
I keep thinking about the first time I watched a “fast chain” fall apart in a way that wasn’t dramatic, just annoying. Not an outage. Not a hack. Just that slow, creeping unreliability where one out of every twenty transactions stops feeling deterministic. You resubmit. You change RPCs. You add another retry loop. Your app still “works,” but you can’t trust what users are seeing anymore.
That’s the lens I use for Fogo governance. Not as philosophy. As operations.
Fogo is making a very explicit bet that reliability at market speed is a governance problem as much as it’s a protocol problem. The docs basically admit the quiet part: performance is constrained by the weakest operators, and you can’t reach physical limits if you let under-provisioned validators hang around forever. So they curate the validator set. There’s a stake requirement, but there’s also an approval requirement. Economic security plus operational capability.
That second part is where “governance” stops meaning token votes in the abstract and starts meaning real enforcement.
Because the moment you say “approval,” you’re saying someone can also say “no.” Or “not anymore.”
Fogo’s architecture page is unusually direct about what that social layer is supposed to do: eject validators for harmful MEV behavior, remove persistently underperforming nodes, prevent behaviors that destabilize consensus or block propagation. You can read that as paternalistic. You can also read it as a chain that’s tired of pretending users should tolerate tail latency because decentralization is pure.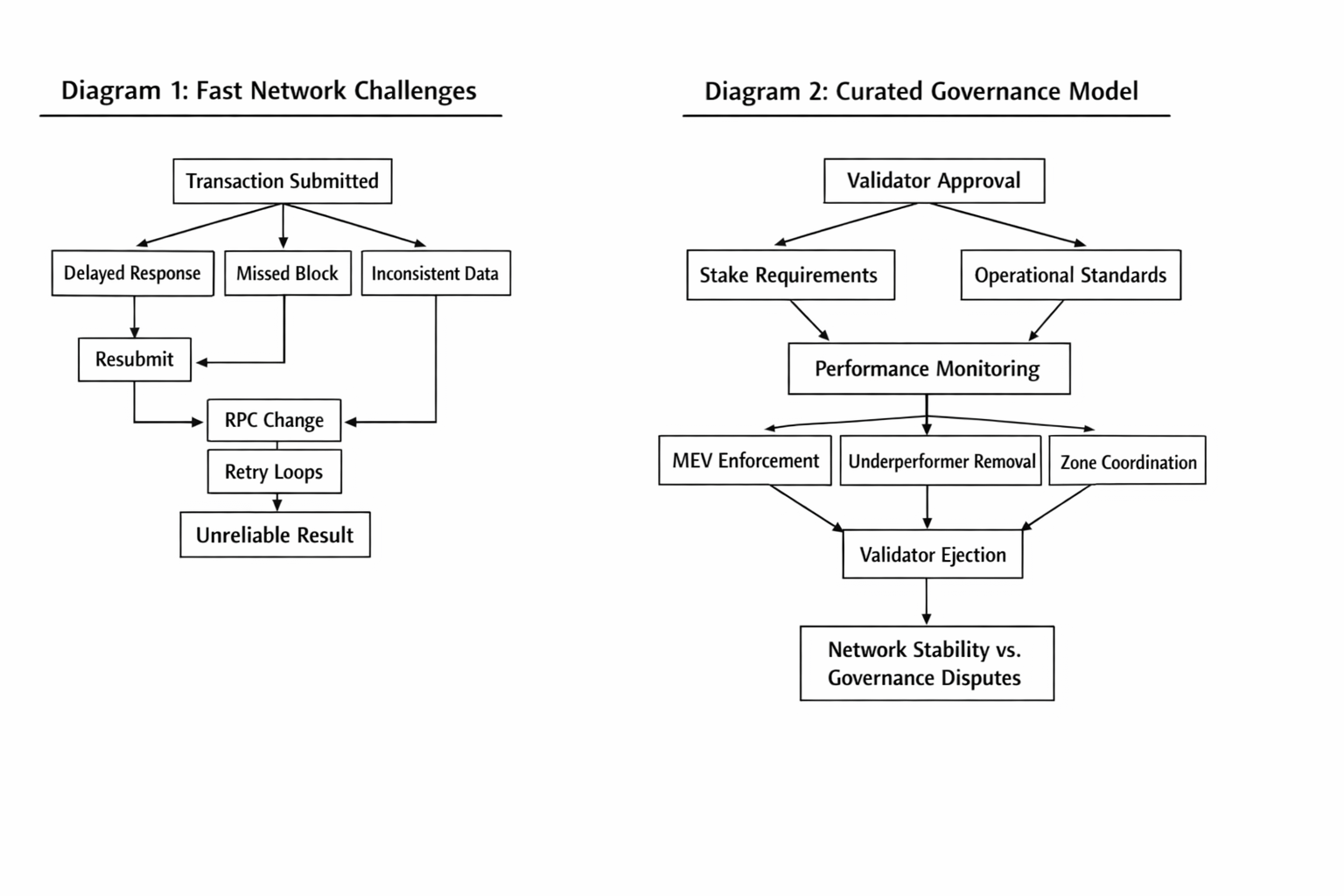
On most networks, you measure averages and then you get surprised by the tails. The median confirmation might be fine, but the 95th percentile makes you look like you lied to your users. Fogo is built around minimizing that tail by controlling the variables that create it: validator hardware variance, networking variance, client variance.
