
When people talk about Plasma, they often focus on speed, scalability, and innovation. But behind every smooth transaction and reliable node, there is something very real and very physical — hardware. Plasma Docs does not just talk theory. It clearly shows what it truly takes to run a Plasma node properly.
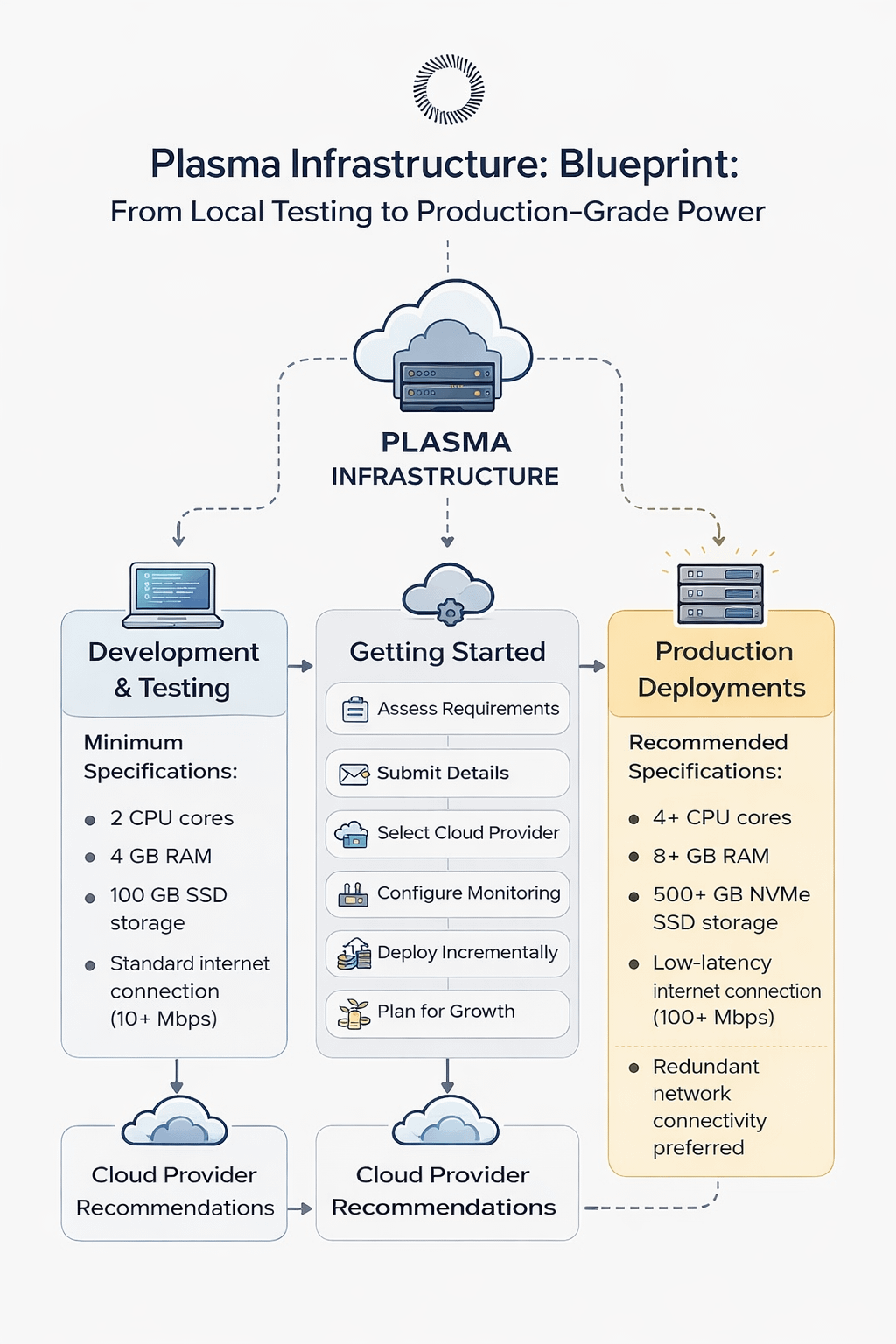
Imagine you are just starting your journey. You want to experiment, test features, maybe run a non-validator node locally. Plasma keeps this stage practical and affordable. For development and testing, you do not need an expensive machine. The minimum specifications are simple and realistic: 2 CPU cores, 4 GB RAM, 100 GB SSD storage, and a standard 10+ Mbps internet connection. This setup allows developers to experiment, prototype, and understand the system without heavy cost pressure. It lowers the barrier of entry. It says, “Start small, learn deeply.”
But Plasma also makes one thing very clear — development is not production.
When we move to production deployments, the mindset changes completely. Now reliability matters. Low latency matters. Uptime guarantees matter. Here, Plasma recommends 4+ CPU cores with high clock speed, 8+ GB RAM, and 500+ GB NVMe SSD storage. Not just any storage — NVMe. That means faster read and write speeds, smoother synchronization, and stronger performance under load. Internet requirements jump to 100+ Mbps with low latency, and redundant connectivity is preferred. Why? Because in production, downtime is not just inconvenience — it is risk.
This clear separation between development and production shows maturity. Plasma is not just saying “run a node.” It is saying “choose the right tier to balance cost, performance, and operational risk.” That mindset is infrastructure-first thinking.
Even more interesting is how Plasma guides users in getting started. The process is structured:
First, assess your requirements. Are you experimenting or running production-grade infrastructure?
Second, submit your details and contact the team before deployment.
Third, choose your cloud provider based on geography and pricing.
Fourth, configure monitoring from day one.
Fifth, deploy incrementally and scale based on real usage.
And finally, plan for growth.
This is not random advice. This is operational discipline.
The cloud recommendations add another layer of clarity. For example, on Google Cloud Platform, development can run on instances like e2-small with 2 vCPUs and 2 GB RAM, or e2-medium with 2 vCPUs and 4 GB RAM. But production shifts to powerful machines like c2-standard-4 or n2-standard-4 with 4 vCPUs and 16 GB RAM. That jump reflects the performance expectations of real-world deployment.
Plasma is still in testnet phase for consensus participation, focusing mainly on non-validator nodes. That tells us something important — this is infrastructure being built carefully, step by step. No shortcuts. No overpromises.
In a space where many projects talk big about decentralization and scalability, Plasma’s hardware documentation quietly shows seriousness. It understands that blockchain performance is not magic. It depends on CPU cores, RAM capacity, SSD speed, and network quality. It depends on monitoring. It depends on redundancy.
Plasma is not just software. It is an ecosystem that respects infrastructure fundamentals.
And maybe that is the real story here — before scaling the world, you must scale responsibly.

