Most people describe Fabric as “robots on a blockchain” or “a marketplace for robot skills.” That framing misses what the project is really trying to solve. The hard problem in general purpose robotics isn’t getting a robot to act. It’s getting everyone else to accept the robot’s claim about what happened especially when money, safety, regulation, or liability is involved.
Fabric looks to me like an attempt to build a credibility engine for robot work. Not credibility in the social sense credibility in the enforceable sense. The ledger is where claims are recorded and contested. The token, $ROBO, is the bond that makes those claims costly to fake. In that model, the “product” isn’t robots. It’s a way to price and enforce responsibility across humans, machines, and the software modules that connect them.
Here’s why I think that’s the right lens.
First: the token design reads like collateral architecture, not like “gas for robots.” Fabric’s own materials set a fixed total supply at 10,000,000,000 $ROBO. The distribution is heavily tilted toward long horizon ecosystem and governance buckets: Ecosystem & Community 29.7%, Investors 24.3%, Team & Advisors 20.0%, Foundation Reserve 18.0%, Community Airdrops 5.0%, Liquidity Provisioning 2.5%, Public Sale 0.5%. That last part is easy to overlook, but it’s revealing: only 3.0% combined for public sale and liquidity provisioning. If the project’s core goal were maximum day-one token velocity, you’d typically see a larger portion structured to float quickly. Fabric’s structure makes more sense if the network expects large portions to be locked as stake posted to back claims, participation, and governance decisions because a credibility system needs bonding capacity more than it needs constant trading.
Second: Fabric doesn’t pretend that physical-world tasks can always be “proven” in the cryptographic sense. That’s a subtle but important honesty. In real environments, the claims that matter are often messy: “the floor was cleaned properly,” “the valve was tightened to spec,” “the patient was monitored continuously.” Those aren’t the kind of statements you can universally reduce to perfect onchain proofs. Fabric’s mechanism design leans instead on contestability and economics: people can challenge outcomes, and the protocol can penalize bad claims if they’re caught.
The most concrete sign is that Fabric writes down an explicit deterrence condition for cheating: it models a bond requirement with the inequality B > 2g/p, where B is the required bond, g is the gain from cheating, and p is the probability of detection. That one line tells you the project is not building a “truth machine.” It’s building a system where truth is expensive to fake because the expected value of fraud can be driven below zero. And it tries to keep that incentive layer stable: it also bounds how quickly token emissions can change, setting a maximum 5% per epoch (δ = 0.05). It even bounds early participation bonuses in a tight range (φmax between 1.2 and 1.5), which is basically a priced premium for being early without letting incentives become unbounded. Those are the choices you make when you want a long lived enforcement economy rather than a short lived growth hack.
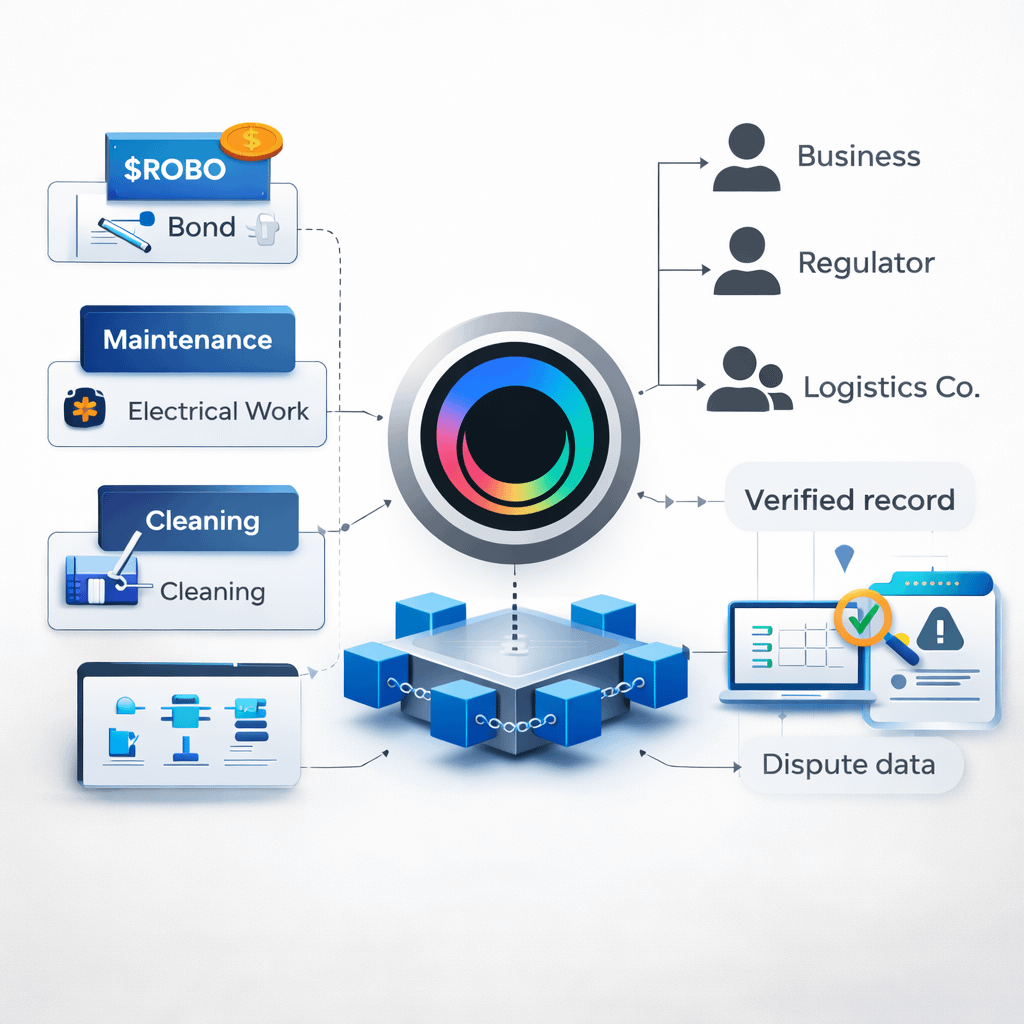
Third: “skill chips” aren’t interesting because they’re modular. They’re interesting because they make liability modular. The usual pitch for robot modularity is “app store for skills.” But the scarier reality of general-purpose robots is that when something goes wrong, responsibility tends to smear across everyone involved hardware vendor, skill developer, operator, verifier, coordinator. That ambiguity is what makes regulated adoption slow and expensive.
