I remember clearly the first time I ran into Mira. I was combing through an error log from an agent that auto wrote reports, and it misquoted a number that looked harmless, yet was enough to skew an entire decision. After a few cycles, I no longer flinch when AI is wrong. I just feel tired, because it always sounds so confident while being wrong.
Maybe that is why Mira made me pause longer than most AI crypto projects. Their focus is not on making the model “smarter,” but on finding a way to produce “evidence” that an output can be verified without relying on a human nod. I think the ambition is timely: more systems want to run autonomously, fewer people want to sit in the human in the loop seat, and the trust gap keeps widening.
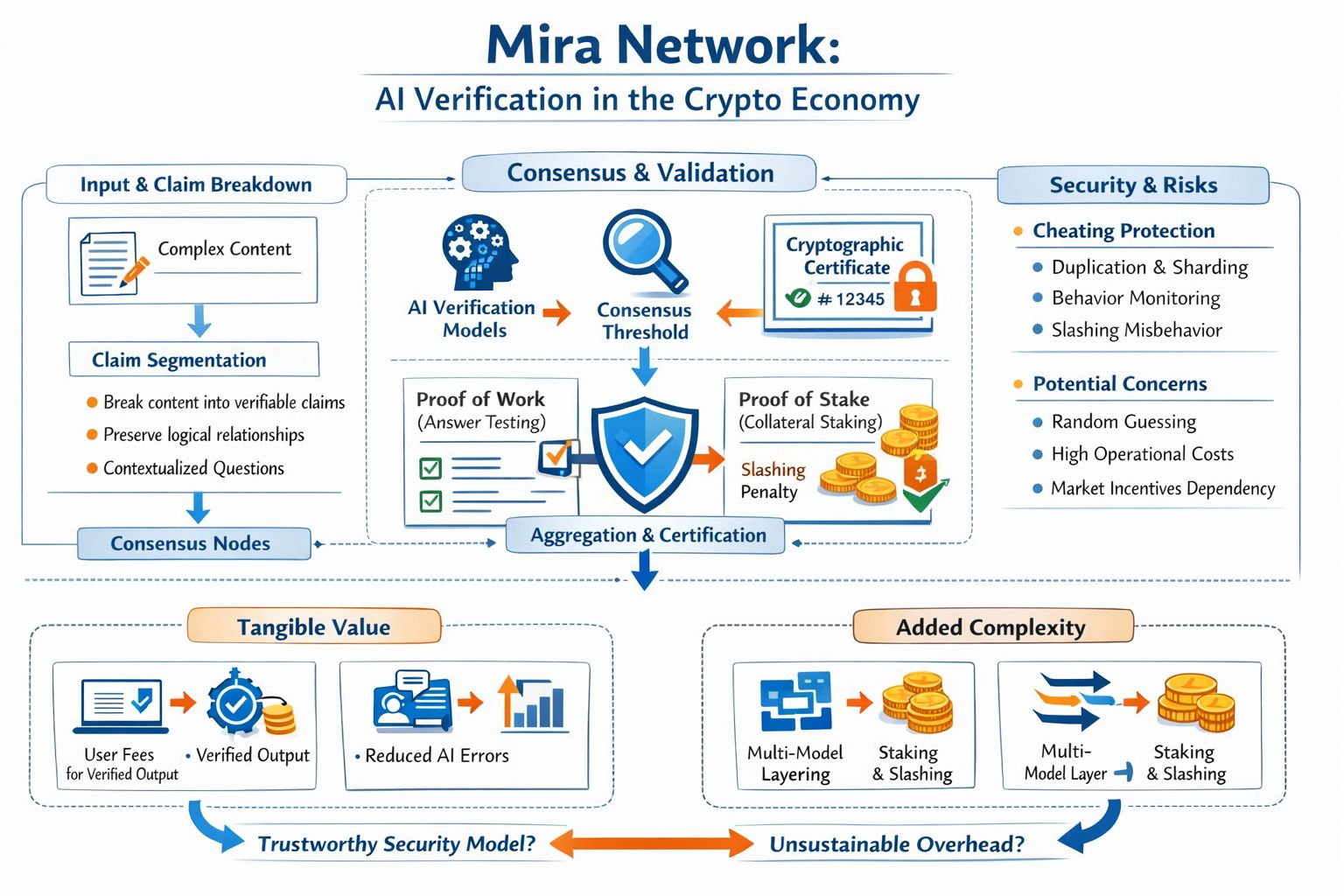
The technical core of Mira, at least from what I read in the whitepaper, starts with something that sounds simple but is actually the hardest part: turning a complex piece of content into multiple independent “claims” that can be verified, while still preserving the logical relationships between them. This is how they try to avoid the situation where each verifying model interprets the same paragraph from a different angle, and everyone is “right” in their own way. Once the content is standardized into questions with clear context, multiple models can answer the same thing, and consensus becomes more meaningful.