They standardize the client too. Single canonical client based on Firedancer, initially Frankendancer, and the network economics are designed so slower setups miss blocks and lose revenue. That’s not just a performance brag. Operationally, it’s a reliability move: fewer weird edge cases caused by divergent client behavior.
Then there’s multi-local consensus. The part that sounds like pure latency optimization, but it’s also governance wearing a different hat. Validators co-locate in “zones” to get very low inter-validator latency, with the docs calling out block times under 100ms as a practical target when the zone is tight enough. Community docs put the headline numbers right on the page: 40 millisecond block times and about 1.3 second finality.
If you’ve ever run a trading flow, you know why that matters. It’s not about “fast.” It’s about predictability. When confirmations come in a tight band, your risk checks, your quote logic, your UI state, everything is simpler. You stop building a whole parallel product that exists only to handle ambiguity.
Zone selection happens through on-chain voting, and validators need supermajority consensus on the future epoch location, with advance coordination so everyone has time to stand up infrastructure in the next zone. That’s governance too. It’s not “should we upgrade the protocol.” It’s “where is the chain going to physically live next epoch.”
That’s a reliability lever. And also a new failure mode.
Because the more your performance depends on coordinated colocation, the more your operations depend on coordination not breaking down. If validators can’t agree on a zone. If they agree late. If a subset drags its feet on deployment hardening. You can end up with a network that’s theoretically designed for resilience but practically stuck in logistics.
Fogo’s answer is basically: we would rather solve those logistics than pretend geography doesn’t exist.
Backpack’s write-up frames it similarly: co-location in performance-optimized zones reduces communication delays, and rotation spreads jurisdictional exposure over time. That sounds like decentralization by schedule. Reliability by planning.
And then you hit the tradeoff that’s hard to sanitize.
Curated validators mean someone decides who qualifies. Community docs describe early validators being hand-selected, with standards defined by Kairos Research monitoring network health and performance. Messari’s report on the testnet launch even puts a number on the “approved validator” idea: a curated set in the neighborhood of 19 to 30 validators, explicitly to reduce harmful MEV and keep the network efficient.
That is not a neutral design choice.
If you’re shipping an app, it can feel great. Fewer flaky nodes. Less performance drag from hobbyist setups. More consistent block propagation. That’s the sales pitch, and it’s not imaginary.
If you’re thinking about credible neutrality, it’s uncomfortable. “Social layer enforcement” is just a clean phrase for governance power that can be misused, or at least disputed.
There’s also the governance surface area that’s easy to miss until you’re living with it: enforcement events become part of your reliability model.
On an open validator set, an underperformer can be annoying, but it’s usually just noise in the distribution. On a curated set, removing an operator is a deliberate action. That can be good. It can also be disruptive in its own way: stake reallocation, leader schedule changes, operator churn, people arguing about whether an ejection was “for performance” or “for politics.”
And because Fogo is optimizing for deterministic execution in trading-heavy environments, those disruptions matter more. You can tolerate a little chaos in a social network chain. In a chain that wants to behave like a venue, chaos is a tax.
The more I read Fogo’s governance model, the more it feels like they’re trying to import the idea of an SRE runbook into protocol land. Not by adding more code. By narrowing who is allowed to run the most critical infrastructure, and by making “network health” an explicit governance objective instead of an emergent property.
That probably does improve reliability for users who just want trades to clear in a tight window. Community docs literally describe it as “proven reliability from day one,” and tie that to validator selection based on uptime, accuracy, throughput.
But it also means your trust boundary shifts.
You’re not only trusting cryptography and incentives. You’re trusting the governance process that defines standards, monitors compliance, and decides when enforcement is justified.
I don’t think that makes it “bad.” I think it makes it legible. Most chains already have informal governance that decides what’s acceptable. They just pretend it’s not governance.
Fogo is saying: yes, it is. And we’re going to use it to keep the network from getting dragged down by the slowest link.
The unresolved part for me is how that governance posture behaves under real stress. Not stress like “the chain got popular.” Stress like: a validator ejection right before a major market event, competing interests around zone rotation, a disagreement about what counts as “harmful MEV,” the kind of fight where every side can claim they’re defending reliability.
Because if governance is the reliability engine, governance is also the thing that can stall the engine when the road gets messy.
Άρθρο
Fogo: How Governance Works and What It Means for Reliability
Αποποίηση ευθυνών: Περιλαμβάνει γνώμες τρίτων. Δεν είναι οικονομική συμβουλή. Ενδέχεται να περιλαμβάνει χορηγούμενο περιεχόμενο. Δείτε τους Όρους και προϋποθέσεις.

FOGO
0.03015
+7.37%