A module based world can draw sharper lines: which module produced the behavior, which version was deployed, who signed off on it, who is staking behind it, who profits if it’s used, and who eats the cost if it fails. Fabric’s own scenario modeling nudges toward exactly these regulated contexts. In the electrician example, Fabric cites a union journeyman electrician wage of $63.50/hour in Los Angeles, and training requirements of 4–5 years, quantified as 8,000 10,000 hours. Then it introduces scenario numbers clearly not guarantees suggesting ~23,000 electrician robots could cover California electrical work at ~$3–$12/hour, with ~73,000 jobs displaced and ~700 annual injuries/fatalities potentially reduced. I don’t treat those scenario outputs as “facts about the future”; I treat them as a signal about what Fabric thinks the real market is: work where compliance, documentation, incident handling, and responsibility trails dominate the economics. That’s exactly where an enforceable credibility layer could matter most.
A fair pushback is that none of this makes robots safe. A ledger doesn’t prevent a robot from slipping, misgrasping, or misreading a scene. And a malicious actor can game sensors and logs. I agree with that critique if Fabric is judged as a safety guarantee. But Fabric doesn’t have to be a safety guarantee to be valuable. It has to make unsafe operation and dishonest reporting harder to sustain economically. The difference is subtle: instead of preventing every bad outcome, it aims to make the system converge toward better behavior by increasing the cost of bad behavior and rewarding those who can consistently back their claims.
So if you want to evaluate Fabric in a grounded way, the question isn’t “how many robots are on the network” or “how fast is the chain.” The question is whether the credibility engine actually forms.
That translates into measurable things Fabric should be able to show (ideally in its own explorer or dashboards):
How much $ROBO is actually bonded behind work and behind module publishers (not just held).
Dispute behavior: challenges per 1,000 tasks, what percentage are upheld, median time to resolution, and total/average slashing amounts over time.
Module accountability: adoption curves by skill-chip version, plus failure or incident rates by version, and whether bad versions get economically quarantined (stake withdrawn, usage drops, reputation declines).
Governance stability: whether key parameters like the 5% maximum emission change constraint hold up under stress, rather than being rewritten when the first real controversy hits.
If those numbers start to exist and move in the right direction more bonded stake behind higher stakes work, disputes that resolve credibly, real penalties when actors misbehave then Fabric becomes something most robotics ecosystems still lack: a neutral substrate where machine work can be coordinated and, crucially, held to account across organizations.
What I’d watch next is simple: whether Fabric publishes (or enables others to verify) the core credibility metrics above, and whether real participants are willing to lock meaningful $ROBO behind claims. If the token stays mostly liquid and the evidence/dispute layer stays thin, then the project drifts back into “robot narrative with a token.” If bonding deepens and disputes become legible and enforceable, Fabric starts to look like a real liability layer for autonomous labor.