What I find interesting is that Mira workflow has a very “blockchain” rhythm, without forcing everything on chain. The user submits what needs to be checked, specifies the knowledge domain and a consensus threshold, for example requiring unanimity or just N out of M. The network distributes the claims to nodes running verifier models, aggregates the results, then issues a cryptographic certificate that records the outcome and even which models agreed for each claim. Honestly, that certificate is the part that makes me less allergic to the word “trustless,” because it gives trust a shape and an audit trail, instead of just a feeling.
Then I immediately return to the question in the title: a new security model, or just added complexity. Ironically, Mira also acknowledges something many projects like to avoid: when you standardize verification into multiple choice questions, the answer space is limited, and random guessing can have a non trivial chance of success. I have seen this in other mechanisms, where the lazy attacker does not need to break the system, only exploit statistics. Mira counters by requiring nodes to stake, and slashing those who deviate from consensus or show signs of answering randomly. It makes sense on paper, but I think the real fight will be about how well they can detect “organized laziness” that is subtle enough to look legitimate, and whether slashing remains a strong deterrent when market incentives rise.
There is a deeper point here that builders will feel immediately: in Mira, security is not just about how much stake exists, but about designing observability for behavior. The whitepaper talks about phases of evolution: early on, carefully selecting nodes; later, using duplication so multiple instances of the same model process the same request to expose cheaters or free riders; and only later moving toward randomized sharding so collusion becomes hard and expensive. I have built distributed systems, and I know “works on paper” is not the same as “works in production.” Similarity metrics for answers, signals of caching, behavioral patterns that look acceptable but quietly avoid real computation, all of that is where operational costs can eat into the benefits. No one expects a layer meant to reduce risk to become a new risk surface if observability is weak or the dispute process is too heavy.
And then I come back to what an older investor always checks: where does real value come from. Mira states plainly that it creates “tangible economic value” by reducing AI errors, and users pay a fee to receive verified outputs, with that fee distributed to participants like node operators and data providers. I like this framing more than unconditional emissions, because at least it points to a service revenue stream. But the test will be brutal: when the market cools, who will keep paying for verification, and will they pay because it measurably reduces product risk, or because token subsidies are masking the cost. When easy rewards disappear, will the mechanism still retain enough good nodes, enough model diversity, enough resistance to manipulation.
The biggest lesson Mira brings back for me is that crypto often confuses “having a mechanism” with “having security.” A mechanism is only an invitation to behavior. Security is what remains after bad behavior has tried every path. I think Mira’s strength is that it names the right problem and designs a process that turns trust into something verifiable through traces, rather than PR. The potential weakness sits in the same place: the more layers you add, content transformation, multi model consensus, staking, slashing, duplication, sharding, the more places there are to optimize sideways, the heavier the operational burden becomes, and the more product discipline you need so real users can actually feel it is “worth paying for". And if one day we truly let AI act autonomously in systems with real consequences, will Mira be the evidence layer that makes me calmer, or just another complexity layer that renames an old doubt.