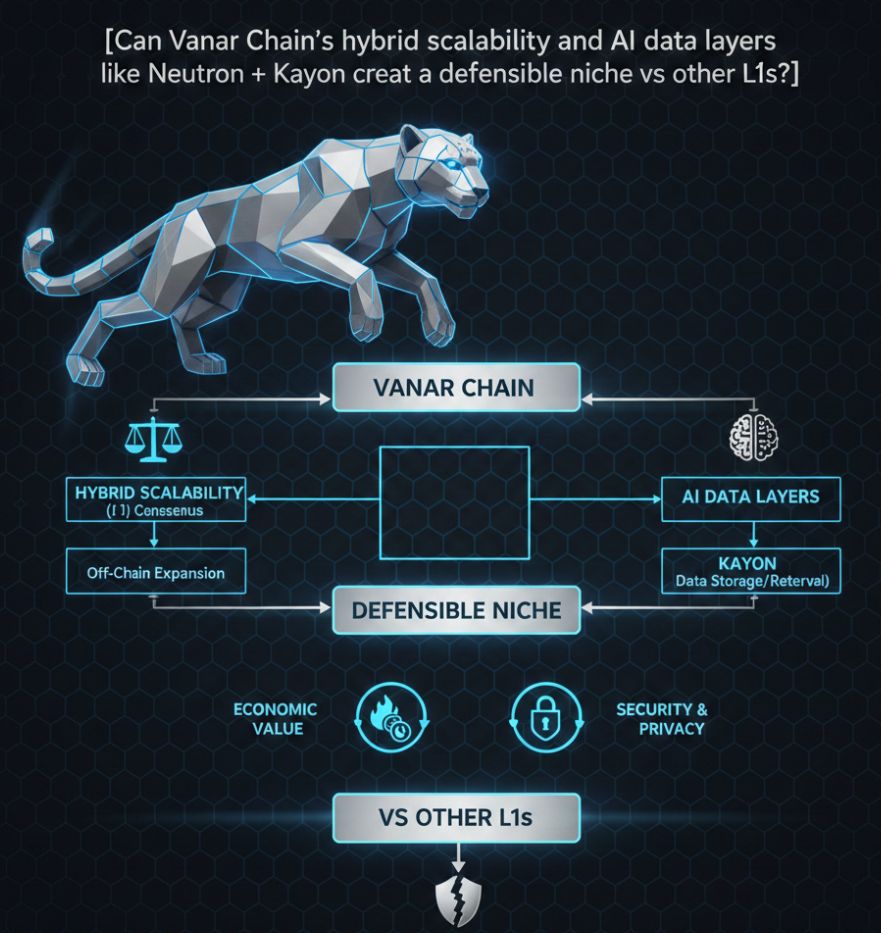
C'est ici que l'architecture de Vanar Chain devient intéressante — non pas parce qu'elle prétend être plus rapide, mais parce qu'elle tente de combiner la scalabilité hybride avec des couches de données pilotées par l'IA comme Neutron et Kayon.
La scalabilité hybride, en termes simples, signifie ne pas forcer une méthode de mise à l'échelle sur toute l'activité. Au lieu de faire en sorte que chaque transaction compete dans la même voie, différentes charges de travail peuvent être distribuées intelligemment. C'est moins comme construire une autoroute plus large et plus comme concevoir des systèmes de circulation qui reconnaissent le type de véhicule et le dirigent en conséquence. 🚦
Mais la scalabilité seule répéterait la même erreur que d'autres réseaux — supposer que le débit résout la fragmentation. Le pivot structurel réside dans les couches de données d'IA natives.
Neutron est positionné comme une couche de mémoire sémantique. Plutôt que de stocker uniquement des données de transaction brutes, elle organise les relations entre les points de données. Kayon fonctionne comme une couche d'intelligence capable d'interagir avec ces données structurées. L'ambition n'est pas simplement d'enregistrer l'activité, mais de l'interpréter.
Pour expliquer cela clairement, imaginez deux systèmes.
Le système B stocke les reçus tout en les catégorisant par type de commerçant, comportement de dépense, schéma temporel et étiquettes contextuelles.
Le système A vous donne des données. Le système B vous donne un sens structuré.
Cette différence est là où la défendabilité peut émerger. 🧠
La plupart des réseaux L1 traitent les données comme un sous-produit des transactions. Vanar tente de traiter les données comme un composant structurel de première classe. Si cela réussit, cela pourrait créer une niche où les applications s'appuient non seulement sur l'exécution mais sur l'intelligence contextuelle intégrée au sein de la chaîne elle-même.
Cela est particulièrement important pour la tokenisation des actifs du monde réel, les cadres d'identité, les économies de jeu et les secteurs fortement réglementés. Ces domaines nécessitent plus que la finalité des transactions. Ils nécessitent la mémoire historique et la continuité interprétative.
Pour plus de clarté, un cadre visuel utile comparerait trois approches architecturales :
Une colonne montrant des chaînes axées sur l'exécution en premier, concentrées sur le débit.
Une colonne montrant des chaînes modulaires séparant l'exécution et la disponibilité des données.
Une colonne montrant une chaîne scalable-hybride avec des couches sémantiques intégrées.
Le tableau mettrait en évidence les différences dans la façon dont chacun gère la persistance du contexte, pas seulement le TPS. Ce visuel est important car il change la métrique d'évaluation de la vitesse à la cohérence structurelle.
Cependant, il existe de réelles tensions.
Il existe également un risque d'adoption. Les développeurs sont habitués aux environnements centrés sur l'exécution. Leur demander de construire avec des couches sémantiques nécessite une maturité des outils et une clarté de documentation. Sans une ergonomie forte pour les développeurs, l'architecture risque de rester sous-utilisée.
La question plus profonde est de savoir si les marchés valorisent suffisamment la cohérence contextuelle pour se déplacer vers de telles architectures. La plupart des capitaux poursuivent encore des mesures de vitesse et de liquidité. Mais l'adoption institutionnelle, en particulier dans les secteurs réglementés, peut exiger des couches interprétatives intégrées plutôt que des outils d'analyse externes. 🏛️
Pourtant, l'intégration est fragile. Les systèmes d'IA évoluent rapidement. Les systèmes blockchain privilégient la stabilité. Les fusionner signifie équilibrer l'adaptabilité avec la rigidité du consensus. Trop de flexibilité affaiblit le déterminisme. Trop de rigidité limite l'intelligence.
La niche, si elle existe, ne sera pas gagnée en prétendant à la supériorité. Elle dépendra de la manière dont les applications réelles commencent à s'appuyer sur la continuité sémantique au niveau de la couche de base plutôt que de la traiter comme un middleware optionnel.
Lorsque mon application bancaire a gelé, le problème n'était pas que la transaction avait échoué. C'était que le système ne pouvait pas concilier le sens à travers les silos. Si les réseaux futurs peuvent intégrer le contexte aux côtés de l'exécution, ils peuvent réduire cette fragmentation.
Mais voici la tension non résolue : si l'intelligence devient intégrée au niveau du protocole, qui gouverne finalement l'interprétation — le code, les validateurs ou les institutions qui en dépendent ? 🤔
@Vanarchain #vanar $VANRY #Vanar